

Este artículo va a cubrir la función STRING_SPLIT en SQL Server, incluida una descripción general y ejemplos detallados de uso.
Los usuarios de SQL Server por lo general necesitan funciones de análisis y manipulación de cadenas. En varios escenarios, esta operación de análisis o manipulación de cadenas puede ser un dolor de cabeza para los desarrolladores o administradores de bases de datos. Por esta razón, en cada versión de SQL Server, Microsoft ha anunciado la implementación nuevas funciones de cadena. Se agregaron nuevas funciones de cadena como STRING_ESCAPE, STRING_SPLIT en SQL Server 2016 y las funciones de cadena CONCAT_WS, STRING_AGG, TRANSLATE, TRIM se agregaron en SQL Server 2017.
En este artículo, analizaremos la función STRING_SPLIT, en particular. El propósito de esta función de cadena incorporada es convertir matrices de cadenas en columnas que están separadas por cualquier separador. La siguiente figura ilustra la idea principal de esta función.

Como ya mencionamos en la sección de entrada del artículo, esta función se introdujo en SQL Server 2016 y las versiones anteriores de SQL Server no son compatibles con esta función integrada. En otras palabras, esta función no es compatible con el nivel de compatibilidad 130. La siguiente tabla ilustra las versiones de SQL Server y sus niveles de compatibilidad.
SQL Server Versions | Compatibility Level |
SQL Server 2019 preview | 150 |
SQL Server 2017 (14.x) | 140 |
SQL Server 2016 (13.x) | 130 |
SQL Server 2014 (12.x) | 120 |
SQL Server 2012 (11.x) | 110 |
SQL Server 2008 R2 | 100 |
SQL Server 2008 | 100 |
SQL Server 2005 (9.x) | 90 |
SQL Server 2000 | 80 |
Ahora, comencemos a analizar los conceptos de uso y otros detalles de esta función.
Sintaxis:
La sintaxis es muy simple, ya que esta función incorporada con valores de tabla solo toma dos parámetros. El primero es una cadena y el segundo es un solo carácter.
STRING_SPLIT (cadena, separador)
El siguiente ejemplo muestra el uso más simple de esta función.
|
1 |
select value from STRING_SPLIT('apple,banana,lemon,kiwi,orange,coconut',',') |

La siguiente consulta SELECT devolverá un error debido al nivel de compatibilidad de la base de datos.
|
1 2 3 4 5 |
ALTER DATABASE AdventureWorks2012 SET compatibility_LEVEL=120 GO select value from STRING_SPLIT('apple , banana , lemon , kiwi , orange ,coconut',',') |

La razón de este error es que disminuimos el nivel de compatibilidad de la base de datos en 130 y SQL Server devuelve un error. Tiene que tener en cuenta que, si se planea usar esta función en su entorno de cliente, debe estar seguro del nivel de compatibilidad de su base de datos.
Cláusula STRING_SPLIT y WHERE:
A través de la cláusula WHERE, podemos filtrar el conjunto de resultados de la función STRING_SPLIT. En la siguiente instrucción select, la cláusula WHERE filtrará el conjunto de resultados de la función y solamente devolverá la fila o filas que comienzan con “le“.
|
1 2 3 4 |
select value from STRING_SPLIT('apple,banana,lemon,kiwi,orange,coconut',',') WHERE value LIKE 'le%' |

Además de eso, podemos usar la función de la siguiente manera:
|
1 2 3 4 5 6 |
USE AdventureWorks2014 GO select * from HumanResources.Employee WHERE [jobtitle] IN (select value from string_split('Chief Executive Officer , Design Engineer',',')) |

Entonces, ahora veremos el plan de ejecución con la ayuda del ApexSQL Plan. Por lo tanto, podemos ver el operador de función con valores de tabla en el plan de ejecución.

