
In our previously published article in this series, we explained how to migrate SQL Server graph tables into Neo4j and why migration could be beneficial. We only mentioned how to migrate node and edge tables, and we did not mention indexes and constraints. This article is an extension of the previous one, where we will explain how to export the supported indexes and constraints from SQL Server to the Neo4j graph database. In addition, all codes are added to the project we already published on GitHub.
Before getting started
One thing worth mentioning is that this article has nothing to do with edge constraints introduced in SQL Server 2019. It is good to know that SQL Server does not provide a native graph database; they have added graph capabilities on the relational data model’s top. Later, edge constraints were added to prevent edge tables from storing more than one type of relation useless in a native graph database where no tables are found, and data is stored as JSON.
If you are interested to learn more about SQL Server 2019 edge constraints, you can refer to the following article: Graph Database features in SQL Server 2019 – Part 1.
Exporting Indexes
As we mentioned in the introduction, we can export only supported types of indexes from SQL Server to the Neo4j graph database. One of the good points of adding graph capabilities to the SQL Server database engine is that most of the relational data features can be applied to those tables, such as portioning, adding non clustered column store indexes, filtered indexes…
Like SQL Server indexes, a database index in Neo4j is a redundant copy of some of the data in the database to make searches of related data more efficient. Three types of indexes are available:
- Single property index: It is a named index on a single property for all nodes with a particular label
- Composite index: It is a named index on multiple properties for all nodes with a particular label
- Full-text indexes: Powered by Apache Lucene and used to index nodes and relationships by string properties
This means that not all SQL Server indexing features are supported in Neo4j; we cannot add column stores or filters. This section mentions three types of indexes to migrate from SQL Server: non-clustered indexes, unique indexes, full-text search indexes. Since all rowstore indexes will be migrated using the same method, they will be illustrated together, while full-text indexes migration is explained separately.
- Note: We ignored clustered indexes since they contain all columns in the table, while we really don’t know if it is useful to recreate them in a graph database. Besides, unique indexes will be migrated as a regular index to the graph database, and a unique constraint will be added later (more details in the next section)
Preparing the test environment
All experiments in this tutorial are executed over the environment we were working within the previous article. One change we made is to add an extra column on the “Likes” edge table and to create two non-clustered indexes using the following SQL command:
|
1 2 3 4 |
ALTER TABLE [dbo].[Likes] ADD Last_Updated DATETIME NULL; CREATE NONCLUSTERED INDEX [IX_CityName] ON [dbo].[Cities]([CityName] ASC) INCLUDE (CityID); CREATE NONCLUSTERED INDEX [IX_LastUpdated] ON [dbo].[Likes](Last_Updated ASC) ; CREATE UNIQUE NONCLUSTERED INDEX [IX_CityID] ON [dbo].[Cities]([CityID] ASC); |
Non-Clustered rowstore indexes
To recreate Rowstore indexes, we need to retrieve the following metadata for each one:
- The table name
- Is it a node or edge table?
- The index name
- The list of columns
- The order of columns
We used the following query to retrieve that information from SQL Server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SELECT TableName = t.name, Is_Node = t.is_node, Is_Edge = t.is_edge, IndexName = ind.name, ColumnName = Col.name , ColumnOrder = ic.key_ordinal FROM sys.indexes ind INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id and ind.index_id = ic.index_id INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id INNER JOIN sys.tables t ON ind.object_id = t.object_id WHERE ind.type = 2 -- Only retrieve non-clustered rowstore indexes and (t.is_node = 1 or t.is_edge = 1) -- Retrieve indexes create on graph tables only and col.name not like 'graph_id_%' and t.name <> 'sysdiagrams' -- Ignore system indexes and ind.is_unique = 0 and ind.is_unique_constraint = 0 -- ignore unique indexes ORDER BY t.is_node, t.name, ind.name, ic.key_ordinal |
In the where clause, we ignored all system indexes since they are useless in our case.

Figure 1 – Available indexes in the database
To facilitate our migration process and to minimize the line of codes in our project, we generated the Cypher statement via SQL to be executed later within the C# project.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT 'CREATE INDEX ' + ind.name + ' FOR (t:' + t.name +') ON (' + STRING_AGG('t.' + Col.name,',') + ')' FROM sys.indexes ind INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id and ind.index_id = ic.index_id INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id INNER JOIN sys.tables t ON ind.object_id = t.object_id WHERE ind.type = 2 -- Only retrieve non-clustered rowstore indexes and (t.is_node = 1 or t.is_edge = 1) -- Retrieve indexes create on graph tables only and col.name not like 'graph_id_%' and t.name <> 'sysdiagrams' -- Ignore system indexes and ind.is_unique = 0 and ind.is_unique_constraint = 0 -- ignore unique indexes GROUP BY ind.name, t.name |
The result of this query should look like the following:

