

En este artículo se va a cubrir la cláusula PARTITION BY de SQL y en particular, la diferencia con GROUP BY en una instrucción select. También vamos a explorar varios casos del uso de SQL PARTITION BY.
Utilizaremos el SQL PARTITION BY para poder dividir el conjunto de resultados en particiones y así poder realizar cálculos en cada subconjunto de datos particionados.
Preparación de datos de muestra
Empecemos creando una tabla de pedidos en una base de datos de ejemplo SQLShackDemo e inserte los registros para escribir más consultas.
|
1 2 3 4 5 6 7 8 9 10 |
Use SQLShackDemo Go CREATE TABLE [dbo].[Orders] ( [orderid] INT, [Orderdate] DATE, [CustomerName] VARCHAR(100), [Customercity] VARCHAR(100), [Orderamount] MONEY ) |
Vamos a utilizar el ApexSQL Generate para poder insertar datos de muestra en este artículo. Tiene que hacer clic derecho en la tabla de pedidos y generar datos de prueba.

Esto Lanzara el ApexSQL Generate. Ahora generé un script para insertar datos en la tabla de pedidos. Después ejecute este script para insertar 100 registros en la tabla Pedidos.
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO INSERT [dbo].[Orders] VALUES (216090, CAST(N'1826-12-19' AS Date), N'Edward', N'Phoenix', 4713.8900) GO INSERT [dbo].[Orders] VALUES (508220, CAST(N'1826-12-09' AS Date), N'Aria', N'San Francisco', 9832.7200) GO … |
Una vez que ya estén ejecutadas las instrucciones de inserción, podemos ver los datos en la tabla Órdenes en la imagen a continuación.

Utilizaremos la cláusula SQL GROUP BY para poder agrupar los resultados por columna especificada y a continuación utilizaremos funciones agregadas como Avg( ), Min(), Max() para poder calcular los valores requeridos.
Sintaxis de la función Agrupar por
|
1 2 3 4 |
SELECT expression, aggregate function () FROM tables WHERE conditions GROUP BY expression |
Supongamos que queremos encontrar los siguientes valores en la tabla Órdenes:
- Valor mínimo de pedido en una ciudad
- Valor máximo de pedido en una ciudad
- Valor medio de pedido en una ciudad
Ejecute la siguiente consulta con la cláusula GROUP BY para poder calcular estos valores.
|
1 2 3 4 5 6 |
SELECT Customercity, AVG(Orderamount) AS AvgOrderAmount, MIN(OrderAmount) AS MinOrderAmount, SUM(Orderamount) TotalOrderAmount FROM [dbo].[Orders] GROUP BY Customercity; |
En la captura de pantalla que tenemos a continuación, podemos ver los valores promedio, mínimo y máximo agrupados por CustomerCity.

En este momento, queremos agregar también la columna CustomerName y OrderAmount en la salida. Agreguemos estas columnas en la instrucción select y ejecutemos el siguiente código.
|
1 2 3 4 5 6 |
SELECT Customercity, CustomerName ,OrderAmount, AVG(Orderamount) AS AvgOrderAmount, MIN(OrderAmount) AS MinOrderAmount, SUM(Orderamount) TotalOrderAmount FROM [dbo].[Orders] GROUP BY Customercity; |
Una vez que ya ejecutemos esta consulta, recibiremos un mensaje de error. En la cláusula SQL GROUP BY, podemos utilizar una columna en la instrucción select, si a su vez se utiliza en la cláusula Group by. No permite ninguna columna en la cláusula select que no sea parte de la cláusula GROUP BY.

Podemos utilizar la cláusula PARTITION BY de SQL para poder resolver este problema. Vamos a explorarlo más a fondo en la siguiente sección.
SQL PARTITION BY
Podemos utilizar la cláusula SQL PARTITION BY con la cláusula OVER para poder especificar la columna en la que necesitamos efectuar la agregación. En el ejemplo anterior, utilizamos Agrupar por, con la columna CustomerCity y calculamos los valores promedio, mínimo y máximo.
Ahora vuelva a ejecutar este escenario con la cláusula SQL PARTITION BY utilizando la siguiente consulta.
|
1 2 3 4 5 |
SELECT Customercity, AVG(Orderamount) OVER(PARTITION BY Customercity) AS AvgOrderAmount, MIN(OrderAmount) OVER(PARTITION BY Customercity) AS MinOrderAmount, SUM(Orderamount) OVER(PARTITION BY Customercity) TotalOrderAmount FROM [dbo].[Orders]; |
En la salida, vamos a obtener los valores agregados similares a una cláusula GROUP By . Usted puede notar una diferencia en la salida del PARTITION BY y de salida de la cláusula de GROUP BY de SQL.

