

SQL Data Sync es un servicio que nos permite poder sincronizar datos a través de las múltiples bases de datos SQL de Azure y bases de datos de SQL Server locales.
En este artículo, le vamos a explicar el concepto básico de cómo funciona el servicio de sincronización de datos de SQL y cuáles son los requisitos y las limitaciones cuando se desea crear una sincronización de datos mediante el uso de la sincronización de datos de SQL.
Para así poder sincronizar los datos y el período, es necesario poder crear el grupo de sincronización y definir cuáles son las bases de datos, las tablas y las columnas.
El concepto básico de sincronización de datos con SQL Data Sync se puede ver en la siguiente imagen:

SQL Data Sync usa una topología de radios de hub para sincronizar los datos. En el grupo de sincronización (por ejemplo, Grupo de sincronización 1), una base de datos se define como la base de datos del concentrador (debe ser una base de datos SQL de Azure) y el resto de las bases de datos del grupo de sincronización son las bases de datos de los miembros. La sincronización de datos se muestra solo entre el concentrador y la base de datos miembro individual.
Las bases de datos de miembros pueden ser bases de datos SQL de Azure, bases de datos de SQL Server local o instancia de SQL Server en máquinas virtuales de Azure.
La dirección de sincronización de datos (Sync) puede ir en ambas direcciones (bidireccional) o en una, desde la base de datos central a una base de datos miembro (Hub to Member) y viceversa, desde una base de datos miembro a la base de datos hub (Member to Hub)
Para poder sincronizar los datos entre SQL Server local y la base de datos de Azure (Hub), el agente de sincronización local tiene que instalarse en la máquina local. Este agente se comunica entre el concentrador y la base de datos de SQL Server local. Para más información sobre cómo instalar y configurar el Agente de sincronización de datos de SQL Azure se explica en el artículo Cómo sincronizar la base de datos de Azure y la base de datos local con SQL Data Sync.
Todas las bases de datos miembros con la base de datos central y el agente de sincronización forman un grupo de sincronización.
El grupo de sincronización se definirá en una misma región que la base de datos central (por ejemplo, la región de Europa Occidental)
Adicionalmente, necesitamos otra base de datos para poder almacenar todos los metadatos y registros (Sincronizar base de datos). La base de datos de sincronización debe de estar en la misma región que el grupo de sincronización.
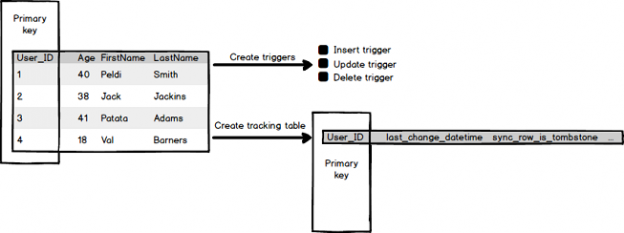
Cuando se genera el grupo de sincronización, algunos objetos de la base de datos se crearán en la base de datos de producción para verificar los cambios para cada tabla que se sincroniza.
Esos objetos son actualizar, insertar, eliminar activadores:

También, se crea una tabla de seguimiento para poder rastrear los otros cambios que se hicieron en sus tablas. Esta tabla de seguimiento tendrá la misma clave principal que se define en la tabla de seguimiento. La tabla de seguimiento tiene otras columnas, pero las dos columnas más importantes son las siguientes:

- last_change_datetime – indica cuándo se cambió la clave principal por última vez
- sync_row_is_tombstone – indica cuándo se elimina la fila de la tabla base (rastreada)

Cuando el nuevo registro se inserta en una tabla de seguimiento, se creará un nuevo registro con la misma clave principal en la tabla de seguimiento para rastrear los cambios:

Entonces, el usuario Jack (ID_usuario = 2) cambia (actualiza) la edad en la fila Edad y, si se hace por primera vez, el nuevo registro en la tabla de seguimiento se creará con el ID_usuario = 2:

