
Summary
SQL Server Agent allows us to create jobs and assign any number of schedules to them. This allows for great flexibility when deciding when jobs should run. Over time, as the number of jobs and schedules increase on a given SQL Server, it can become challenging to fully understand when and how often jobs run during a given span of time.
A common need is to be able to quickly generate a list of jobs that will run during a given time frame. Knowing what jobs run when (and how often) can allow us to better plan maintenance events and ensure we do not miss anything important when SQL Server Agent is not running.
Our goal in this article will be to build a stored procedure that will generate that job run list for any time frame and provide as much detail as we need when executed. While this sounds simple enough, we will need to delve into job schedules within MSDB, which will inherently be a bit messy.
Prerequisites
A calendar table will be used in our code to allow us to quickly parse dates and assign metrics such as day of week and week of month. Here, we’ll use the calendar table introduced in a previous SQL Shack article: Designing a Calendar Table
If you already have your own calendar table that you are fond of, feel free to use it in place of this as the data is relatively easy to crunch and we are only using a few columns of the dimension table to get what we need.
Planning and Notes
Before diving in, let’s take a moment to plan our attack on this problem. What do we want to accomplish through our efforts here? What pitfalls should we watch out for while designing this?
All dates and times stored in MSDB are stored in the local server time zone. This means that sharing data across servers or converting from UTC may be problematic. To help keep this simple, we’ll build our process to accept and return data in both UTC and local time zones. This will ease the burden of converting between time zones, in the event that a server is not running under UTC time.
Jobs may be assigned many kinds of schedules. We’ll want to address all of them as follows:
- Daily jobs that are run every day, or on a subset of days each week
- Weekly jobs that are run each week on designated days
- Monthly jobs that are run on a specific set of days during the month
- One-time jobs that are intended to run once and never again
- Jobs that run multiple times during any of the above schedules
- Jobs that run at agent startup or when the server is idle (for reporting purposes)
We can return detailed data about each scheduled job run, but will also want to be able to roll that data up into a smaller data set. If a job runs every five minutes, then getting a row back per execution may be overkill if we examine a longer time period. As a result, the ability to return detail data or summarize will be useful in our result set.
Since a job can have multiple schedules, we should treat each job & schedule combination as a distinct entity. This will ensure we capture job runs triggered by all of the schedules used within a job.
One final bonus we can return with our results is the job schedule definitions for each job. This will allow us to easily understand why a job runs when it does and plan ahead to figure out what other time periods may look like.
The script attached to this article includes the calendar table creation as well as a full, working stored procedure that generates job schedules based on the code and snippets discussed below. Feel free to jump ahead to the download to use as a reference while reading this article.
MSDB Objects
SQL Server Agent jobs, schedules, and run history are all stored in the MSDB system database. The design of these tables hasn’t changed much over the years, and as a result their contents are a bit challenging to read. The following is a list of the schema within MSDB that we will use for our work:
Sysjobs: This table contains a row per job defined in SQL Server Agent. Included are columns that define the job name, description, if it is enabled, its category, start step, create/modified date, and a variety of other settings that impact overall job function.
