
¿Qué es un GUID?
Esta herramienta denominada GUID es un tipo de datos binario de SQL Server de 16 bytes que es globalmente único en tablas, bases de datos y servidores. El término GUID significa Globally Unique Identifier y se usa indistintamente con UNIQUEIDENTIFIER.
Para poder crear un GUID en SQL Server, la función NEWID () se utiliza como se muestra a continuación:
|
1 |
SELECT NEWID() |
Se debe ejecutar la línea anterior de SQL varias veces y podrá ver un valor diferente cada vez. Esto se debe a que la función NEWID() genera un valor único cada vez que se lo ejecuta.
Para declarar a una variable del tipo GUID, la palabra clave utilizada es UNIQUEIDENTIFIER como se menciona en el script a continuación:
|
1 2 3 4 |
DECLARE @UNI UNIQUEIDENTIFIER SET @UNI = NEWID() SELECT @UNI |
Debemos recordar que, como se mencionó anteriormente, los valores GUID son únicos en todas las tablas, bases de datos y servidores. Por ello, los GUID pueden considerarse claves primarias globales. Entonces, las claves primarias locales se utilizan para identificar de forma exclusiva los registros dentro de una tabla. Es importante mencionar que, por otro lado, los GUID se pueden usar para identificar de forma exclusiva los registros en tablas, bases de datos y servidores.
El problema que se resuelve por medio de GUID
Deberemos considerar y definir qué problemas enfrentamos si tenemos registros redundantes dentro de las tablas en diferentes bases de datos y de qué manera podría el GUID poder resolver estos problemas.
Ejecute el siguiente script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE DATABASE EngDB GO USE EngDB GO CREATE TABLE EnglishStudents ( Id INT PRIMARY KEY IDENTITY, StudentName VARCHAR (50) ) GO INSERT INTO EnglishStudents VALUES ('Shane') INSERT INTO EnglishStudents VALUES ('Jonny') |
En el script anterior, creamos una base de datos llamada “EngDB”. Posteriormente creamos una tabla “EnglishStudents” donde el requerimiento solicitado es que dentro de esta base de datos. La tabla tiene dos columnas: Id y StudentName. La columna Id es la columna de clave principal y la configuramos para que se incremente automáticamente usando Identidad como restricción. Finalmente, insertamos dos registros para estudiantes llamados “Shane” y “Jonny” en la tabla “Estudiantes de inglés”.
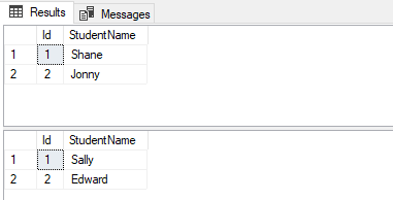
Ahora, si nosotros seleccionamos todos los registros de la tabla “EnglishStudents”, debería tener y ver el siguiente resultado:
| Id | StudentName |
| 1 | Shane |
| 2 | Jonny |
Ahora, requerimos crear otra base de datos “MathDB”, entonces se debe crear una tabla “MathStudents” en la base de datos y adicionalmente insertar algunos registros en la tabla. Ejecute el siguiente script para hacerlo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE DATABASE MathDB GO USE MathDB GO CREATE TABLE MathStudents ( Id INT PRIMARY KEY IDENTITY, StudentName VARCHAR (50) ) GO INSERT INTO MathStudents VALUES ('Sally') INSERT INTO MathStudents VALUES ('Edward') |
La tabla MathStudents de MathDB debe tener los siguientes registros.
| Id | StudentName |
| 1 | Sally |
| 2 | Edward |
Recuerde que ahora, si selecciona todos los registros de la tabla EnglishStudents de la tabla EngDB y MathStudents de MathDB, se podrá observar y verificar que los registros de ambas tablas tendrán los mismos valores para las columnas de clave principal Id. ejecute el siguiente script para ver este resultado:
|
1 2 |
SELECT * FROM EngDB.dbo.EnglishStudents SELECT * FROM MathDB.dbo.MathStudents |
Verá el siguiente resultado en SQL Server Management Studio

En este caso se puede verificar que los registros de estudiantes de diferentes tablas que existen en dos bases de datos diferentes tienen el mismo valor para la columna Id. Este es el comportamiento predeterminado de SQL Server.
Seguidamente, ahora crearemos una nueva tabla “Estudiante” que contiene la unión de todos los registros de la tabla MathStudents y la tabla EnglishStudents. Para es te fin deberemos ejecutar el siguiente script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE EngDB GO CREATE TABLE Students ( Id INT PRIMARY KEY, StudentName NVARCHAR (50) ) GO INSERT INTO Students SELECT * FROM EngDB.dbo.EnglishStudents UNION ALL SELECT * FROM MathDB.dbo.MathStudents |
En el script anterior, habíamos creado una nueva tabla “Estudiantes” en la EngDB. Esta tabla contiene columnas Id y StudentName.
Si nosotros intentamos ejecutar el script anterior, se verá un error:

La causa principal de este error se debe a que tanto la tabla MathStudents como EnglishStudents tienen los mismos valores para la columna Id, ya que también es la columna de clave principal para la tabla Students recién creada. Por lo tanto, es muy relevante el ver que cuando intentamos insertar la unión de los registros de las tablas MathStudents e EnglishStudents, se producirá el error “Violación de la restricción PRIMARY KEY”. Ejecute el siguiente script para ver lo que realmente estamos tratando de insertar en la tabla Alumnos.
|
1 2 3 |
SELECT * FROM EngDB.dbo.EnglishStudents UNION ALL SELECT * FROM MathDB.dbo.MathStudents |