Group By | SQL PARTITION BY |
Obtiene un número limitado de registro usando la sentencia Group By | Se obtiene todos los registros en una table usando la sentencia PARTITION BY. |
Retorna una fila por grupo en el conjunto de resultados. Por ejemplo, se obtiene un resultado por cada grupo de CustomerCity en la sentencia GROUP BY. | Provee columnas sumarizadas con cada registro de la columna especificada Tenos 15 registros de la tabla de Órdenes. En la salida de la consulta del SQL PARTITION BY, también tenemos 15 filas con el valor Mínimo, Máximo y promedio. |
En el ejemplo anterior, recibimos un mensaje de error si intentamos agregar una columna que no es parte de la cláusula GROUP BY.
Podemos ahora agregar las columnas requeridas en una instrucción select con la cláusula SQL PARTITION BY. Entonces añadamos las columnas CustomerName y OrderAmout y a continuación ejecutar la siguiente consulta.
|
1 2 3 4 5 6 7 |
SELECT Customercity, CustomerName, OrderAmount, AVG(Orderamount) OVER(PARTITION BY Customercity) AS AvgOrderAmount, MIN(OrderAmount) OVER(PARTITION BY Customercity) AS MinOrderAmount, SUM(Orderamount) OVER(PARTITION BY Customercity) TotalOrderAmount FROM [dbo].[Orders]; |
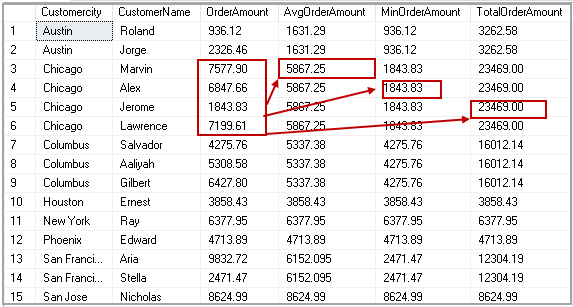
Obtenemos las columnas CustomerName y OrderAmount junto con la salida de la función agregada. A su vez obtenemos todas las filas disponibles en la tabla Pedidos.

En la captura de pantalla que se muestra a continuación, usted puede realizar agregaciones (Promedio , Mínimo y Máx.) para CustomerCity Chicago. Y así puede proporcionar valores en las columnas respectivas.

De la misma manera, podemos utilizar otras funciones agregadas, como por ejemplo el recuento, para poder averiguar el número total de pedidos en una ciudad en particular con la cláusula SQL PARTITION BY.
|
1 2 3 4 5 6 7 8 |
SELECT Customercity, CustomerName, OrderAmount, COUNT(OrderID) OVER(PARTITION BY Customercity) AS CountOfOrders, AVG(Orderamount) OVER(PARTITION BY Customercity) AS AvgOrderAmount, MIN(OrderAmount) OVER(PARTITION BY Customercity) AS MinOrderAmount, SUM(Orderamount) OVER(PARTITION BY Customercity) TotalOrderAmount FROM [dbo].[Orders]; |
Con esto podemos ver los recuentos de pedidos para una ciudad en particular. Como por ejemplo, tenemos dos órdenes de la ciudad de Austin por lo tanto; nos muestra el valor 2 en la columna CountofOrders.

Cláusula PARTITION BY con ROW_ NUMBER ()
Podemos utilizar la cláusula SQL PARTITION BY con la función ROW_ NUMBER ( ) para así poder obtener un número de fila de cada fila. Ahora definimos los siguientes parámetros para usar ROW_NUMBER con la cláusula SQL PARTITION BY.
- PARTITION BY columna: En este ejemplo, queremos particionar datos en la columna CustomerCity
- ORDER BY columna: En la columna ORDER BY, establecemos una columna o condición que define el número de fila. En este ejemplo, nosotros queremos ordenar los datos en la columna OrderAmount
|
1 2 3 4 5 6 7 8 9 10 |
SELECT Customercity, CustomerName, ROW_NUMBER() OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC) AS "Row Number", OrderAmount, COUNT(OrderID) OVER(PARTITION BY Customercity) AS CountOfOrders, AVG(Orderamount) OVER(PARTITION BY Customercity) AS AvgOrderAmount, MIN(OrderAmount) OVER(PARTITION BY Customercity) AS MinOrderAmount, SUM(Orderamount) OVER(PARTITION BY Customercity) TotalOrderAmount FROM [dbo].[Orders]; |
En la captura de pantalla que tenemos a continuación, vemos CustomerCity Chicago , en el cual tenemos la fila número 1 para el pedido con la cantidad más alta 7577.90, este proporciona el número de fila con OrderAmount descendente.