Sysschedules: This table contains a row per schedule defined in SQL Server. Included are the name, description, if it is enabled, start/end dates, start end/times, and a variety of bitwise columns that describe how and when it runs. This table is inherently hard to read, so reviewing some of the less-obvious columns will be valuable here:
- Freq_type: This will be a number from the following list that indicates how often the job runs: 1 = One-Time, 4 = Daily, 8 = Weekly, 16 = Monthly (on specific days), 32 = Monthly-Relative (On a given time of month, such as the 3rd Tuesday or last Friday) , 64 = On SQL Server Agent startup, and 128 = When the server is idle
- Freq_interval: If a schedule occurs every N days/weeks or in a given day/week of the month, then freq_interval will indicate that frequency of execution, otherwise it indicates which days of the week a job occurs. For days of the week, those days are given as a binary summation of: 1 = Sunday, 2 = Monday, 4 = Tuesday, 8 = Wednesday, 16 = Thursday, 32 = Friday, and 64 = Saturday. For example, 127 would indicate a job that runs every day whereas 13 would indicate a job that executes on Sunday, Tuesday, and Wednesday
- Freq_subday_type: If 1, then a job runs at a specific time only. If a job runs every N seconds, minutes, or hours, then this will be set to 2 for seconds, 4 for minutes, or 8 for hours. 0 indicates that this is unused, such as for a job that runs when SQL Server Agent starts
- Freq_subday_interval: If freq_subday_type indicates a job that runs every N seconds/minutes/hours, then this column will have a number that tells us how many seconds/minutes/hours will pass between job runs
- Freq_relative_interval: If a job occurs on the Nth day of a month, then this indicates what N is. 0 = unused (for other schedule types), 1 = 1st, 2 = 2nd, 4 = 3rd, 8 = 4th, and 16 = last
- Freq_recurrence_factor: If a job occurs every N weeks or months, then this column indicates what N is. 0 means it is not used for a given schedule type. This is only used for daily, weekly, or monthly schedules
- Active_start_date & Active_end_date: These tell us when a job is active and will run. If the current date is outside of this range, then the job will not run
- Active_start_time & Active_end_time: These provide boundaries of when the job should execute during the day. If the current time is not within this range, then the job will not run
Because this data is difficult to decipher, we’ll convert into easy-to-understand descriptions early in our process. This will make our code easier to understand, easier to customize, and reduce the chances of us making mistakes along the way.
Sysjobschedules: This is a linking table that relates jobs to schedules. A job may be referenced more than once in this table if it has multiple schedules.
Syscategories: This table contains a list of all categories defined within SQL Server Agent. Job categories can be used to classify jobs to make them easier to group and understand. We include this for informational purposes, but categories can be used to customize monitoring and alerting based on a job’s purpose or importance.
Agent_datetime (YYYYMMDD year, HHMMSS time): This function is not well documented, but converts the integer dates/times stored in many MSDB tables (such as sysschedules) into a DATETIME. This is a huge convenience and will save us the need to write a messy pile of TSQL to perform this conversion. For informational purposes, here is the TSQL behind this function:
|
1 2 3 4 5 6 7 |
RETURN CONVERT(DATETIME, CONVERT(NVARCHAR(4), @date / 10000) + N'-' + CONVERT(NVARCHAR(2), (@date % 10000)/100) + N'-' + CONVERT(NVARCHAR(2), @date % 100) + N' ' + CONVERT(NVARCHAR(2), @time / 10000) + N':' + CONVERT(NVARCHAR(2), (@time % 10000)/100) + N':' + CONVERT(NVARCHAR(2), @time % 100),120) |
@date is YYYYMMDD stored as an integer and @time is HHMMSS, also stored as an integer.
Note that these objects are all in the dbo schema, and not in the sys schema as many other system objects are.
Determining Job Schedules
Before we start, let’s define the UTC offset for a given server. This will come in handy whenever we want to convert dates/times to UTC:
|
1 2 3 |
DECLARE @utc_offset INT; SELECT @utc_offset = -1 * DATEDIFF(HOUR, GETUTCDATE(), GETDATE()); |
To get the UTC offset in hours, all we need to do is find the difference between the local time and the UTC time. This offset will vary between servers that are set to different time zones, but the resulting UTC times will be consistent.
