

La idea de este artículo es discutir la importancia y lo que implica la partición SQL y comprender las mejoras del comando truncate para el particionamiento en SQL 2016
Uno de los principales retos para un administrador de base de datos es identificar al candidato adecuado para realizar el particionamiento de tablas, ya que requiere experiencia en diseño e implementación.
Las siguientes son las varias opciones de truncamiento disponibles en SQL 2016
- Truncar particiones de manera individual
- Truncar varias particiones individuales
- Truncar un rango de particiones
- Truncar un intervalo con varias particiones individuales
Secciones importantes del artículo
- Establecer la importancia y la implicación de la partición de tabla SQL
- Identificar al candidato adecuado para particionar tablas
- Proporcionar una comparación en línea de las características disponibles en las diferentes ediciones de SQL 2016
- Discutir las mejoras de la partición truncada en SQL 2016
- Demostrar los casos de uso de particiones de tablas truncadas
Partición SQL
Entendamos primeramente el objetivo del particionamiento en SQL, por qué es necesario particionamiento y los factores que son vitales para poder decidir una estrategia de partición de tablas.
Las particiones son una asignación lógica de los datos físicos. Una división con un buen diseño, nos permite escalar los datos. Optimiza el rendimiento y simplifica la gestión de datos mediante la partición de cada tabla utilizando múltiples particiones independientes. Sin embargo, no todas las tablas son buenas candidatas para poder realizar una partición. Si la respuesta es “sí” a todas o a la mayoría de las siguientes preguntas, la partición de tablas puede ser una estrategia de diseño de base de datos viable; Si la respuesta es “no” a la mayoría de las preguntas siguientes, el particionamiento de tablas puede no ser la solución correcta para esa tabla.
- ¿Es la tabla suficientemente grande?
Las tablas grandes de hechos son buenas candidatas para realizar la partición de tablas. Si tenemos millones o miles de millones de registros en una tabla, podemos ver los beneficios de rendimiento al partir los datos en particiones lógicamente más pequeños. Dado que las tablas más pequeñas son menos susceptibles a problemas de rendimiento, la sobrecarga administrativa de mantenimiento de las particiones será superior a cualquier beneficio de rendimiento que podríamos ver mediante el particionamiento. - ¿Su aplicación o sistema mantiene una ventana de datos históricos?
Otra consideración para el diseño de particiones es la directiva de retención de datos de la organización. Como ejemplo, su almacén de datos puede requerir la retención datos de los últimos doce meses. Si los datos se dividen por mes, se puede eliminar de manera sencilla la partición mensual más antigua del almacén y cargar datos actuales en la partición mensual más nueva. - ¿Se está experimentando problemas de rendimiento en tareas de mantenimiento de bases de datos?
Cuando trabajamos con tablas más grandes, es más complicado realizar las operaciones de reconstrucción. En estos casos, se puede confiar en el particionamiento de tablas, de modo que las operaciones de mantenimiento se puedan realizar sin problemas. - ¿Pueden dividirse los datos en partes iguales en base a ciertos criterios?
Elija los criterios de partición que dividirán los datos de la manera más uniforme posible. Esto permitirá que el Optimizador de consultas SQL decida y seleccione el mejor plan para la ejecución de consultas. La partición mensual que se menciona en el segundo punto es un buen ejemplo de esto. - ¿Es la concurrencia un problema?
¿El sistema implica el manejo de un gran volumen de carga de datos e informes? ¿Se bloquean frecuentemente las consultas de los usuarios? Si es así, el particionamiento puede ser una opción para aliviar la situación, debido a que el optimizador de consultas sería capaz de manejar de mejor manera la ejecución.
Si alguien alguna persona realiza un reclamo respecto a la lentitud de una consulta, no es necesario que las tablas relacionadas sean particionadas. En muchos casos, el particionamiento no mejoraría el rendimiento. Una buena estrategia de indexación suele ser suficiente para la mayoría de los problemas de rendimiento de varios de estos casos de uso. Por ejemplo, si se realiza una consulta que utiliza una clave de partición, la ejecución de la consulta mejora; un deterioramiento en el rendimiento puede deberse a que no se utiliza la clave de partición en dicho escenario.
En las versiones anteriores de SQL Server, se requería de mucho esfuerzo adicional para poder restaurar la base de datos con tablas particionadas cuando se trataba de una edición no corporativa de SQL Server. Cualquier intento de restaurar resultaba en la caída de la función de partición y el esquema de partición antes del proceso de copia de seguridad y restauración de la base de datos. Esto no sucede en SQL 2016.
Las operaciones de truncamiento/supresión/reestructuración de datos tuvieron que basarse en el mecanismo de conmutación de particiones y de fusión. Sin embargo, con SQL Server 2016, se han introducido algunas características interesantes en el comando truncate, que sirven para poder eliminar los datos con un uso mínimo del log.
Soporte de funciones
La función de partición ha sido una característica de la edición Enterprise desde SQL 2005, pero por primera vez, se ha puesto a disposición en todas las ediciones desde SQL 2016.
| Característica | Empresa | Estándar | Web | Express with servicios avanzados | Express |
|
Tabla y
Particionamiento de índices | Si | Si | Si | Si | Si |
Sintaxis para truncar una tabla y como utilizarla
TRUNCATE TABLE y la opción WITH PARTITIONS() permite truncar los datos dentro del (de los) número(s) de partición definido(s) o un dentro de un rango de particiones.
|
1 2 3 4 5 6 7 8 9 |
TRUNCATE TABLE [ { database_name .[ schema_name ] . | schema_name . } ] table_name [ WITH ( PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ) ] [ ; ] <range> ::= <partition_number_expression> TO <partition_number_expression> |
-
Proporcione el número de partición, por ejemplo:
1TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2));
-
Proporcione los números de partición para varias particiones individuales separadas por comas, por ejemplo:
1TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (1,3,6))
-
Proporcione tantos rangos como múltiples particiones individuales, por ejemplo:
1TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (1,2, 4 TO 6));
-
Utilizando la palabra TO, los números de partición pueden estar separados por la palabra TO, por ejemplo:
1TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (4 TO 6));
¿Cómo y cuándo utilizar el comando truncate table con cláusula de partición?
La siguiente sección describe en qué escenario utilizar la opción Truncate Table para la eliminación de datos de una tabla particionada
El proceso de archivado/purga rápido implica el realizar el cambio de las particiones. Aunque Switch Partition es una operación de actualización de metadatos y no implica movimiento de datos físicos entre los archivos de datos existen casos como bases de datos transaccionales de alto tráfico que requieren bloqueos exclusivos, lo que hace bloquear la tabla para cargar y eliminar los datos.
Realizar la purga de datos (supresión) de particiones o particiones específicas era una tarea tediosa en versiones anteriores de SQL Server. Los datos creaban retrasos y bloqueaban la tabla, lo que evitaba que los usuarios consultaran la tabla; También se terminaba usando mucho espacio en el registro de transacciones. Antes de SQL 2016, se realizaron los siguientes pasos para poder eliminar los datos o archivos de la partición
- Crear una nueva tabla para modificar con la misma definición y el índice agrupado como de la tabla particionada
- Cambiar la partición a la otra tabla
- Modificar la función de partición y el esquema de particiones para eliminar el grupo de archivos
- Fusionando de acuerdo a los límites
- Eliminar el grupo de archivos
Nota: Hacer estos pasos es todo un reto cuando trabajamos con un gran número de filas
¿Qué tal introducir el nuevo comando TRUNCATE TABLE en este escenario?
Se trata de una forma muy sencilla y eficiente de eliminar las filas de la tabla particionada, ya que funciona como una operación normal para truncar una tabla.
- Ejecutar el comando TRUNCATE TABLE con cláusula de partición
- Ejecutar el comando MERGE
- Eliminar el grupo de archivos vacío
Demostración
En SQL Server 2016 se tiene la nueva característica para truncar datos a nivel de partición. Es bastante sencillo y simple. Vamos a mostrar los sencillos pasos para ver cómo funciona.
Cree una base de datos de ejemplo llamada powerSQLPartitionTest y agregue nuevos grupos de archivos. Estos archivos son una representación física de datos SQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
DROP DATABASE IF EXISTS powerSQLPartitionTest; GO CREATE DATABASE powerSQLPartitionTest; USE powerSQLPartitionTest GO --The following statements create filegroups to a database powerSQLPartitionTest ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2017] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2018] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2019] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2020] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2021] #Add one file to each filegroup so that you can store partition data in each filegroup ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2017’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2017.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2017] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2018’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2018.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2018] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2019’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2019.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2019] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2020’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2020.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2020] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2021’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2021.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB) TO FILEGROUP [Filegroup_2021] GO ---Create Partition Range Function as follows CREATE PARTITION FUNCTION powerSQLPartitionTest_PartitionRange (INT) AS RANGE LEFT FOR VALUES (10,20,30,40,50); GO ----Mapping partition scheme filegroups to the partition range function CREATE PARTITION SCHEME powerSQLPartitionTest_PartitionScheme AS PARTITION powerSQLPartitionTest_PartitionRange TO ([PRIMARY], [Filegroup_2017],Filegroup_2018,Filegroup_2019,Filegroup_2020,Filegroup_2021); GO --Now that there is a partition function and scheme, you can create a partitioned table. The syntax is very similar to any other CREATE TABLE statement except it references the partition scheme instead of a referencing filegroup CREATE TABLE powerSQLPartitionTestTable (ID INT NOT NULL, Date DATETIME default getdate()) ON powerSQLPartitionTest_PartitionScheme (ID); GO --Now that the table has been created on a partition scheme powerSQLPartitionTestTable , populate table using sample data Insert into powerSQLPartitionTestTable (ID) SELECT r_Number FROM ( SELECT ABS(CAST(NEWID() AS binary(6)) %1000) + 1 r_Number FROM master..spt_values) sample GROUP BY r_Number ORDER BY r_Number --- select Data from powerSQLPartitionTestTable SELECT * FROM powerSQLPartitionTestTable; GO --Next we can use $PARTITION function to retrieve row counts For each partition: SELECT $PARTITION.powerSQLPartitionTest_PartitionRange(ID) AS PARTITIONID, COUNT(* ) AS ROW_COUNT FROM dbo.powerSQLPartitionTestTable GROUP BY $PARTITION.powerSQLPartitionTest_PartitionRange(ID) ORDER BY PARTITIONID SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO --Truncate individual Partition TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2)); SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 |
--Truncate Multiple individual Partition TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (1,3)) GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 |
--Range of Parititions TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (4 TO 6)); GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 |
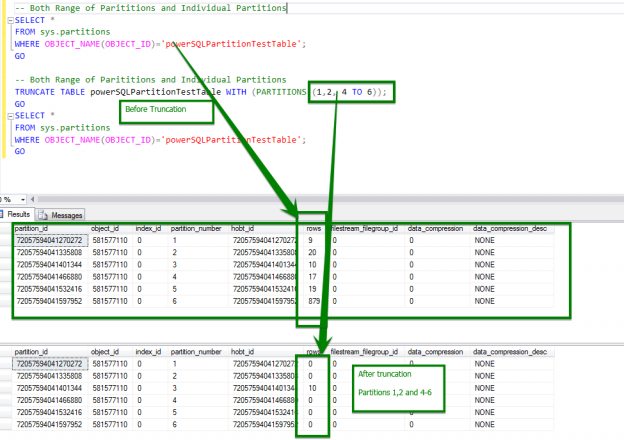
-- Both Range of Parititions and Individual Partitions TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (1,2, 4 TO 6)); GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 |
--Remove files from Partitioned table using truncate enhancemen |
The below SQL gives SQL partition internal details
|
1 2 3 4 5 |
SELECT $PARTITION.powerSQLPartitionTest_PartitionRange(ID) AS PARTITIONID, COUNT(* ) AS ROW_COUNT FROM dbo.powerSQLPartitionTestTable GROUP BY $PARTITION.powerSQLPartitionTest_PartitionRange(ID) ORDER BY PARTITIONID |