El momento en el que pasamos el cursor sobre el operador de función con valores de tabla en el plan de ejecución, podemos encontrar todos los detalles sobre este operador. Debajo de la etiqueta del objeto, se puede apreciar la función STRING_SPLIT. Todos estos detalles nos dicen que esta función es una función con valores de tabla.

STRING_SPLIT y ORDER BY
Otro requisito que necesitamos en las instrucciones SELECT es la funcionalidad de clasificación. Podemos tratar de ordenar la salida de esta función que se parece a las otras declaraciones T-SQL.
|
1 2 3 4 |
select value from STRING_SPLIT('apple,banana,lemon,kiwi,orange,coconut',',') order by value |

Nota: Cuando revisé algunos comentarios de los clientes sobre SQL Server, me encontré con una sugerencia sobre la función STRING_SPLIT que es “La nueva función del divisor de cadenas en SQL Server 2016 es una buena adición, pero necesita una columna adicional, una columna ListOrder que denota el orden de los valores divididos ”. En mi opinión, esta característica puede ser muy útil para esta función y voté por esta sugerencia.
STRING_SPLIT y JOIN:
Podemos combinar el conjunto de resultados de la función en la otra tabla con la cláusula JOIN.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [AdventureWorks2014] GO SELECT [PersonType] ,[NameStyle] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person] P INNER JOIN string_split('Ken,Terri,Gail',',') on P.FirstName=value |

Aparte de eso, podemos utilizar la función APLICACIÓN CRUZADA para poder combinar el conjunto de resultados de la función STRING_SPLIT con otras tablas. La función APLICACIÓN CRUZADA nos proporciona el poder unir la salida de la función de valor de tabla a otras tablas.
En el siguiente ejemplo, vamos a crear dos tablas y la primera tabla (#Países) almacenara el nombre y el continente de países y la segunda tabla (# CityList) almacenara la tabla de la ciudad de los países, pero el punto crucial es la tabla # CityList la cual almacenara los nombres de las ciudades como matriz de cadenas que está separada por una coma. Uniremos esto a la tabla sobre columnas de país y utilizaremos la función CROSS APPLY para transformar la matriz de ciudades en una columna. En la siguiente imagen se puede ilustrar qué haremos.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
DROP TABLE IF EXISTS #Countries GO DROP TABLE IF EXISTS #CityList GO CREATE TABLE #Countries (Continent VARCHAR(100), Country VARCHAR(100)) GO CREATE TABLE #CityList (Country VARCHAR(100), City VARCHAR(5000)) GO INSERT INTO #Countries VALUES('Europe','France'),('Europe','Germany') INSERT INTO #CityList VALUES('France','Paris,Marsilya,Lyon,Lille,Nice'), ('Germany','Berlin,Hamburg,Munih,Frankfurt,Koln') SELECT CN.Continent,CN.Country,value FROM #CityList CL CROSS APPLY string_split(CL.City,',') INNER JOIN #Countries CN ON CL.Country = CN.Country DROP TABLE IF EXISTS #Countries GO DROP TABLE IF EXISTS #CityList GO |

Más detalles sobre STRING_SPLIT
Después de todo, la metodología de uso básica de esta función; profundizaremos en más detalle. En los ejemplos anteriores usamos siempre una coma (,) como separador para la función, sin embargo, es probable que necesitemos utilizar otros caracteres como separador. La función STRING_SPLIT nos va a permitir usar otros símbolos como separador, pero tiene una limitación sobre este uso. De acuerdo con el MSDN; un separador es un tipo de dato único y este tipo de dato de parámetros puede ser nvarchar(1), char(1) y varchar(1). Ahora, haremos una muestra al respecto. La siguiente instrucción SELECT se va a ejecutar sin error. Así como utilizaremos el (@) en lugar de una coma (,).
|
1 2 3 |
DECLARE @STRINGLIST AS VARCHAR(1000)='apple,banana,lemon,kiwi,orange,coconut' DECLARE @SEPERATOR VARCHAR(1)=',' select * from STRING_SPLIT(@STRINGLIST,@SEPERATOR) |