PARTITION BY cláusula con valor total acumulado
Supongamos que queremos obtener un total acumulativo para los pedidos en una partición. El total acumulado debe ser de la fila actual y la siguiente fila de la partición.

Como por ejemplo, en la ciudad de Chicago, tenemos cuatro pedidos.
CustomerCity | CustomerName | Rank | OrderAmount | Cumulative Total Rows | Cumulative Total |
Chicago | Marvin | 1 | 7577.9 | Rank 1 +2 | 14777.51 |
Chicago | Lawrence | 2 | 7199.61 | Rank 2+3 | 14047.21 |
Chicago | Alex | 3 | 6847.66 | Rank 3+4 | 8691.49 |
Chicago | Jerome | 4 | 1843.83 | Rank 4 | 1843.83 |
En la siguiente consulta, emplearemos la cláusula ROWS especificada para poder seleccionar la fila actual (utilizando CURRENT ROW) y la siguiente fila (utilizando 1 FOLLOWING). Además, calcula la suma en esas filas utilizando sum (Orderamount) con una partición en CustomerCity (utilizando OVER (PARTITION BY Customercity ORDER BY OrderAmount DESC).
|
1 2 3 4 5 6 7 |
SELECT Customercity, CustomerName, OrderAmount, ROW_NUMBER() OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC) AS "Row Number", CONVERT(VARCHAR(20), SUM(orderamount) OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING), 1) AS CumulativeTotal, |

De la misma manera, podemos calcular el promedio acumulativo utilizando la siguiente consulta con la cláusula SQL PARTITION BY.
|
1 2 3 4 5 6 7 |
SELECT Customercity, CustomerName, OrderAmount, ROW_NUMBER() OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC) AS "Row Number", CONVERT(VARCHAR(20), AVG(orderamount) OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING), 1) AS CumulativeAVG |

PRECEDENTES SIN LÍMITES DE FILAS con la cláusula PARTITION BY
Podemos utilizar PRECEDENTES SIN LÍMITES DE FILAS con la cláusula PARTITION BY de SQL para poder seleccionar una fila en una partición antes de la fila actual y la fila de mayor valor después de la fila actual.
En la siguiente tabla, podemos apreciar la fila 1; la cual no tiene ninguna fila con un valor alto en esta partición. Por lo tanto, el valor promedio acumulativo es el mismo que para la fila 1 OrderAmount.
Para Row2, Se va a buscar la fila con valor actual (7.199,61) y el valor más alto de la fila 1 (7.577,9). Este va a calcular el promedio de estas dos cantidades.
Para la fila 3, va a buscar el valor actual (6847.66) y un valor de cantidad mayor que este valor que es 7199.61 y 7577.90. este va a calcular el promedio de estos y los retornos.
CustomerCity | CustomerName | Rank | OrderAmount | Cumulative Average Rows | Cumulative Average |
Chicago | Marvin | 1 | 7577.9 | Rank 1 | 7577.90 |
Chicago | Lawrence | 2 | 7199.61 | Rank 1+2 | 7388.76 |
Chicago | Alex | 3 | 6847.66 | Rank 1+2+3 | 7208.39 |
Chicago | Jerome | 4 | 1843.83 | Rank 1+2+3+4 | 5867.25 |
Ahora ejecute la siguiente consulta para obtener este resultado con nuestros datos de muestra.
|
1 2 3 4 5 6 7 8 |
SELECT Customercity, CustomerName, OrderAmount, ROW_NUMBER() OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC) AS "Row Number", CONVERT(VARCHAR(20), AVG(orderamount) OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC ROWS UNBOUNDED PRECEDING), 1) AS CumulativeAvg FROM [dbo].[Orders]; |

Conclusión
En este artículo, exploramos la cláusula SQL PARTIION BY y su comparación con la cláusula GROUP BY. A su vez aprendimos su uso con algunos ejemplos. Espero que lo haya encontrado útil este artículo y no dude en hacer cualquier pregunta en los comentarios a continuación.
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


He is the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups. Based on his contribution to the SQL Server community, he has been recognized with various awards including the prestigious “Best author of the year" continuously in 2020 and 2021 at SQLShack.
Raj is always interested in new challenges so if you need consulting help on any subject covered in his writings, he can be reached at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- INSERTAR EN SELECCIONAR la instrucción del resumen y ejemplos - November 5, 2019
- Descripción general de la cláusula PARTITION BY de SQL - November 4, 2019
- Funciones y formatos de SQL Convert Date - October 10, 2019