
Descripción
SQL Server 2016 incluye una variedad de mejoras en el optimizador de consultas. Algunas de estas han existido desde las primeras versiones previas, mientras que otras fueron añadidas después. ¡Esta es una oportunidad de discutir, probar y validar el comportamiento y beneficios de estos cambios!
Los Detalles
Lo que sigue es un paseo característica por característica, con algunas demostraciones, explicaciones y las implicaciones de cada cambio basado en mis pruebas y análisis. Algunos de estos cambios son muy directos y no requieren pruebas reales, pero la discusión aún vale el tiempo y el esfuerzo 🙂
Garantía de Nivel de Compatibilidad
Cualquier base de datos puede tener su modo de compatibilidad establecido a una versión previa (soportada) de SQL Server. Esto permite algún nivel de compatibilidad hacia atrás entre una nueva versión de SQL Server y una antigua. Haciendo esto, podemos facilitar una actualización más suave entre versiones, sabiendo que no estamos cortando el cordón inmediatamente a todas las características descontinuadas o alteradas. A pesar de estar modo de compatibilidad, usted aún puede tomar ventaja de las nuevas características de SQL Server, siempre y cuando no estén en conflicto directo con una característica del nivel de compatibilidad antiguo que está usando.
Podemos validar el modo de compatibilidad actual para cualquiera (o todas) de las bases de datos en un servidor vía la vista de sistema sys.databases:
|
1 2 3 4 |
SELECT databases.name, databases.compatibility_level FROM sys.databases; |
El resultado es una lista de bases de datos y su modo de compatibilidad asociado. Esta es una manera rápida de verificar si alguna de las bases de datos tiene un nivel de compatibilidad antiguo o no están en una versión deseada:
|
1 2 3 4 5 |
SELECT databases.name, databases.compatibility_level FROM sys.databases WHERE databases.compatibility_level <= 100 |
Correr esto en mi máquina local retorna una sola base de datos que está corriendo bajo el modo de compatibilidad de SQL Server 2008R2:

El modo de compatibilidad puede ser actualizado usando un comando ALTER DATABASE, como este:
|
1 2 |
ALTER DATABASE AdventureWorks2014 SET COMPATIBILITY_LEVEL = 130; |
Este T-SQL ajustará AdventureWorks2014 para usar la compatibilidad con SQL Server 2016.
Previamente a SQL Server 2016, correr una base de datos en modo de compatibilidad a una versión anterior no tenía garantías con respecto al comportamiento del optimizador de consultas y los panes de ejecución que generaba. Comenzando en SQL Server 2016, Microsoft garantiza que las nuevas mejoras del optimizador de consultas estarán solamente disponibles en el nivel de compatibilidad 130. SI usted está corriendo una base de datos en un servidor SQL Server 2016, pero está en un modo de compatibilidad anterior, entonces no se aplicarán las características nuevas del optimizador cuando las consultas sean ejecutadas en su base de datos.
Esto significa que, si usted actualiza un servidor desde SQL Server 2014 y 2016 y deja una base de datos en nivel de compatibilidad 120, entonces los planes de consultas permanecerán de la misma forma que era en la versión antigua. Las nuevas características del optimizador estarán disponibles cuando la base de datos sea alterada para utilizar un nivel de compatibilidad de 130.
Cambios en el Nivel de Compatibilidad 130
¿Qué cambios hay cuando usted se cambia al nivel de compatibilidad 130? Aquí está una breve lista con un poco de detalles:
Los algoritmos hash MD2, MD4, MD5, SHA y SHA1 ya no están soportados. Use SHA2_256 o SHA2_512 en su lugar.
Una tabla dad ahora puede tener 10,000 claves foráneas o restricciones referenciales. El límite solía ser 253. ¡Eso es MUCHAS claves foráneas!
La toma de muestras de estadísticas es ahora multi-hilo. Todas las versiones previas manejaban sólo un hilo.
La marca de seguimiento 2371 está ahora encendida por defecto, mientras que en todas las versiones anteriores estaba apagada. Esta marca de seguimiento cambia cómo las estadísticas de actualización automática determinan cuándo actualizar y cómo hacerlo. Sin eso habilitado, las estadísticas se actualizarían cuando el 20% de una tabla cambia. Para tablas más pequeñas, esto es generalmente aceptable. Para tablas más grandes, esto se vuelve insostenible. La marca de seguimiento hace que las estadísticas sean auto-actualizadas para un % menor de cambios, comenzando en aproximadamente 25k filas, lo cual es ideal para tablas muy grandes. En SQL Server 2016, en adición a que la marca de seguimiento está encendida, las mejoras han sido hechas a las tablas de muestra (inclinándose hacia los datos nuevos). Finalmente, la auto-actualización de estadísticas ya no bloqueará las consultas cuando estén corriendo.