No obstante, la siguiente instrucción SELECT nos devolverá un error debido a la declaración del tipo de datos.
|
1 2 3 |
DECLARE @STRINGLIST AS VARCHAR(1000)='apple@+@banana@+@lemon@+@kiwi@+@orange@+@coconut' DECLARE @SEPERATOR VARCHAR(3)='@+@' select * from STRING_SPLIT(@STRINGLIST,@SEPERATOR) |

“El procedimiento espera el parámetro ‘separador’ del tipo ‘ nchar(1) / nvarchar (1)’”. La definición de error es muy clara e indica un problema relacionado con el tipo de datos del separador. Después de esta muestra, puede que aparezca una pregunta en su mente. ¿Podemos asignar un valor NULL al separador? Vamos a probar y aprender.
|
1 2 3 |
DECLARE @STRINGLIST AS VARCHAR(1000)='apple,banana,lemon,kiwi,orange,coconut' DECLARE @SEPERATOR VARCHAR(1)=NULL select * from STRING_SPLIT(@STRINGLIST,@SEPERATOR) |

No podemos asignar un valor NULL al separador como un valor.
Aparte de eso, cuando utilizamos esta función para valores numéricos, el conjunto de resultados se encontrará en tipos de datos de cadena. Cuando vayamos a ejecutar la siguiente consulta, podremos ver todos los detalles y generar el tipo de datos de la tabla establecida.
|
1 2 3 4 5 6 7 8 9 |
DROP TABLE IF EXISTS TempStringSplit SELECT VALUE INTO TempStringSplit FROM string_split('1,2,3',',') AS StrSplit SELECT TABLE_NAME,COLUMN_NAME,COLUMN_DEFAULT,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH FROM INFORMATION_SCHEMA.COLUMNS where TABLE_NAME='TempStringSplit' DROP TABLE IF EXISTS TempStringSplit |

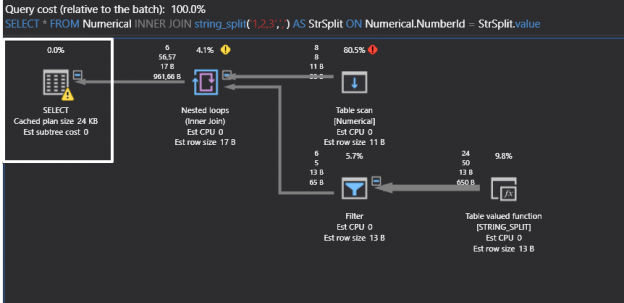
Ahora analizaremos el siguiente plan de ejecución de consultas con ApexSQL Plan.
|
1 2 3 4 5 6 7 8 9 10 |
DROP TABLE IF EXISTS TempNumerical GO CREATE TABLE TempNumerical (NumberId INT) INSERT INTO Numerical VALUES ( 1),(2),(3),(5) GO SELECT * FROM Numerical INNER JOIN string_split('1,2,3',',') AS StrSplit ON Numerical.NumberId = StrSplit.value |

En el operador seleccionado, se está mostrando una señal de advertencia y ahora descubriremos los detalles sobre dicha advertencia.

La razón de esta advertencia es que intentamos unir el tipo de datos enteros con el tipo de datos varchar, por lo que este tipo de uso provoca una conversión implícita. Las conversiones implícitas afectan el rendimiento de la consulta.
Conclusión
En este artículo, hemos mencionado los métodos de uso y todos los aspectos de las funciones STRING_SPLIT. Esta función tiene un uso muy básico y nos ayuda a convertir matrices en columnas. Además, cuando comparamos esta función integrada con otras funciones definidas por el usuario del cliente, mejora drásticamente el rendimiento de las consultas.
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- Administrador de servicios de informes de configuración de SQL Server - November 5, 2019
- La función STRING_SPLIT en SQL Server - November 4, 2019