

Introduction
In a previous article, Functions vs stored procedures in SQL Server, we compared Functions vs stored procedures across various attributes. In this article, we will continue the discussion. We will talk also about Table-valued functions and compare performance with stored procedures with table valued functions and scalar functions.
We will include the following topics:
- Manipulating stored procedure results and Table valued functions
- Comparing performance of stored procedures and Table valued functions with a where clause
- Are the scalar functions the devil’s sons?
Getting started
1. Manipulating stored procedure results and Table valued functions
To store data retrieved from a stored procedure in a table when we invoke it, it is necessary to create the table first and then insert the data from the stored procedure to the table.
Let’s take a look to an example. First, we will create a stored procedure that returns a select statement:
|
1 2 3 4 5 6 7 8 9 10 11 |
create procedure tablexample as select [AddressID], [AddressLine1], [AddressLine2], City from [Person].[Address] |
This is a procedure named tableexample and it returns select information of the table Person.Address included in the Adventureworks databases mentioned in the requirements.
After creating the stored procedure, you need to create a table where you will store the data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE [Person].[Address2]( [AddressID] [int] NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL CONSTRAINT [PK_Address_AddressID2] PRIMARY KEY CLUSTERED ( [AddressID] ASC ) ) ON [PRIMARY] GO |
Finally, you can do an insert into table and invoke the stored procedure:
|
1 2 3 4 |
insert into Person.Address2 exec tablexample |
As you can see, it is possible to invoke a stored procedure and retrieve the data using insert into.
If we try to do an insert into from a stored procedure to create automatically the table we will have the following result:
|
1 2 3 4 |
exec tablexample into Person.Address3 |
When we try to insert into a table the result of the stored procedure invocation, we have the following message:
Msg 156, Level 15, State 1, Line 170
Incorrect syntax near the keyword ‘into’.
Let’s create a table valued function and compare it with the stored procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE FUNCTION dbo.functiontable( ) RETURNS TABLE AS RETURN ( select [AddressID], [AddressLine1], [AddressLine2], City from [Person].[Address] ) |
This function named functiontable returns the information from a Person.Address table. To invoke a table valued function, we can do a select like this:
|
1 2 3 4 |
select * from dbo.functiontable() |
The table valued function can be used like a view. You can filters the columns that you want to see:
|
1 2 3 4 |
select AddressID from dbo.functiontable() |
You can also add filters:
|
1 2 3 4 |
select AddressID from dbo.functiontable() where AddressID=502 |
If you want to store the functions results, you do not need to create a table. You can use the select into clause to store the results in a new table:
|
1 2 3 4 5 |
select * into mytable from dbo.functiontable() |
As you can see, you do not need to create a table as we did with the stored procedures. If you go to the Object Explorer in SSMS, you will be able to see that the table mytable was created successfully:

2. Comparing performance of stored procedures and Table valued functions with a where clause
Some developers claim that stored procedures are faster than Table valued functions. Is that true?
We will create a table with a million rows for this test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
with randowvalues as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*100 as int) randomnumber union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*100 as int) randomnumber from randowvalues where id < 1000000 ) select * into mylargetable from randowvalues OPTION(MAXRECURSION 0) |
The code creates a table named mylargetable with a million rows with values from 1 to 100.
We will create a function that returns the values according to a filter specified by a parameter:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE FUNCTION dbo.functionlargetable(@rand int) RETURNS TABLE AS RETURN ( select randomnumber from mylargetable where randomnumber=@rand ) |
This function named functionlargetable will show randomnumbers equal to the parameter specified.
Before running the query, enable the Actual Execution option in SSMS:

The following query will show random numbers equal to 59:
|
1 2 3 |
select randomnumber from dbo.functionlargetable(59) |
The Actual Execution plan will show how the query was executed (which indexes were used, cost of the sentences, etc.):

We will compare the execution plan of the function to a stored procedure:
|
1 2 3 4 5 6 7 8 |
CREATE PROCEDURE storedwithlargetable @rand int as select randomnumber from mylargetable where randomnumber=@rand |
The procedure is showing the random numbers equal to a parameter.
We will invoke the stored procedure:
|
1 2 3 |
exec storedwithlargetable 61 |
If we check the actual plan, we will have the following:

As you can see, the execution plan is the same. However, it is always a good practice to check the execution time.
To check more detailed information about execution time run these sentences:
|
1 2 3 4 5 |
SET STATISTICS io ON SET STATISTICS time ON GO |
We run the functions and stored procedure cleaning the buffer using these sentences:
|
1 2 3 4 |
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET NOCOUNT ON |
Here you have the table of results of the function invocation time:
| CPU Parse time (ms) | Elapsed Parse time (ms) | Execution CPU time (ms) | Execution (ms) | Total (ms) |
| 16 | 90 | 313 | 1325 | 1744 |
| 16 | 43 | 390 | 1053 | 1502 |
| 0 | 47 | 328 | 1884 | 2259 |
| 0 | 133 | 344 | 1814 | 2291 |
| 0 | 273 | 391 | 1500 | 2164 |
| Average: 1992 |
In addition, here you have the execution time of the stored procedure:
| CPU Parse time (ms) | Elapsed Parse time (ms) | Execution CPU time (ms) | Execution (ms) | Total (ms) |
| 0 | 143 | 1300 | 1818 | 3261 |
| 1 | 0 | 250 | 1481 | 1731 |
| 0 | 0 | 328 | 1231 | 1559 |
| 0 | 0 | 328 | 1542 | 1870 |
| 16 | 276 | 313 | 1525 | 2130 |
| Average: 2110 |
As you can see, the average time is 1992 ms for the function and 2110 ms for the stored procedures. The performance is almost the same. So, it is safe to use Table-valued UDFs in this case.
3. Are the scalar functions evil?
Some say scalar functions are the spawn of the devil  We’ll test to see if this bad reputation is warranted
We’ll test to see if this bad reputation is warranted
We are going to use a stored procedure with a computed column. The computed column will convert USD to Mexican Pesos. The formula will be the following:
|
1 2 3 |
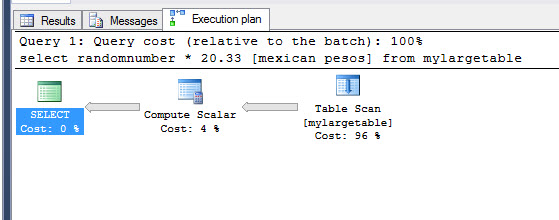
select randomnumber * 20.33 [mexican pesos] |
1 USD dollar will be 20.33 pesos.
The stored procedure will be the following:
|
1 2 3 4 5 6 |
create procedure largetableproc as select randomnumber * 20.33 [mexican pesos] from mylargetable |
We are using the table mylargetable created in the section 2.
We can invoke the procedure to test results:
|
1 2 3 |
exec largetableproc |
The execution plan will be the following:

Let’s compare the results with a function:
|
1 2 3 4 5 6 7 8 9 |
CREATE FUNCTION priceinpesos(@dollar real) RETURNS real AS BEGIN RETURN @dollar*20.33 END |
The function converts dollar to Mexican Pesos.
Let’s run a query using the scalar function just created:
|
1 2 3 4 |
select dbo.priceinpesos( randomnumber) as [Mexican Pesos] from mylargetable |
If we check the executing plan using the scalar function, we will notice the following:

As you can see, in many cases, the execution plan to run queries is the same in functions than in stored procedures. It is not always the case. However, how is the execution time?
The execution time of a stored procedure is 38 seconds:

Here you have a comparison table of procedures vs scalar functions:
| Stored procedure execution time (s) | Function execution time (s) |
| 43 | 50 |
| 38 | 59 |
| 27 | 61 |
| 36 | 59 |
| 35 | 58 |
| Average: 35.8 | Average: 57.4 |
As you can see, the scalar functions are slower than stored procedures. In average, the execution time of the scalar function was 57 seconds and the stored procedure 36 seconds.
Conclusions
We conclude that the table-valued functions are more flexible to filter results horizontally and vertically, to use a select into. Stored procedures are less flexible to reuse the results.
In terms of performance, table-valued functions are a good choice. The performance is basically the same than stored procedures. However, it depends on the situation. Always check the execution time, Execution plan and test your functions and procedures with big amounts of data. Check our article to generate random values for testing.
Scalar functions can be used if you are sure that there are not many rows. When there are millions of rows or more, the execution time of scalar functions can be very slow.
References
For more information, refer to these links:
- T-SQL User-Defined Functions: the good, the bad, and the ugly (part 1)
- Performance Considerations of User-Defined Functions in SQL Server 2012
- How to generate random SQL Server test data using T-SQL
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023