
Introducción
Hace un año más o menos, estaba trabajando en un proyecto que se trataba de cargas diarias de datos (desde varios grupos de administración de activos dentro de la empresa) al repositorio de datos SQL Server principal. Cada grupocompletó y publicó sus propias figuras diarias dentro de sus propios Libros de Excel. Estos libros de Excel fueron colocados en un directorio común y luego cargados a la base de datos SQL Server Corporativa. Demos un vistazo a cómo esto puede ser logrado. Vamos a crear un paquete que procesará todas hojas de cálculo dentro del directorio dado.Iniciando
Para nuestra discusión actual, veremos dos libros de Excel. Esté seguro de que el proceso funciona para cualquier número de libros. La captura de pantalla abajo muestra la hoja financial1 para el libro financial1.xlsx.

Nuestra siguiente captura de pantalla muestra la hoja de cálculo financial1 para el libro financial2.xlsx.

En resumen, estaremos lidiando con:
| Nombre de libro | Nombre de hoja de cálculo |
| Financial1.xlsx | Financial1 |
| Financial2.xlsx | Financial1 |
El punto importante es que los libros en sí mismos pueden tener diferentes nombres, pero DE TODAS MANERAS las hojas relevantes tienen que tener todas el mismo nombre.
Iniciamos creando un nuevo paquete de Integration Services desntro de SQL Server Integration Services (desde ahora nos referiremos a eso como SSIS).

Damos a nuestro nuevo proyecto un nombre (ver abajo).

Nos encontramos ahora en nuestra superficie de trabajo.

Por favor note que he renombrado nuestro paquete “LoadExcelWorkbooks” (ver parte superior derecha).
Como en el pasado, ahora creo una conexión a mi Base de Datos SQLShackFinancial (ver abajo).

Haciendo clic derecho en cualquier lugar en la caja de administración de conexión, creo una Conexión de destino OLEDB a mi Base de Datos SQL Server (ver abajo). También añado un “Execute SQL Task” a la superficie de trabajo. Crear la fuente es un poco más complejo y estaremos discutiendo esto en unos pocos minutos.

La pantalla “Configure OLE DB Connection Manager” es luego traída a la vista. Escojo mi conexión “SQLShackFinancial” desde la lista de conexiones existentes. Esta conexión fue creada para una presentación previa que escribí para SQL Shack.

Hago clic en OK, y somos traídos de vuelta a nuestra superficie de trabajo.

Hacer doble clic en el control “Execute SQL Task” abre “Execute SQL Task Editor”.

El lector notará que he establecido la cadena de conexión para apuntar a nuestra conexión “SQLShackFinancial” y he ingresado dos simples comando T-SQL en la caja de texto “SQL Statement”. En nuestra discusión en curso y porque esta presentación es para una demostración, prefiero truncar las tablas previo a la demostración. DE TODOS MODOS, en realidad estas tablas no serían limpiadas cada corrida.
Hago clic en OK, y OK para salir del control “Execute SQL task” y aterrizamos (una vez más) en nuestra superficie de trabajo.

¡Comencemos el VERDADERO trabajo!
Ahora arrastro un “Foreach Loop Container” a mi superficie de trabajo.

Para que ocurra la ‘magia’, debemos “establecer” y configurar unas pocas variables dentro de “Foreach Loop Container”. Hago doble clic en el control y el editor “Foreach Loop” se abre.

Primero hago clic en la pestaña “Collection” y configuro esta pestaña como sigue:

Note que he ingresado la Carpeta en la que los libros puede/serán encontrados y le digo a SSIS que deseo que el paquete INCLUYA TODOS LOS LIBROS encontrados en esta carpeta. En el mundo real, este directorio sería encontrado en un servidor con un “disco común” usado por todos aquellos departamentos con los correctos derechos.
Ahora nos movemos a la tercera pestaña “Variable Mappings” para crear la variable. El “Foreach Loop Editor” es una vez más mostrado (ver abajo).

Haciendo clic en la pestaña “Variable”, puedo permitirme la oportunidad de añadir una nueva variable (ver abajo).

Llamo a mi variable “ExcelFile” y establezco “Value” al nombre de mi primer libro (ver abajo). Esto es MÁS un valor por defecto que para cualquier otro propósito.