Figure 2 – Cypher create index statements
Unique Indexes
Unique indexes are also non-clustered indexes where a unique constraint is forced on the indexed columns. Both SQL Server and Neo4j automatically create an index on the columns/properties added in a unique constraint. For this reason, we ignored unique indexes from the migration process since they will be auto-generated after exporting unique constraints.
Full-text indexes
In Neo4j, full-text indexes are created using two stored procedures:
- Nodes tables: db.index.fulltext.createNodeIndex()
- Edges tables: db.index.fulltext.createRelationshipIndex()
Like what we have done for regular indexes, we can directly use an SQL statement in SQL Server to generate the Cypher statement to create full-text indexes in the graph database. The main difference is that we should split the full-text indexes that are created over Nodes and Edges at the same time in SQL Server since this is not allowed in NoSQL.
We can use the following SQL statement to generate the relevant Cypher code (we added a prefix to the indexes names to prevent index name duplicates error in Neo4j):
|
1 2 3 4 5 6 7 8 9 |
SELECT 'db.index.fulltext.' + case t.is_node when 1 then 'createNodeIndex("N_' else 'createRelationshipIndex("Rel_' end + cat.name + '", [' + STRING_AGG('"' + t.name + '"',',') + '], [' + STRING_AGG('"' + col.name + '"',',') + '])' FROM sys.fulltext_catalogs cat INNER JOIN sys.fulltext_indexes ind ON cat.fulltext_catalog_id = ind.fulltext_catalog_id INNER JOIN sys.fulltext_index_columns ic ON ind.object_id = ic.object_id INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id INNER JOIN sys.tables t ON ind.object_id = t.object_id WHERE (t.is_node = 1 or t.is_edge = 1) AND col.name not like 'graph_id_%' and t.name <> 'sysdiagrams' GROUP BY t.is_node, cat.name |
To Test this SQL statement, we added a description column to the StadiumCities edge table. Then, we create a full-text catalog named “City_Teams”, where we indexed two Node tables (Cities, Teams) and one Edge table (StadiumCities).

Figure 3 – Generate Cypher full-text indexes creation statements
Exporting Constraints
In the Neo4j graph database, there are four types of constraints:
- Unique node property constraints
- Node property existence constraints
- Relationship property existence constraints
- Node key constraints
Noting that only unique node property constraints are available in the community edition, while all others are only available in the enterprise edition.
Unique node property constraints
In SQL Server, unique constraints can be created over multiple columns, while in Neo4j, this type of constraint can be created for one column. This means that we cannot migrate unique constraints for multiple columns. However, since SQL Server’s unique constraints are defined as unique indexes – even if created using constraints, a unique index is created automatically – we will use the following statement to retrieve all unique constraints created over one column and generate the relevant Cypher statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT 'CREATE CONSTRAINT UC_' + ind.name + ' ON (n:' + t.name + ') ASSERT n.' + col.name + ' IS UNIQUE' FROM sys.indexes ind INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id and ind.index_id = ic.index_id INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id INNER JOIN sys.tables t ON ind.object_id = t.object_id WHERE ind.type = 2 -- Only retrieve non-clustered rowstore indexes and (t.is_node = 1 or t.is_edge = 1) -- Retrieve indexes create on graph tables only and col.name not like 'graph_id_%' and t.name <> 'sysdiagrams' -- Ignore system indexes and (ind.is_unique = 1 or ind.is_unique_constraint = 1) -- only retrieve unique indexes GROUP BY ind.name,t.name,col.name HAVING COUNT(*) = 1 |
In our example, this statement will generate the following result:

Figure 4 – Cypher create a unique constraint generated statement
- Note: Adding a unique property constraint on a property will also add a single-property index on that property, so such an index cannot be added separately.
Node/Relationship property existence constraints
In SQL Server, the existing constraints are defined using the “NOT NULL” property that can be added to a column. To generate the Cypher create constraints statements we used the following SQL Command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
select CASE WHEN t.is_node = 1 then 'CREATE CONSTRAINT ' + t.name + '_' + col.name + '_exist ON (n:' + t.name + ') ASSERT EXISTS (n.' + col.name + ')' ELSE 'CREATE CONSTRAINT ' + t.name + '_' + col.name + '_exist ON ()-"["R:' + t.name + '"]"-() ASSERT EXISTS (R.' + col.name + ')' END FROM sys.columns col INNER JOIN sys.tables t ON col.object_id = t.object_id where col.is_nullable = 0 -- columns that doesn't allows nulls and col.graph_type IS NULL -- Ignore graph system columns and (t.is_edge = 1 or t.is_node = 1) -- only retrieve graph tables and not exists (select * from sys.index_columns ic inner join sys.indexes ind on ic.index_id = ind.index_id and ind.object_id = ic.object_id where ind.is_primary_key = 1 and ic.column_id = col.column_id and t.object_id = ind.object_id and t.is_node = 1) -- ignore node table primary keys |
This command will generate the following result:

Figure 5 – Cypher create existence constraints statements
We ignored the node table primary key columns since they are related to the Node key constraints. Since there are no Edge keys, we generated an existence constraint for the Edge tables’ primary keys.
Node key constraints
We will consider that the Node Key constraints in the graph databases are defined using Primary key constraints in SQL Server. We can use the following SQL statement to generate the relevant Cypher statements:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
select 'CREATE CONSTRAINT NKC_' + t.name + ' ON (n:' + t.name + ') ASSERT (' + STRING_AGG('n.' + col.name,',') + ') IS NODE KEY' FROM sys.indexes ind INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id and ind.index_id = ic.index_id INNER JOIN sys.tables t ON ind.object_id = t.object_id INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id where graph_type IS NULL -- Ignore graph system columns and t.is_node = 1 -- only retrieve node tables and ind.is_primary_key = 1 --only primary keys GROUP BY t.name |
This SQL statement will generate the following result:

Figure 6 – Cypher create node keys constraints generated statements
- Note: Adding a node key constraint for a set of properties will also add a composite index on those properties, so such an index cannot be added separately
Adding Indexes and constraints migration functions to the project
After providing the SQL commands used to generate the Cypher statement used in the database migration process, we have to use those states in the C# project we created in the previous article.
First, we created a new static class called “SQLCommands” to store the five SQL statements needed to migrate indexes and constraints. Then in the SQLReader class, we added one function to execute each SQL command and to store the result within a list of strings:
- GetIndexes
- GetFullTextIndexes
- GetUniqueConstraints
- GetExistenceConstraints
- GetNodeKeyConstraints
In the Neo3jWriter class, we added three functions to execute the Cypher statements generated and stored within the SQLReaderClass:
- ImportIndexes
- ImportFullTextIndexes
- InportConstraints
The migration code should look like the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
using (SQLReader reader = new SQLReader("Server=<machine name>\\<instance name>;Database=GraphPL;Trusted_Connection=yes;")) { reader.GetNodes(); reader.GetEdges(); reader.GetIndexes(); reader.GetFullTextIndexes(); reader.GetUniqueConstraints(); //reader.GetExistenceConstraints(); -- available only in enterprise edition //reader.GetNodeKeyConstraints(); -- available only in enterprise edition using (Neo4jWriter importer = new Neo4jWriter(new Uri("http://<user>:<password>@localhost:7474"))) { importer.ImportNodes(reader.Nodes); importer.ImportEdges(reader.Edges); importer.ImportIndexes(reader.Indexes); importer.ImportFullTextIndexes(reader.FullTextIndexes); importer.ImportConstraints(reader.UniqueConstraints); //importer.ImportConstraints(reader.ExistenceConstraints); -- available only in enterprise edition //importer.ImportConstraints(reader.NodeKeyConstraints); -- available only in enterprise edition } } |
We converted the line of code related to the existence and node key constraints to comments since they are not supported in the community edition where we are running our experiments.
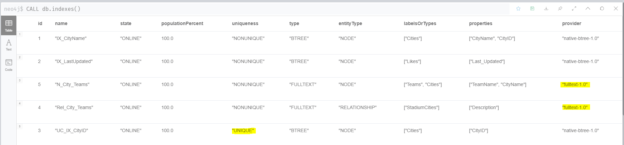
After running the code, we can check that all indexes were migrated successfully using CALL db.indexes(); command:

Figure 7 – List all indexes
If we execute the CALL db.constraints() stored procedure, we can check that all constraints are migrated successfully.

Figure 8 – List created constraints
Conclusion
This article is considered to be an extension of the previously published article in this series. We explained how to export the supported indexes from SQL Server graph tables into a Neo4j graph database by generating Cypher queries using SQL Statement and executing them using a .NET code.
Table of contents
| Import data from MongoDB to SQL Server using SSIS |
| Getting started with the Neo4j graph database |
| Migrating SQL Server graph databases to Neo4j |
| Export indexes and constraints from SQL Server graph databases to Neo4j |
| Migrating SQL Server graph databases to ArangoDB |

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023