Sin embargo, la pregunta muy consistente al tema es: ¿qué sucede si queremos que los registros tengan valores únicos en varias bases de datos? Por ejemplo, si el caso amerita queremos que la columna Id de la tabla EnglishStudents y la tabla MathStudents tengan valores únicos, incluso si pertenecen a diferentes bases de datos. Por esta razón es que es cuando necesitamos usar el tipo de datos GUID.
Usted entonces puede ver que los estudiantes Shane y Sally tienen Ids de 1, mientras que Jonny y Edward tienen Ids de 2. Esto provoca la violación de la restricción de clave principal para la tabla de Estudiantes.
Solución con GUID
Ahora, veamos cómo se puede usar el GUID para resolver este problema
Deberemos efectuar la creación de una tabla EngStudents1 dentro de EngDB, pero esta vez cambiamos el tipo de datos de la columna Id de INT a UNIQUEIDENTIFIER. Es importante el poder identificar qué para establecer un valor predeterminado para la columna, utilizaremos la palabra clave predeterminada y estableceremos el valor predeterminado como el valor devuelto por la función “NEWID()”.
De esta forma podremos lograr que esto garantizará que cada vez que se inserte un nuevo registro en la tabla EngStudents1, de forma predeterminada, la función NEWID () genere un valor único para la columna Id. Por esta circunstancia, al insertar los registros, simplemente tenemos que especificar “predeterminado” como valor para la primera columna. Al efectuar esta operación, insertará un valor único predeterminado en la columna Id. Ejecute el siguiente script para crear la tabla EngStudents1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE EngDB GO CREATE TABLE EnglishStudents1 ( Id UNIQUEIDENTIFIER PRIMARY KEY default NEWID(), StudentName VARCHAR (50) ) GO INSERT INTO EnglishStudents1 VALUES (default,'Shane') INSERT INTO EnglishStudents1 VALUES (default,'Jonny') |
Ahora, si selecciona todos los registros de la tabla EnglishStudents1, obtendrá un resultado similar a este:
| Id | StudentName |
| 4B900A74-E2D9-4837-B9A4-9E828752716E | Jonny |
| AEDC617C-D035-4213-B55A-DAE5CDFCA366 | Shane |
Nota: Es muy relevante verificar que sus valores para la columna Id serán diferentes de los que se muestran en la tabla anterior, porque se generan aleatoriamente sobre la marcha. Sin embargo, deberían ser globalmente únicos.
Del mismo modo, usted deberá crear otra tabla MathStudents1 en la base de datos MathDB. Luego de ello, ejecute el siguiente script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE MathDB GO CREATE TABLE MathStudents1 ( Id UNIQUEIDENTIFIER PRIMARY KEY default NEWID(), StudentName VARCHAR (50) ) GO INSERT INTO MathStudents1 VALUES (default,'Sally') INSERT INTO MathStudents1 VALUES (default,'Edward') |
Nuevamente, si intenta recuperar todos los registros de la tabla MathStudents1 de la base de datos MathDB, verá resultados similares al siguiente:
| Id | StudentName |
| 69121893-3AFC-4F92-85F3-40BB5E7C7E29 | Sally |
| CB77CCE6-C2CB-471B-BDD4-5DAC8C93B756 | Edward |
Debemos considerar que en la actualidad tenemos valores únicos a nivel mundial en las columnas Id de las tablas EnglishStudents1 y MathStudents1. Creemos una nueva tabla llamada Student1s y, tal como lo hicimos antes, intentemos insertar la unión de los registros de EnglishStudents1 y MathStudents1. Es uy importante observar que en esta ocasión Esta vez veremos que no habrá un error de “Violación de la restricción PRIMARY KEY”, ya que los valores en la columna Id de EnglishStudents1 y MathStudents1 son únicos en las bases de datos EngDB y MathDB.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE EngDB GO CREATE TABLE Students1 ( Id UNIQUEIDENTIFIER PRIMARY KEY, StudentName NVARCHAR (50) ) GO INSERT INTO Students1 SELECT * FROM EngDB.dbo.EnglishStudents1 UNION ALL SELECT * FROM MathDB.dbo.MathStudents1 |
Es importante indicar que se puede ver en el script anterior que el tipo de la columna Id es UNIQUEIDENTIFIER. Y que podrá ejecutar el script anterior e intente recuperar todos los registros de la tabla Students1 y debería ver resultados similares a los siguientes:
| Id | StudentName |
| 69121893-3AFC-4F92-85F3-40BB5E7C7E29 | Sally |
| CB77CCE6-C2CB-471B-BDD4-5DAC8C93B756 | Edward |
| 4B900A74-E2D9-4837-B9A4-9E828752716E | Jonny |
| AEDC617C-D035-4213-B55A-DAE5CDFCA366 | Shane |
Puede ver que usando GUID, podemos insertar una unión de registros de dos bases de datos diferentes en una nueva tabla sin ningún error de “Violación de la restricción de PRIMARY KEY”.
Referencias
Otros grandes artículos de Ben
| Diferencia entre identidad y secuencia en SQL Server |
| ¿Cuál es la diferencia entre los índices agrupados y no agrupados en SQL Server? |
| Comprender el tipo de datos GUID en SQL Server |

Ver todas las entradas de Ben Richardson
- Cómo usar las funciones de Windows en SQL Server - December 16, 2019
- Como comprender el tipo de datos GUID en SQL Server - September 30, 2019
- Cómo utilizar las funciones integradas de SQL Server y crear funciones escalares definidas por el usuario - September 30, 2019