
La responsabilidad más importante de un Administrador de bases de datos es el poder garantizar que las bases de datos trabajen de una forma óptima. La manera más eficiente de hacerlo es por medio de índices. Los índices en SQL son uno de los recursos más efectivos a la hora de obtener una ganancia en el rendimiento. Sin embargo, lo que sucede con los índices es que estos se deterioran con el tiempo.
He logrado redactar bastantes artículos sobre los índices en SQL ya que gran parte de ellos abarcan cosas como los índices del SQL Server, cómo crearlos y modificarlos, cómo acelerar una sola consulta, etc. Pero me hizo pensar, que la optimización es un tema difícil. Es sencillo optimizar una sola consulta, pero en el mundo real, tenemos miles de consultas diferentes que modifican las bases de datos. Es muy difícil analizar y poder optimizar cada una de ellas de una manera más individual. Debe haber una solución más eficiente para que podamos mantener a los índices SQL. ¿Cierto?
La respuesta es que sí lo hay. Pero demanda hacer una estrategia para poder realizar un mantenimiento ideal y para poder garantizar que los índices estén funcionando de forma correcta. En este artículo hablaremos sobre el mantenimiento de los índices, y asumo que el lector está familiarizado con el tema de la indexación de SQL. En el caso que no sea así, sería como empezar leyendo desde el final hacia el comienzo, esto porque este artículo se dirige a las personas que tienen conocimientos básicos del tema, que ya ha creado índices antes y ya pasó un lapso de tiempo donde se han empezado a degradar, ¿qué se hace para que vuelvan a un estado óptimo?
Para aquellas personas que no tienen un conocimiento básico, les recomiendo que lean el siguiente artículo antes de abordar a este artículo: Cómo crear y optimizar los índices de SQL Server para un mejor rendimiento
Sin mayores preámbulos, empecemos con el tema que trata solamente del mantenimiento de los índices. Vamos a comenzar explicando en que consiste el mantenimiento del índice.
Información general de mantenimiento del índice SQL
El problema en un mantenimiento de índices y del rendimiento es la fragmentación del índice. Es posible que ya estés familiarizado con el término de fragmentación del sistema operativo y del disco duro. La fragmentación es lo que arruina nuestros índices y, claro, los discos duros en el entorno del sistema operativo (No tanto desde que salen las unidades físicamente). A medida que los datos entran y salen, se modifica, etc. las cosas deben moverse. Esto implica una gran cantidad de actividad de lecturas y escrituras en nuestros discos duros.
La fragmentación es básicamente el poder almacenar datos de forma no contigua en el disco. Entonces, la idea principal es de intentar de mantenerlo de forma contigua (en secuencia) ya que, si los datos se almacenan de manera contigua, es mucho menos el trabajo para nuestro sistema operativo y el subsistema del I/O ya que sólo se deben manejar las cosas de manera secuencial. Por otro lado, cuando los datos están en desorden, entonces el sistema operativo debe saltar por diferentes lugares. Siempre me gusta explicar las cosas usando una analogía del mundo real y para los índices, siempre uso una agenda normal o una guía telefónica para poder explicar la recuperación de datos ya es mucho más fácil de poder entender. Pero para la desfragmentación, yo creo que el mejor ejemplo sería el de un estante para libros.