Sin embargo, si en la tabla rastreada se elimina la fila con un ID_de_usuario = 5, entonces en la tabla de seguimiento para el ID_de_usuario = 5 debajo de la columna sync_row_is_tombstone, el valor cambiará de 0 a 1 para indicar que se eliminó la fila:

Entonces el SQL Data Sync crea procedimientos almacenados para poder seleccionar y aplicar cambios y agregar un tipo de tabla definido por el usuario, que también se usa para poder realizar cambios masivos:

La base de datos central se sincroniza con cada miembro por separado. Los cambios de la base de datos central se descargarán a una base de datos miembro y los cambios de una base de datos miembro se cargarán a la base de datos central.
En el caso de conflictos, existen las opciones de victorias de Hub y victorias de miembros para la resolución de conflictos:
- La opción de ganancias del concentrador siempre sobrescribe los cambios en una base de datos miembro
- El miembro gana opciones siempre sobrescribe los cambios en la base de datos central. En caso de que en el grupo de sincronización haya más miembros, el último valor depende de qué miembro sincroniza primero
Requerimientos
Para cada tabla que se debe sincronizar debe contener una columna de clave principal
En el caso de que sea necesario cambiar el valor de la clave principal, hay que eliminar esa columna y luego vuelva a crearla con el nuevo valor de la clave principal.
El aislamiento de instantáneas debe estar habilitado:
|
1 2 3 4 5 |
ALTER DATABASE Database SET ALLOW_SNAPSHOT_ISOLATION ON ALTER DATABASE Database SET READ_COMMITTED_SNAPSHOT ON |
De lo contrario, puede aparecer la siguiente excepción cuando intente sincronizar la base de datos:

Limitaciones
- Una columna de identidad que no es una columna con una clave principal, no se puede usar en las tablas que deben sincronizarse.
- El tipo de datos datetime no se puede utilizar para una clave principal.
- Las tablas máximas en un grupo de sincronización son de 500.
- Las columnas máximas que una tabla puede tener en un grupo de sincronización son de 1000.
- El intervalo mínimo de sincronización es de por lo menos 5 minutos.
- La sincronización de datos SQL no admite la autenticación de Active Directory de Azure.
Puedes buscar más información sobre los requisitos y limitaciones de la sincronización de datos SQL en los datos de sincronización en múltiples bases de datos en la nube y locales con la página de sincronización de datos de SQL.
Permisos
Las operaciones de sincronización de SQL Data Sync requieren los siguientes permisos:
- Crear permisos de tabla para poder crear tablas de metadatos (scope_info_dss, scope_config_dss, schema_dss, y provision_marker_dss) y tablas de seguimiento (tabla name_dss_tracking):

- Modifique los permisos de la tabla para poder crear activadores Insertar, Actualizar, Eliminar en las tablas que deben sincronizarse:

- Poder crear permisos de procedimiento para crear los procedimientos que utiliza SQL Data Sync.
- Seleccionar los permisos para las tablas scope_info_dss, scope_config_dss, schema_dss y provision_marker_dss.
- Insertar los permisos para las tablas scope_info_dss, scope_config_dss, schema_dss y provision_marker_dss.
- Seleccionar los permisos para la tabla que se debe sincronizar.
- Se requieren los permisos de selección, inserción, actualización y eliminación para las tablas que deben actualizarse durante el proceso de sincronización y para las tablas de metadatos.
- Permisos ejecutados para los procedimientos almacenados que SQL Data Sync utiliza para poder leer y escribir en tablas de metadatos y tablas que deben sincronizarse.


Actualmente trabajando para ApexSQL LLC como un Ingeniero de Ventas de Software, él está ayudando a los clientes con problemas técnicos y hace aseguramiento de calidad para los complementos ApexSQL Complete, ApexSQL Refactor y ApexSQL Search.
Ver todas las entradas de Marko Zivkovic