• El modo de lotes es usado por el optimizador para más operaciones en SQL Server 2016 que en versiones previas. Este modo permite lotes de filas sean procesados por una CPU, en lugar de una por una. Esto mejora grandemente el desempeño en conjuntos grandes de datos. Previo a SQL Server 2016, el modo de lotes podría ser usado con índices de almacén de columnas, pero su uso era limitado. En la nueva versión, el modo de lotes puede ser usado para:
Ordenamientos usando índices de almacén de columnas
Agregación de funciones de ventana
Múltiples operadores distintos en índices de almacén de columnas
Las consultas con planes seriales, o aquellas debajo el máximo grado de paralelismo = 1.
La estimación cardinal está mejorada, más allá de las mejoras encontradas en SQL Server 2014.
Las consultas en tablas OLTP en memoria pueden utilizar planes de ejecución paralelos.
Las consultas INSERT INTO…SELECT pueden ser multi-hilos o beneficiarse de los planes de ejecución paralelos.
Estos cambios son casi exclusivamente mejoras – cada uno mejorando cómo los planes de ejecución o estadísticas son manejados, o añadiendo paralelismo en los planes que previamente no podían beneficiarse de eso. Si usted está usando algoritmos hash antiguos que están descontinuados en SQL Server 2016, asegúrese de transitar a los más nuevos que son soportados previamente a actualizar su nivel de compatibilidad.
Operador de Integridad Referencial
Las claves foráneas proveen integridad referencial entre tablas, asegurando que las operaciones de escritura creen columnas huérfanas de aquellas relacionadas. Cuando sea que una clave foránea es escrita, una revisión debe ocurrir en la tabla referenciada para asegurar la operación de escritura que no viola la definición de clave foránea.