|
1 |
--The filegroup_2017 is ready for data deletion by using truncate command |

|
1 2 |
--Truncate individual Partition TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2)); |

Ahora, filegroup_2017 está vacío y listo para ser eliminado. Asegúrese de que la dependencia han sido eliminadas en cada sección que las utilizaba. Una vez que se haga esto, unir en el punto de límite eliminará la entrada de la función de partición:
|
1 2 |
--Merge the range in order to get rid of the data filegroup_2017 ALTER PARTITION FUNCTION powerSQLPartitionTest_PartitionRange() MERGE RANGE (200); |

|
1 |
ALTER DATABASE powerSQLPartitionTest REMOVE FILE data_2017 |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
--Online Index Maintenantenance on ALL Paritions ALTER INDEX PK_powerSQLPartitionTestTable_IDX ON [dbo].powerSQLPartitionTestTable REBUILD PARTITION = ALL WITH (ONLINE= ON); --Online Index Maintenantenance on Parition 3 ALTER INDEX PK_powerSQLPartitionTestTable_IDX ON [dbo].powerSQLPartitionTestTable REBUILD PARTITION = 3 WITH (ONLINE= ON); |

Conclusión
En el presente artículo, se detalla el uso de particiones en SQL Server y que factores son de vital importancia al considerar antes de poder particionar una tabla. También se describe el uso de las mejoras del comando truncate table con particiones. Con SQL Server 2016, se puede planificar un mejor mantenimiento de índices y estrategias para realizar la administración de datos.
Referencias
- Ediciones y funciones compatibles para SQL Server 2016
- Tablas e índices particionados
- TRUNCATE TABLE (Transact-SQL)
- Particionamiento de tablas de base de datos en SQL Server

Mi especialidad es el diseño y la implementación de soluciones de alta disponibilidad y la migración de bases de datos multiplataforma. Las tecnologías en las que trabajo actualmente son SQL Server, PowerShell, Oracle y MongoDB.
Ver todas las publicaciones de Prashanth Jayaram
- Descripción general de la función SQL CAST y SQL CONVERT - December 6, 2019
- Revisión del operador relacional y descripción general dePivot y Unpivot estático y dinámico de SQL - November 6, 2019
- Revisión, ejemplos y uso de SQL Union - November 4, 2019