Existen dos tipos de fragmentaciones:
- Interna – este tipo de fragmentación ocurre cuando ingresan nuevos datos y no existe un espacio para ellos. Si miramos la imagen de arriba, podemos ver que existe un bibliotecario que tiene un nuevo libro que debe colocarse dentro de esa estantería, pero ya no hay lugar para él. Esto significa que es necesaria otra estantería para poder mover un tercio de los libros que están allí, dejar dos tercios por aquí, etc. El problema de hacer eso, es que ahora se tienen dos páginas de datos no llenas en lugar de una sola página con los datos completos. Esto repercute en un rendimiento deficiente y en el almacenamiento en caché porque SQL server almacena en caché al nivel de la página de datos. En el siguiente ejemplo, SQL Server debería almacenar en caché dos páginas completas en lugar de una porque se realizó la asignación de ese espacio vacío.
- Externa – con este tipo de fragmentación, estamos lidiando con las estanterías en sí. Añadiendo a la analogía anterior, podríamos decir que el bibliotecario tendría que mover todos los libros de abajo y llevarlos al nuevo estante para poder liberar algo de espacio. El problema en este caso es que no se puede simplemente poner el nuevo estante al lado debido a que ya había un estante allí lleno de libros. Por tanto, se termina con una estantería fuera de lugar y si se trata de buscar un libro por sus datos, se podría descubrir que no está allí. Se tendría que buscar en otra estantería, ir allí, etc. Esto significa que hay un rendimiento deficiente y un desaprovechamiento en el I/O.
Para sintetizar las cosas, la fragmentación interna son los datos en sí dentro de las páginas generalmente causadas por una división de la página y la fragmentación externa son los nuevos estantes colocados de forma desordenada. Todo esto se trata de tener una continuidad y secuencialidad. Ya que lo que se quiere es que todos nuestros datos sean contiguos. Los datos contiguos a través de páginas contiguas son nuestro objetivo principal y también con índices. Esto es lo que queremos logar para construir y reconstruir. Si hacemos bien las cosas, como resultado, lograremos un mejor almacenamiento en caché (solo cargar lo que necesitamos en el búfer) y menos trabajo del I/O para nuestros subsistemas.
Veamos de forma rápida cómo funciona esto a un nivel de SQL Server. La figura a continuación muestra cuando todo está en orden. Tenemos dos páginas secuenciales, las filas también son secuenciales en las dos páginas. Esta es la imagen ideal que podemos ver cuando creamos primero un índice SQL y después de reconstruir o reorganizar el índice. En otras palabras, cero fragmentaciones porcentuales:

Contrariamente a esto, podríamos tener algo como la figura a continuación. Como se observar, tenemos páginas en desorden, y también filas en desorden.

De hecho, estas están en orden por ahora, pero que pasa si necesitamos insertar un nuevo registro en esta tabla. El servidor SQL Server busca un punto vacío y las páginas actualizadas se verían de la siguiente manera:

Así es como se vería una tabla fragmentada. Además, si introducimos otro registro, SQL Server tendría que insertar otra página AKA División de página, mover la mitad de filas de la página anterior, insertar otras nuevas, etc. Al realizar esto, esta tabla puede llegar a estar muy fragmentada bastante rápido. Tomar en cuenta que la división de páginas se produce no sólo en las inserciones, sino que a su vez en las actualizaciones. Esto se produce cuando se desea actualizar un registro y se vuelve demasiado grande para ajustarse a la página. El mismo proceso que se produce dentro de las inserciones y esto vuelve a suceder.
Entonces, esto es una fragmentación interna y externa en pocas palabras. Tomar en cuenta que los grandes problemas de rendimiento se originan de un diseño deficiente, la ausencia de una indexación de SQL y los índices fragmentados.
Las directrices de mantenimiento del índice SQL
Ya tenemos una idea más clara de cuál es el problema con la fragmentación, enfoquémonos en cómo resolverlo. Ya que podemos arreglarlo de dos maneras. Hay pros y contras para ambas de estas maneras, y el que se elija dependerá del entorno, la situación, el tamaño de la base de datos, etc. Las dos tienen el mismo objetivo, que es lograr que todo sea secuencial:
- Reconstruir – Esto origina un nuevo índice SQL. La reconstrucción es más limpia, más fácil y por lo general mucho más rápida (esto es significativamente más rápido en una base de datos grande). Ya que perdemos un poco de simultaneidad al producir una reconstrucción en línea porque crea un bloqueo SCH-M y encima de eso si ejecuta esto durante un día ajetreado y está absorbiendo demasiados recursos, probablemente tendrá que cancelar toda la operación. Lo que significa que realmente va a tener que revertir todo como si fuera una transacción.
- Reorganizar – corrige el orden físico y las páginas compactas. Reorganizar es mejor opción para la simultaneidad y además de que si la operación es cancelada como en el ejemplo anterior, simplemente solo se detendrá, y no perderemos el trabajo que ya se hizo justo hasta el momento en que se canceló.
La directriz general aquí es, el reconstruir los índices SQL cuando sea posible y reorganizar cuando la fragmentación es baja. Veamos algunas recomendaciones de Microsoft más adelante en este artículo. Además de lo que ya se ha dicho, Hay unas pautas adicionales y una breve explicación en que tenemos que tener cuidado:
- Identificar y eliminar la fragmentación de índices – esto es claramente de lo que hemos estado viendo hasta ahora y la mayor parte del mantenimiento del índice SQL.
- Encontrar y eliminar los índices no utilizados – todo lo que está sin usar no hace ni genera nada bueno. Lo único que hacen es desperdiciar el espacio y los recursos. Es mejor que los eliminemos a menudo.
- Detectar y crear índices faltantes – esto es obvio.
- Reconstruir/reorganizar los índices semanalmente – como se mencionó anteriormente, esto dependerá del entorno, la situación, el tamaño de la base de datos, etc.
- Clasificar el porcentaje de fragmentación – Microsoft te sugiere reconstruir los índices cuando tenemos una fragmentación superior al 30 % y reorganizarlos cuando están entre una fragmentación del 5 % y un 30 %. Estas son las pautas generales a seguir, pero hay que tener en cuenta que esto cubrirá un buen porcentaje de bases de datos en el mundo real, pero de nuevo esto podría no ser aplicable para cada situación.
- Crear trabajos para automatizar el mantenimiento – cree un Agente de SQL Server que automatizará el mantenimiento del índice SQL. A continuación, supervise y modifique los trabajos de una forma más adecuada para un entorno particular porque el estado de los datos fluctúa en función de muchas cosas.
Tener en cuenta, que al crear estos trabajos puede llegar ser una espada de doble filo. Siempre debemos monitorear cuánto tiempo tarda en terminar el plan de mantenimiento. Recomendaría la aplicación de planes de mantenimiento sólo en pequeñas bases de datos y el uso de scripts personalizados en cualquier otro lugar o incluso todo el tiempo. Los scripts son una solución flexible y generalmente mejor, mientras que los planes son rápidos y una solución más simple.
Analicemos que podemos hacer para evitar la fragmentación del índice SQL. Hay un par de consejos acerca de este tema y esto es lo que se desea:
- Disminuir la división de la página y la baja densidad de página – el objetivo principal es evitar tener un registro de páginas con una cantidad mínima de datos en ellos. La mejor práctica y guía es que menos páginas llenas de datos sean mejores. Pero en una tabla que tiene un gran número de inserciones y estamos hablando de miles por minuto, necesitamos un poco más de espacio libre en las páginas para eliminar la división de la página por SQL Server llenando esas páginas vacías.
- Elegir claves de índice SQL secuenciales – esta es una forma de poder lograr el Consejo anterior. Más información sobre esto, más adelante en el artículo cuando veamos al SSMS y creamos la tabla secuencial y no secuencial para ver cómo se produce la fragmentación.
- Elija claves de índice SQL estáticas – las claves de índice que no cambian son exactamente las que eliminan la fragmentación.
Empecemos de una vez, veamos un ejemplo. Abra SSMS y lo primero que tenemos que hacer es echar un vistazo más de cerca a: lo secuencial versus los índices SQL no secuenciales. Como siempre, vamos a usar la base de datos AdventureWorks de ejemplo, pero si quieres puedes crear una nueva si lo deseas. Tienes que estar seguro de que seleccionar una base de datos adecuada y ejecute el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
--Sequential index on ID (identity) CREATE TABLE dbo.FragTestSequential (ID INT IDENTITY(1, 1) NOT NULL, Name NVARCHAR(50) NULL, SomeData NVARCHAR(200) NULL, CretatedDate DATETIME NULL ); GO CREATE CLUSTERED INDEX CIX_ID ON dbo.FragTestSequential(ID); --Non-sequential index on ID (newid) CREATE TABLE dbo.FragTestNonSequential (ID UNIQUEIDENTIFIER DEFAULT NEWID() NOT NULL, Name NVARCHAR(50) NULL, SomeData NVARCHAR(200) NULL, CretatedDate DATETIME NULL ); GO CREATE CLUSTERED INDEX CIX_ID ON dbo.FragTestNonSequential(ID); |
Después de que esto finalice correctamente, si navegamos en el explorador de objetos, seleccionamos nuestra base de datos de ejemplo, y expandimos y actualizamos tablas, deberíamos ver las tablas recién creadas:

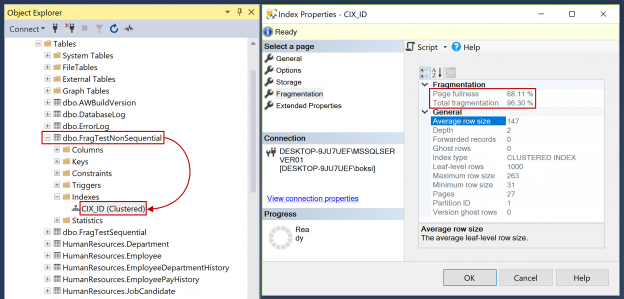
Esas dos tablas son idénticas, la única diferencia es el Nombre, y una se creó con el índice SQL secuencial en la columna ID (1,2, 3, etc.) y la otra se crea con el índice no secuencial en el mismo nombre de columna usando el uniqueidentifier con el NEWID que generará aleatoriamente GUID. Los dos tienen un índice agrupado en la misma columna. A continuación, también podemos comprobar que los índices están expandiendo las tablas, luego la carpeta Indexes y deberíamos ver el índice CIX_ID (agrupado). Además, si hacemos clic con el botón derecho sobre él, entramos a propiedades y seleccionamos fragmentación, ya que se trata de un nuevo índice, deberíamos ver tanto en plenitud la página (el porcentaje promedio de páginas llenas) como la fragmentación total (Porcentaje de fragmentación lógica teniendo en cuenta múltiples archivos.) como los valores serán 0,00 %:

Ya que ambas tablas están vacías, no podemos usarlas realmente a menos que tengamos algunos datos en ellas. Entonces, vamos a ingresar algunos datos aleatorios en ellos. Podemos hacerlo ejecutando el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
--Insert (generate sequential) INSERT INTO dbo.FragTestSequential (dbo.FragTestSequential.Name, dbo.FragTestSequential.SomeData, dbo.FragTestSequential.CretatedDate ) SELECT REPLICATE('name', ABS(CHECKSUM(NEWID()) % 10)), REPLICATE('data', ABS(CHECKSUM(NEWID()) % 20)), GETDATE(); GO 1000 --Insert (generate non-sequential) INSERT INTO dbo.FragTestNonSequential (dbo.FragTestSequential.Name, dbo.FragTestSequential.SomeData, dbo.FragTestSequential.CretatedDate ) SELECT REPLICATE('name', ABS(CHECKSUM(NEWID()) % 10)), REPLICATE('data', ABS(CHECKSUM(NEWID()) % 20)), GETDATE(); GO 1000 |
El código anterior introduce mil registros en ambas tablas. Podrás notar que no hay repetición, simplemente ejecutamos la sentencia mil veces especificando el valor después de un GO, ya que se puede ver en la siguiente figura:

Ambos grupos realizaron exactamente lo mismo. La única diferencia es que tenemos nuestro ID secuencial en una tabla y no secuencial en el otro. Pero ahora, demos un vistazo primero al índice SQL secuencial. Simplemente hay que encontrarlo en el explorador de objetos, haga clic derecho sobre él y presione propiedades. Si ahora comprobamos la fragmentación, observe que la fragmentación está en 5,56 %:

¿Qué crees tú que podría ocurrir si insertamos otros miles de registros o datos en esta tabla? ¿Va a mejorar o a empeorar? Tendremos que averiguarlo ejecutando sólo el script de generación secuencial una vez más e insertamos miles de registros más:

Diríjase a las propiedades del índice de nuevo, y observe que la fragmentación total bajó a 2,78 %:

Como se esperaba, se pone mejor porque con los índices secuenciales SQL simplemente siguen llenando las páginas. Cuando este necesita otra página, solo la creará, la rellenará, y así sucesivamente sin reorganizar ni mover nada.
Ahora, si nos enfocamos a no secuencial y comprobamos la fragmentación podemos ver un valor significativamente más alto de 96,30 % de fragmentación. Te aseguro que si ejecutamos la sentencia INSERT una vez más este número se irá incrementado cada vez más:

Con suerte, este ejemplo que hemos hecho te dará una idea de cómo algo tan simple como poner un índice en un campo que no es secuencial es esencial para un índice SQL.
La pregunta que tenemos que hacernos es que pasa cuando el rendimiento comienza a bajar o tenemos quejas de otras personas de que hay una cierta degradación del rendimiento. No podemos simplemente ir a través de todos y cada índice en nuestra base de datos, haga clic derecho en nuestro índice y comprobar la información de fragmentación. Como se imaginaría esto podría ser muy lento y no muy práctico. Entonces, es cuando debemos identificar la fragmentación del índice SQL de una forma más eficiente.
Además de esta comprobación de propiedades de fragmentación de índice en SSMS, también se puede usar DMVs. El primero es sys.dm_db_index_physical_stats este se usa para poder devolver la información del tamaño y fragmentación para los datos y los índices SQL de la tabla o vista especificada en SQL Server. Es básicamente la misma información que podemos obtener de GUI justo a través de un DMV. Asegúrate de que está conectado a una base de datos adecuada y copie la siguiente consulta:
|
1 2 3 4 5 6 7 8 9 10 |
--Fragmentation SELECT OBJECT_NAME(ix.object_ID) AS TableName, ix.name AS IndexName, ixs.index_type_desc AS IndexType, ixs.avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) ixs INNER JOIN sys.indexes ix ON ix.object_id = ixs.object_id AND ixs.index_id = ixs.index_id WHERE ixs.avg_fragmentation_in_percent > 30 ORDER BY ixs.avg_fragmentation_in_percent DESC; |
Si analizamos de forma rápida el código, podemos apreciar que estamos pasando el ID de la base de datos y tomamos el DMV, luego nos unimos a sys.index para recuperar el nombre del índice, y una cláusula Where para obtener solo los índices que tienen más del 30 por ciento de fragmentación. Como resultado de esta consulta se genera una lista de índices SQL que queremos reconstruir. Entonces, ejecutemos la consulta y analicemos la base de datos de muestra:

La consulta nos devolvió 96 índices y en la parte superior de la lista esta nuestro índice SQL no secuencial de prueba, pero a su vez tenemos algunos números bastante altos a continuación. Esos son también índices fragmentados de havy y deben reconstruirse.
El segundo DMV es sys.dm_db_index_usage_stats que se aplica para poder devolver recuentos de diferentes tipos de operaciones de índice de SQL y el momento en que se realizó por última vez cada tipo de operación. Como antes, usemos el código que se encuentra abajo y ejecútelo en una base de datos de destino. No hay nada en mi base de datos de muestra, por lo que lo corrí contra otro con tráfico actual:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--Unused indexes (Index usage) SELECT OBJECT_NAME(ix.object_ID) AS TableName, ix.name AS IndexName, ixs.user_seeks, ixs.user_scans, ixs.user_lookups, ixs.user_updates FROM sys.dm_db_index_usage_stats ixs INNER JOIN sys.indexes ix ON ix.object_id = ixs.object_id AND ixs.index_id = ixs.index_id WHERE OBJECTPROPERTY(ixs.object_id, 'IsUserTable') = 1 AND ixs.database_id = DB_ID(); |
Lo que se espera que esta consulta esencialmente haga, es ayudarnos a poder analizar los índices SQL no utilizados igual que antes, solo realizaremos un cambio menor en la sentencia Where para poder capturar solo las tablas de usuario. Adicionalmente, esto encontrará búsquedas, exploraciones, consultas y actualizaciones de un índice:

Lo que más se realizó aquí es una búsqueda y escaneo. La regla de oro es que los escaneos son malos, las búsquedas son buenas. Toda vez que vea busca, básicamente lo que significa que se está utilizando el índice SQL. También a su vez esto significa que hace un uso eficaz de un índice. Por otro lado, cuando los escaneos están presentes pueden significar que los índices simplemente no se están utilizando eficazmente como dentro de la búsqueda porque tenía que pasar por todo el índice para encontrar lo que necesitaba.
Como resultado es que, si encuentra índices SQL con un número bajo de busca y exploraciones, esto significa que no se están utilizando excepto para los casos en los que simplemente se han creado. Como se puede apreciar en las cifras de arriba, tenemos bastantes índices con un bajo número de busca y escaneos, incluso ceros. Entonces estos son candidatos a ser retirados o examinados de cerca en especial si va a hacer algo bueno para mejorar el rendimiento en lugar de simplemente tomar espacio y recursos.
Quisiera poder resumir esto con otra solución que realmente podría ayudarte en el mundo real. Hay informes útiles que podemos obtener desde el explorador de objetos si hacemos clic con el botón derecho en una base de datos, pasamos a informes, reportes estándar, encontrarás estadísticas de uso de índice y estadísticas físicas de índice que son excelentes y pueden profundizar en los detalles, y poder obtener alguna información útil sobre la fragmentación y el uso del índice SQL.

Confío en que este artículo sobre el mantenimiento del índice SQL te haya sido informativo y le doy gracias por haberlo.

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
View all posts by Bojan Petrovic