Hago clic en OK para salir del diálogo “Add Variable”.
Ahora hemos completado la configuración de nuestro “Foreach Loop Container”.
Abrir nuestra ventana “Variables”, veremos que las variables han sido definidas (ver abajo).

Note la variable (ver abajo).

Ahora estamos listos para seguir.
Ahora combino “Execute SQL Task” con nuestro “Foreach Loop Container”.

Configurando la fuente de datos Excel o “puede que usted quiera un poco de Slivovitz”
¡Configurar la “Fuente de Datos Excel” CORRECTAMENTE al principio me “llevó a la bebida”!
Inicio arrastrando una Excel Data Source al administrador de conexiones (ver abajo).

Hago clic derecho dentro de “Connection Managers” y elijo “Add a new Connection”. Selecciono “EXCEL” (ver arriba).
Navego para encontrar el primer libro Excel (ver abajo).

Para aceptar esto, hago clic en “Open”.

Mi conexión puede estar “finalizada”, ¡PERO aquí viene la parte realmente difícil!
Por favor quédese conmigo durante las siguientes oraciones.
Ahora hago clic derecho en la conexión Excel que creamos recién y abro la página de propiedades.
Encuentre la propiedad “Expressions” y haga clic en la elipsis. Property Expression Editor se mostrará (ver abajo).

Elija “Connection String” desde el menú desplegable “Property”.

Y copie la siguiente expresión:
Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\Excel Load Loop\financial1.xlsx ;Extended Properties=”Excel 12.0;HDR=YES”;
¡NOTE que cualquier referencia a XML debe ser removida!
En la caja “Expression” (ver abajo) o un ejemplo mejor puede ser visto en la sección titulada ‘Caveat Emptor’ abajo.
Ahora estamos listos para designar nuestro Flujo de Datos.
Creando el Flujo de Datos
Para comenzar añadimos un “Data Flow Task” a nuestro “Foreach Loop Container”. Ver abajo.

Yendo a la pestaña Data Flow en nuestro proyecto SSIS, encontramos nuestra superficie vacía.

Ahora añado un “Excel Data Source” a la superficie de trabajo.

Haciendo doble clic al control, abro “Excel Source Editor”. Selecciono la pestaña “Connection Manager” y luego selecciono Financial1$ (mi nombre común de hoja de cálculo) (ver abajo).

Haga clic en la pestaña “Columns”, encuentro una lista de columnas dentro de la hoja de cálculo (ver abajo).

Ahora que estoy feliz de que todas las columnas estén presentes, hago clic en OK para salir de “Excel Source Editor”.
Ya que yo SÉ que mis “Base currency codes” están en el formato incorrecto, arrastro un control “Data Conversion” a la superficie de trabajo y lo combino con mi “Excel Data Source”.

Abriendo el control “Data Conversion” encuentro mi “Base currency code” y lo convierto a formato “DT_WSTR” con un tamaño de 25 (ver abajo).

Ahora estamos completos con nuestras conversiones de datos. Usted posible o probablemente tendrá campos adicionales que deben ser convertidos previamente a poder incluir valores en las tablas de su base de datos SQL Server. Deberían ser ingresados debajo del código de moneda base (como se muestra en la captura de pantalla).
Ya que mis valores “per share” están delimitados por comas y esto a menudo crea problemas cargando los valores a SQL Server, he optado por añadir un paso adicional de transformar los datos vía ‘columna derivada’. Sí, podría haber alterado el formato de los datos de la hoja de cálculo para no ser delimitados por comas, PERO para este ejercicio quiero mostrarle una opción alternativa.

Abriendo “Derived Column Transformation Editor” reemplazo el campo existente ‘SHAREPAR’ con lo siguiente:

Ahora completé “Derived Column Transformation Editor”, por tanto, lo cierro haciendo clic en OK.
Arreglando otras columnas
Sabiendo bien que a menudo tengo nombres de monedas incorrectos o nombres de moneda VACÍOS en mis datos entrantes, ahora necesito abastecer ambos casos.
Ahora añado un “Conditional Split” para alimentar y abrir “Conditional Split Transformation Editor”.

El lector astuto notará que he abastecido solamente aquí para el caso de un nombre de moneda vacío en los datos entrantes. Veremos cómo manejar los nombres de moneda erróneos en unos poco minutos.
Cierro “Conditional Split Transformation Editor”.
Para la rama “Good Data” de Conditional Split, ahora realizo un “Look up” para asegurarme de que el nombre de la moneda en mis registros entrantes son válidos. Añado un control “Look up”.