En previas versiones de SQL Server, esto significa que los escaneos o búsquedas debería ser realizadas contra la tabla padre para validar la operación de escritura, previa a ser enviada. Las operaciones específicas requeridas para validar las claves foráneas serían explícitamente mostradas en el plan de ejecución para todas las tablas referenciadas. En SQL Server, la Revisión de Referencias de Claves Foráneas es presentada para manejar todas las revisiones de integridad referencial en un solo paso. La documentación de Microsoft indica que este cambio simplificará grandemente los planes de ejecución y reducirá el tiempo de compilación para el plan de ejecución.
¿Qué quiere decir esto para las claves foráneas existentes y las consultas que escriben en las columnas relacionadas? Tomemos unos minutos para correr algunas pruebas y encontrar exactamente cómo este nuevo operador se desempeña y se compara con lo que experimentamos en versiones previas.
Comenzaremos con algunas actualizaciones simples en Production.Product (en AdventureWorks) bajo el modo de compatibilidad 120, el cual indica que usaremos las reglas del optimizador tomadas de SQL Server 2014:
|
1 2 3 4 5 6 7 8 9 |
UPDATE Production.Product SET WeightUnitMeasureCode = 'LB', SizeUnitMeasureCode = 'LB' WHERE Product.ProductID = 919; UPDATE Production.Product SET WeightUnitMeasureCode = 'G', SizeUnitMeasureCode = 'CM ' WHERE Product.ProductID = 919 |
Cada una de estas actualizaciones está afectando dos columnas con claves foráneas, las cuales están enlazadas a Production.UnitMeasure. Como resultado, cuando las actualizamos, es necesario validar la integridad referencia para cada valor añadido aquí:
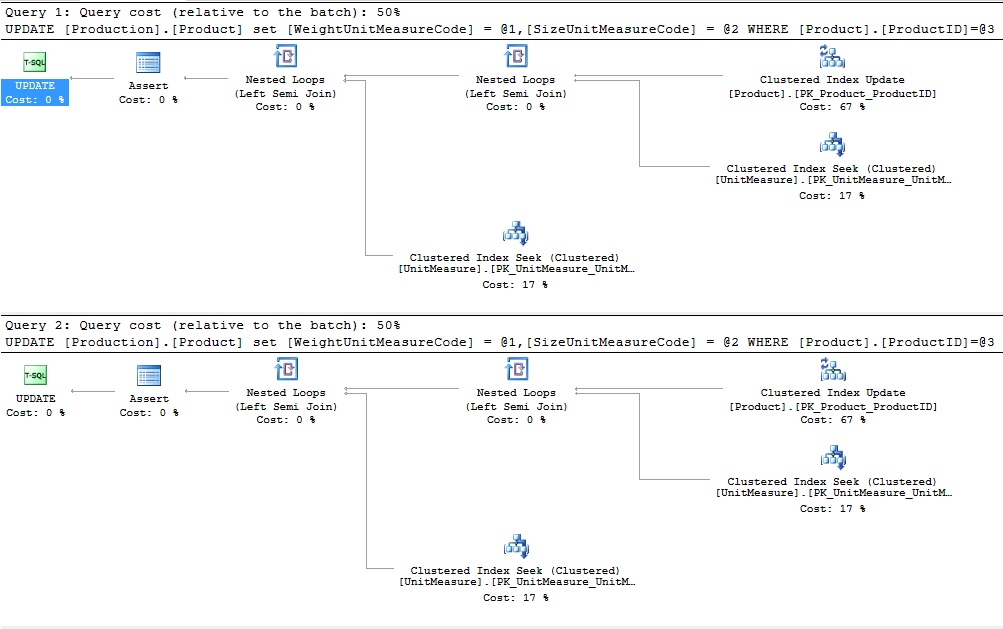
Cada uno de estos planes muestra que cada actualización individual es revisada en busca de un valor válido en la tabla padre. Note que en la primera sentencia de actualización usamos el mismo valor dos veces. El sentido común nos diría que sólo debería ser necesario validar esto una vez, pero el optimizador revisará Production.UnitMeasure dos veces de todas maneras. Estas revisiones toman la firma de las dos búsquedas de índices agrupados vistas en cada uno de los planes de ejecución de arriba.