Con “Look up” añadido, debo configurar la porción “Good Data”. Selecciono la opción “Good Data”.
Debo ahora configurar el control “Look Up”.

Configuro la tabla de búsqueda para verificar mi lista maestra de monedas dentro de la tabla Currency.
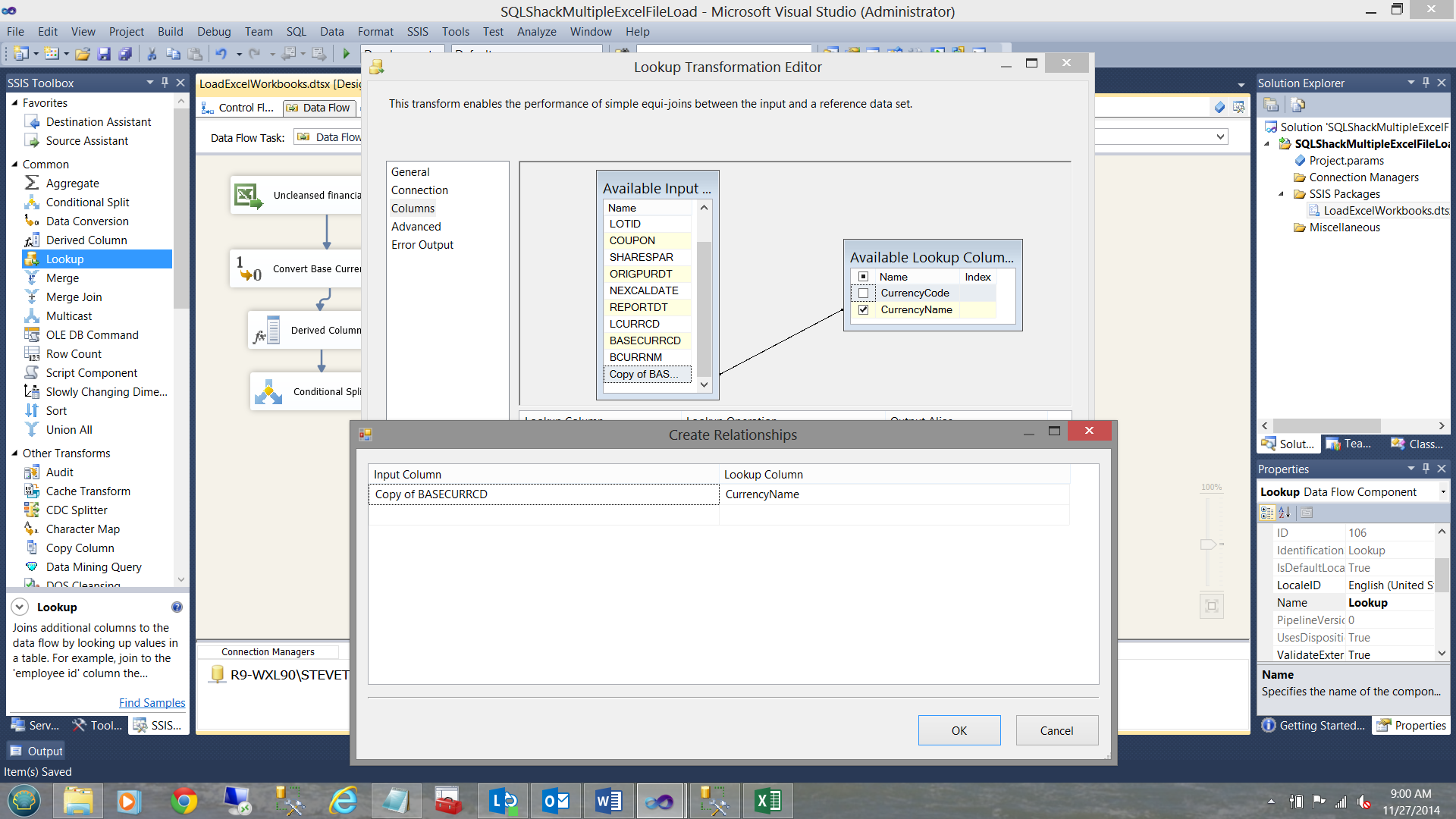
Como notará arriba, he mapeado la copia del código de moneda al código de moneda desde la lista maestra dentro de la tabla “Currency”. Deseo buscar el Nombre de Moneda. Ahora finalizamos con “Look up”, por lo que cierro el Editor.
Nuestra superficie de trabajo ahora se ve como sigue:

Vamos a configurar la otra rama de “Conditional Split”. Vamos a administrar los nombres vacíos de moneda.
Como un aparte, mientras sepamos que las monedas vacías son erróneas y como tales deben ser colocadas en la tabla “FASBerror”, hay otro caso que debemos tomar en consideración y es: ¿debería ser incorrecta la moneda adjunta a un registro? Como un ejemplo, no hay moneda llamada ‘QWERTY’. Dicho esto, necesitamos añadir a “Union All”. La búsqueda etiquetada como ‘Lookup’ (ver abajo) agarrará ‘Querty’ y la canalizará a los datos malos “Union All”.

De esta manera, todos los registros con nombres vacíos de moneda MÁS todos los registros con nombres malos de moneda como “QWERTY” serán redirigidos a nuestra tabla “FASBerror”. AHORA creemos una conexión a esa tabla “FASBerror”. Ahora añado un OLE DB Date Destination a nuestra superficie de trabajo y lo configuro para apuntar a nuestra tabla FASBerror.

Luego verificamos que los campos están mapeados correctamente.

Hacemos clic en OK para salir de “OLE DB Destination Editor”. Nuestra superficie de diseño se parece a la captura de pantalla abajo:

Administrando los registros “Correctos”
Para completar nuestro paquete, debemos añadir la habilidad para colocar los registros correctos en nuestra tabla de la base de datos de producción. Para hacerlo añadimos un control OLE DB Destination (ver abajo).

Ahora debemos sólo configurar este destino OLE DB. Como en el pasado, configuramos el destino como sigue:

Esto completa la construcción de nuestro paquete.
Dándole a su paquete un dispositivo de prueba
Corriendo nuestro paquete, podemos ver que todo está bien.

Dando un vistazo en SQL Server Management Studio, vemos los resultados en nuestros buenos registros.

Y nuestros registros rechazados.

Caveat Emptor
Para que todo este mecanismo funcione correctamente, tres ajustes son ABOLUTAMENTE CRÍTICOS. Si estos ajustes no son correctos, usted terminará procesando el mismo archivo una y otra vez, tantas veces como el número de archivos Excel.
- La conexión Excel debe ser correcta.

- La ‘Variable de Usuario’ Excel File debe ser correctamente definida (ver abajo).

- La EXPRESSION para la cadena de conexión debe ser correcta, como se muestra a continuación:

Una vez más podemos acceder a Expression Property de la cadena de conexión Excel haciendo clic en la conexión Excel (en Connection Managers) y seleccionando la casilla Expressions property y haciendo clic en la elipsis (ver abajo).

Conclusiones
A menudo uno tiene datos del mismo formato desde muchas fuentes. La mayoría de las personas en el área financiera utilizan hojas de cálculo Excel para cargar sus datos. En el caso de mi cliente, las varias cuentas de fondos tenían sus propias valuaciones que fueron calculadas diariamente para sus propiedades. Estos resultados fueron publicados diariamente a la base de datos de producción.
Usando un “Foreach Container” y un poco de desarrollo innovador, pudimos configurar un paquete SSIS el cual usted también puede que lo emplee por su lado.
Finalmente, el paquete SSIS puede ser iniciado por el agente SQL Server O usando un .Net File System Watcher (que busca la presencia de número correcto de archivos O la presencia del último archivo diario) y luego inicia un archivo de lotes que contiene una llamada DTEXEC al paquete SSIS.
Esta es la técnica que he empleado.
Si desea más información, por favor contácteme.
En ínterin, ¡feliz programación!
Steve ha hecho presentaciones en 8 PASS Summits y una en PASS Europe 2009 y 2010. Él ha presentado recientemente una presentación de Master Data Services en PASS Amsterdam Rally.
Steve ha hecho 5 presentaciones en Information Builders’ Summits. Él es un mentor regional de PASS.
Ver todas las entradas de Steve Simon
- Procedimientos Recomendados para SQL Server Reporting Services - December 24, 2016
- Excel cargando múltiples libros a SQL Server - December 24, 2016
- Creando archivos CSV dinámicamente generados que contienen datos de SQL Server - October 29, 2016