Con SQL Server 2016, se nos promete un nuevo operador que hará las revisiones como estas más eficientes y mejor documentadas. El último es un punto útil, ya que, en consultas grandes, puede que no sea inmediatamente obvio qué operadores se refieren a la revisión de integridad referencial y no a la consulta activa en sí misma.
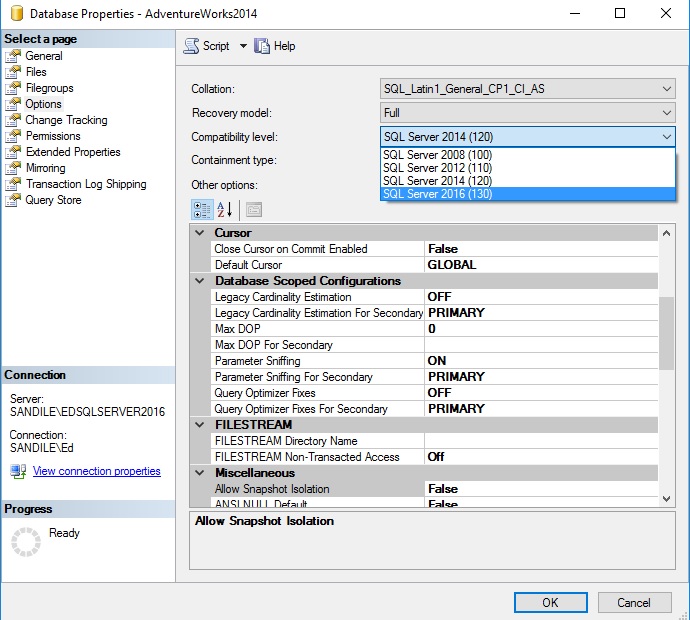
Actualicemos nuestro modo de compatibilidad a 130, lo cual no permitirá el uso de las nuevas mejoras del optimizador:
Ahora que podemos hacer uso del nuevo operador, probémoslo con una de nuestras actualizaciones de arriba:
|
1 2 3 4 |
UPDATE Production.Product SET WeightUnitMeasureCode = 'LB', SizeUnitMeasureCode = 'LB' WHERE Product.ProductID = 919; |
El plan de ejecución resultante es el mismo de antes:
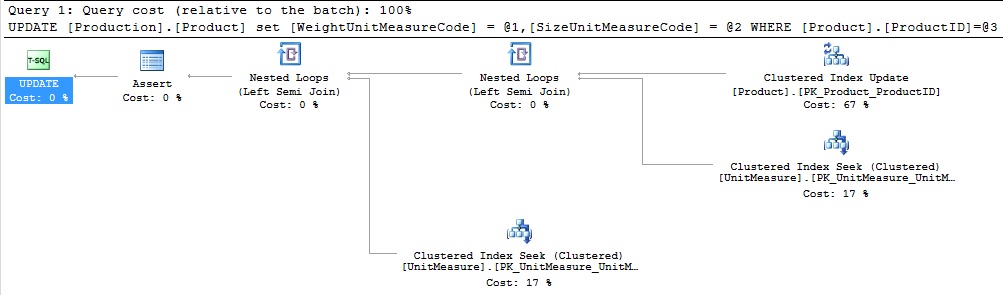
Bueno, eso pasó sin ninguna novedad. Esperábamos un nuevo y brillante operador de plan y en lugar de eso obtuvimos exactamente los mismos resultados que antes. Probemos unas pocas otras consultas y veamos qué cambios podemos descubrir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
INSERT INTO Production.Product ( Name ,ProductNumber ,MakeFlag ,FinishedGoodsFlag ,Color ,SafetyStockLevel ,ReorderPoint ,StandardCost ,ListPrice ,Size ,SizeUnitMeasureCode ,WeightUnitMeasureCode ,Weight ,DaysToManufacture ,ProductLine ,Class ,Style ,ProductSubcategoryID ,ProductModelID ,SellStartDate ,SellEndDate ,DiscontinuedDate ,rowguid ,ModifiedDate ) SELECT 'Wing Nut', 'WN-1234', 1, 0, 'Silver', 1000, 500, 1.00, 1.50, NULL, 'G', 'CM', NULL, 0, NULL, NULL, NULL, NULL, NULL, CAST(CURRENT_TIMESTAMP AS DATE), NULL, NULL, NEWID(), CURRENT_TIMESTAMP; DELETE FROM Production.Product WHERE Name = 'Wing Nut'; INSERT INTO production.UnitMeasure (UnitMeasureCode, Name, ModifiedDate) SELECT 'WOW', 'The wow factor!', CURRENT_TIMESTAMP; DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'WOW'; |
Si las actualizaciones no parecen obtener los que deseamos, deberíamos también intentar algunas inserciones y eliminaciones. Correr las consultas de arriba añadirá una fila a Production.Product y Production.UnitMeasure, respectivamente, y luego eliminará esas filas. Los planes de ejecución resultantes para las consultas de arriba son como siguen:
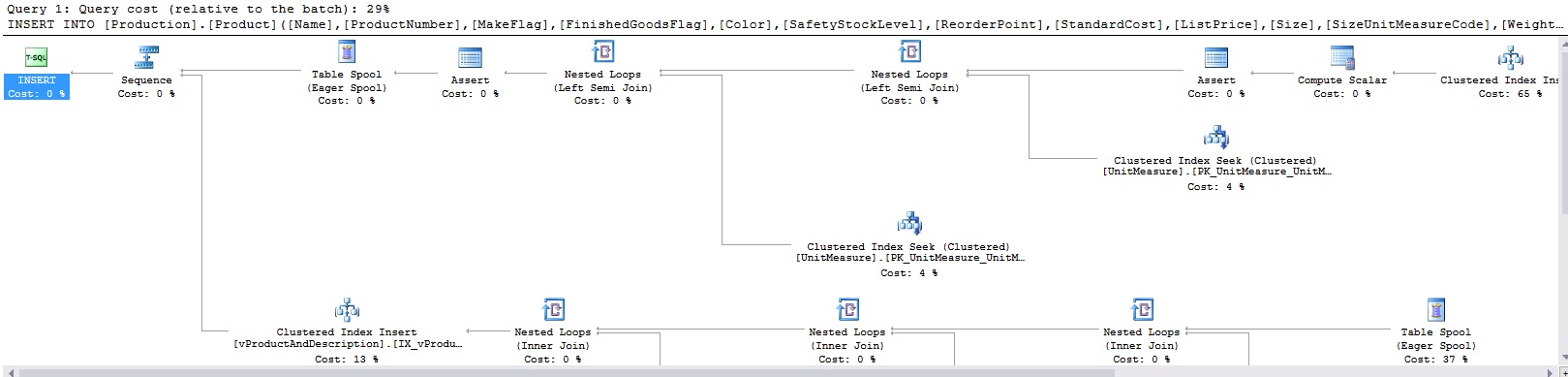

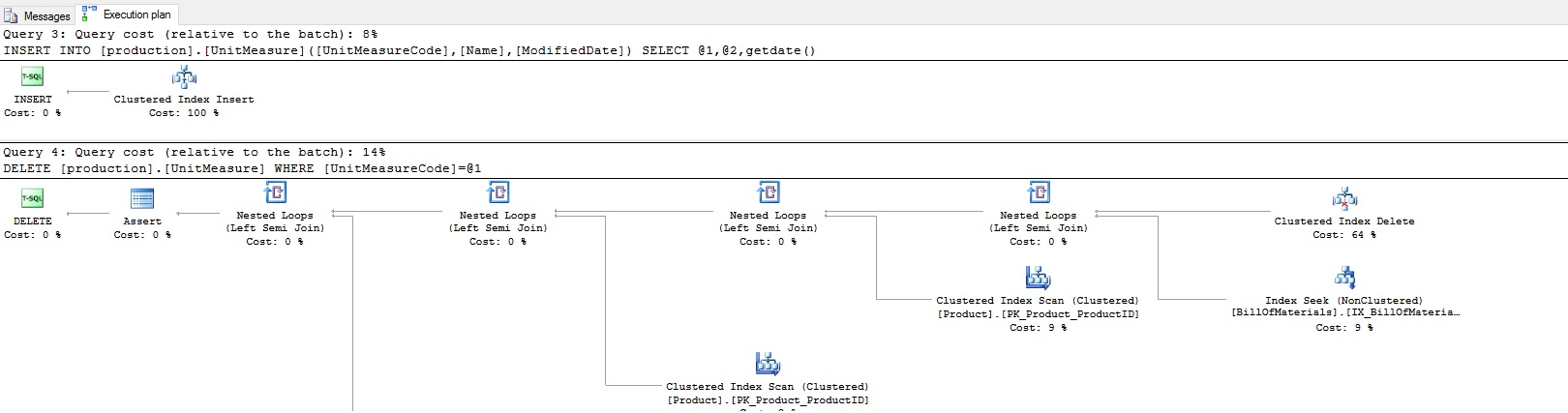
No me molesté en incluir planes enteros en imágenes individuales. Es claro por el número de tablas siendo consultas arriba que no estamos obteniendo un operador de clave foránea claro, y en su lugar estaos obteniendo los mismos planes que siempre obtuvimos previamente. ¿Qué esperamos ver aquí? La siguiente imagen es de una entrada del blog de MSDN:
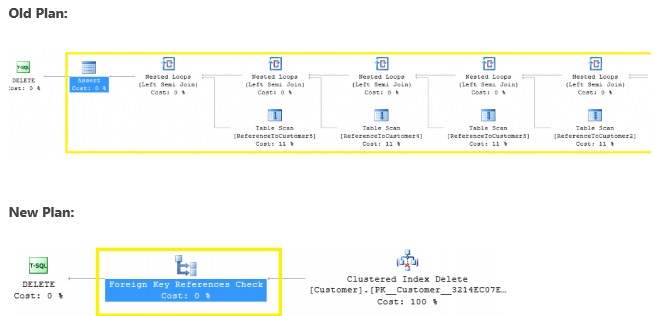
Esto muestra claramente que los muchos escaneos/búsquedas de revisiones de integridad referencial son reemplazados con un solo operador simplificado que presumiblemente supera a la metodología previa. El siguiente T-SQL es lo que ellos usaban para probar este nuevo operador:
|
1 2 3 4 5 6 |
CREATE TABLE Customer(Id INT PRIMARY KEY, CustomerName NVARCHAR(128)); CREATE TABLE ReferenceToCustomer1(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); CREATE TABLE ReferenceToCustomer2(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); CREATE TABLE ReferenceToCustomer3(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); DELETE Customer WHERE Id = 1; |
El plan de ejecución resultante que recibo es el mismo que el antiguo plan mostrado arriba. Dado que no es claro por qué no puedo obtener los resultados deseados, he dejado una nota en el artículo para obtener más información acerca de por qué esto no está funcionando. Si hay alguna característica o ajuste que estoy omitiendo, o si este operador no está aún disponible para el actual lanzamiento RTM, entonces estará bien tener esa información para trabajar con ella.
Si una actualización de este nuevo operador es recibida, ya sea vía una entrada en MSDN o algún canal, actualizaré este artículo con los detalles.
El artículo MSDN referenciado arriba puede ser encontrado aquí.
Tuve grandes esperanzas en este cambio, siendo que los planes de ejecución actuales solían forzar la integridad referencial, tendían a ser algo poco inteligentes. Sin embargo, para estar seguro, instalé una instancia separada de SQL Server 2016 en otra computadora, y corrí las mismas consultas de arriba. Los resultados fueron los mismos en que no pude hacer uso del nuevo operador de plan. Es posible que esta característica esté disponible en una revisión futura de SQL Server 2016, así que estaré atento, y si esta característica se vuelve usable, estaré seguro de documentarla y probarla como loco 🙂
Cambios de la Revisión/Paquete de Servicios del Optimizador de Consultas
En versiones previas de SQL Server, cuando una revisión o una actualización acumulativa eran lanzadas, cualquier mejora del optimizador de consultas otorgadas por esa actualización no entrarían en efecto inmediatamente. En lugar de eso, era necesario encender la marca de seguimiento 4199, la que luego habilitaría cualquier nueva característica del optimizador desde cualquier actualización instalada a SQL Server.
Esta metodología por defecto funcionaba, pero era un poco ofuscada y no era claro para los administradores que este era el comportamiento con el que se suponía que deberían trabajar. A menudo, los parches serían instalados, la marca de seguimiento no encendida, y por tanto los cambios en el optimizador no fueron realizados hasta que ocurrió una actualización mayor. Esto es típicamente aceptable, ya que no deberíamos cambiar el comportamiento del optimizador a menos que exista un problema que necesita una solución, o si estamos actualizando a una nueva versión mayor.
Comenzando con SQL Server 2016, todas las mejoras del optimizador de consultas estarán enlazadas directamente al nivel de compatibilidad. Si una base de datos es actualizada a un nivel de compatibilidad 130, entonces todas las optimizaciones previas serán implementadas. Una base de datos que no está en modo de compatibilidad 130 no recibirá las mejoras en el optimizador desde SQL Server 2016. La marca de seguimiento 4199 será reservada para encender cualquier cambio en el optimizador introducido en parches subsecuentes, mientras que aún se corre la versión actual de SQL Server. Si usted fuera a actualizar a alguna versión futura de SQL Server, quizá SQL Server 2018, entonces cambiar entre el hipotético nivel de compatibilidad 140 habilitaría retroactivamente todas las mejoras del optimizador introducidas vía revisiones y paquetes de servicios a SQL Server 2016.
Las marcas de seguimiento específicas solían ser usadas previamente a la marca de seguimiento 4199 para habilitar las mejoras del optimizador vía una revisión individual. Esta funcionalidad estaba hecha para escenarios donde un error de programación distinto está en necesidad de un parche, y la mejora necesaria como parte de esa actualización. Una variedad de marcas de seguimiento desde 4101 – 4135 (no inclusivo) manejaban estas revisiones específicas, las cuales no se utilizan después de que la marca de seguimiento 4199 fue creada.
Conclusión
Cada versión de SQL Server viene con su parte de cambios en el optimizador de consultas. Algunos están emparejados con nuevas características, mientras que otros están hechos para mejorar la funcionalidad existente. Al menos una de las nuevas características, el operador de integridad referencial de llave foránea, no está aún disponible, pero con suerte hará su aparición en una revisión pronta a lanzarse.
La garantía del modo de compatibilidad provee significativamente más control sobre cómo las nuevas características afectan al optimizador y asegura que el proceso de actualización pueda ser mejor diseñado. El conocimiento garantizado de cómo las características se comportarán provee un nivel de confianza que no estaba fácilmente disponible en versiones previas de SQL Server.
¡Manténgase atento para más! No es raro para Microsoft lanzar mejoras o documentación adicionales en paquetes de servicios posteriores. ¡Estas pueden ser soluciones de errores inocuos o posiblemente nuevos DMVs, mejoras del optimizador o características adicionales!
Referencias y Lecturas Posteriores
Entrada del blog MSDN con una lista de cambios en el optimizador en SQL Server 2016:
Adiciones al Optimizador de Consultas en SQL Server 2016
Entrada del blog del Motor de Base de Datos de SQL Server, incluyendo detalles de los cambios más recientes desde CTP3:
Qué es nuevo para OLTP en memoria en SQL Server 2016 desde CTP3
Niveles de Compatibilidad (Cómo Trabajan/Cómo Usarlos)::
Nivel de Compatibilidad ALTER DATABASE
MSDN blog entry about trace flag 2371:
Changes to automatic update statistics in SQL Server – traceflag 2371
Detalles acerca de la marca de seguimiento 4199 y cambios en el optimizador de consultas, incluyendo revisiones específicas con sus marcas de seguimiento individuales:
Revisión del optimizador de SQL Server, marca de seguimiento 4199, modelo de servicio

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017