To figure out the job schedules for a given time period, we need to analyze the data from the MSDB views presented above and return an easier-to-digest format to work with:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
SELECT sysjobs.job_id, sysschedules.schedule_uid, sysjobs.name AS job_name, CASE WHEN sysschedules.freq_type = 1 THEN 'One-Time' WHEN sysschedules.freq_type = 4 THEN 'Daily' WHEN sysschedules.freq_type = 8 THEN 'Weekly' WHEN sysschedules.freq_type = 16 THEN 'Monthly' WHEN sysschedules.freq_type = 32 THEN 'Monthly-Relative' WHEN sysschedules.freq_type = 64 THEN 'Agent Startup' WHEN sysschedules.freq_type = 128 THEN 'Computer Idle' END AS job_frequency, sysschedules.freq_interval AS job_frequency_interval, CASE WHEN sysschedules.freq_subday_type = 0 THEN 'UNUSED' WHEN sysschedules.freq_subday_type = 1 THEN 'AT_TIME' WHEN sysschedules.freq_subday_type = 2 THEN 'SECONDS' WHEN sysschedules.freq_subday_type = 4 THEN 'MINUTES' WHEN sysschedules.freq_subday_type = 8 THEN 'HOURS' END AS job_frequency_subday_type, sysschedules.freq_subday_interval AS job_frequency_subday_interval, CASE WHEN sysschedules.freq_relative_interval = 0 THEN 'UNUSED' WHEN sysschedules.freq_relative_interval = 1 THEN 'first' WHEN sysschedules.freq_relative_interval = 2 THEN 'second' WHEN sysschedules.freq_relative_interval = 4 THEN 'third' WHEN sysschedules.freq_relative_interval = 8 THEN 'fourth' WHEN sysschedules.freq_relative_interval = 16 THEN 'last' END AS job_frequency_relative_interval, sysschedules.freq_recurrence_factor AS job_frequency_recurrence_factor, CAST(DATEADD(HOUR, @utc_offset, msdb.dbo.agent_datetime(sysschedules.active_start_date, sysschedules.active_start_time)) AS DATE) AS job_start_date_utc, CAST(DATEADD(HOUR, @utc_offset, msdb.dbo.agent_datetime(sysschedules.active_start_date, sysschedules.active_start_time)) AS TIME(0)) AS job_start_time_utc, CAST(DATEADD(HOUR, @utc_offset, msdb.dbo.agent_datetime(sysschedules.active_start_date, sysschedules.active_start_time)) AS DATETIME) AS job_start_datetime_utc, sysjobs.date_created AS job_date_created, sysschedules.date_created AS schedule_date_created, '' AS job_schedule_description, -- To be populated later CASE WHEN sysschedules.freq_type = 1 THEN 1 WHEN sysschedules.freq_type = 4 THEN 1 WHEN sysschedules.freq_type = 8 THEN 1 WHEN sysschedules.freq_type = 16 THEN 1 WHEN sysschedules.freq_type = 32 THEN 1 WHEN sysschedules.freq_type = 64 THEN 0 WHEN sysschedules.freq_type = 128 THEN 0 END AS job_count FROM msdb.dbo.sysjobschedules INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobschedules.job_id INNER JOIN msdb.dbo.sysschedules ON sysschedules.schedule_id = sysjobschedules.schedule_id INNER JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id WHERE sysschedules.enabled = 1 AND sysjobs.enabled = 1; |
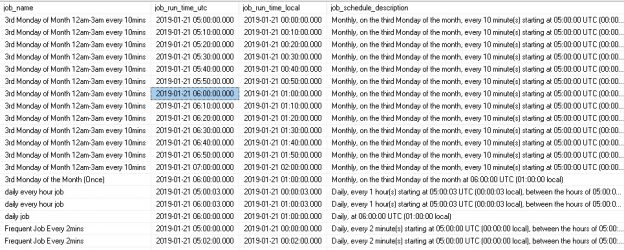
This query takes metadata from the various MSDB tables that we introduced above and converts it in an easier-to-understand plain-text set of descriptions whenever possible. Here is what the output looks like:

There are more columns are off to the right, but we can get the general idea of what each schedule means via a quick glance at this data. For example, the first job has a schedule that has it run weekly on Monday, Wednesday, and Friday at a specific time each day. The last job on the list is set to run a single time and not recur. The last column in our data set, job_count, is 0 for jobs that run at startup or when the server’s CPU is idle. This is used later when counting expected job runs as jobs with these schedules will not run on a predictable schedule that can easily be mapped out ahead of time.
The job schedule description is set blank for now, but will be updated later as we begin populating schedule data and can more easily assess what each schedule entails based on its type.
Also note that since a job can be assigned any number of schedules, it is possible for a job to appear multiple times in the above list. Disabled jobs and disabled schedules are explicitly omitted, though these filters can easily be removed, if needed.
Our goal is to create a list of expected job executions. With a list of job schedules, we can do this, though we will need to take a different approach for each type of schedule. One-time, daily, weekly, monthly, and monthly (relative) each have enough differences that writing separate code for each is the simples way to accomplish our task. This will result in more TSQL, but it will be easier to debug, customize, and maintain over time.
As a convenience, we’ll place the results from above into a temporary table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE #job_summary ( job_id UNIQUEIDENTIFIER NOT NULL, schedule_uid UNIQUEIDENTIFIER NOT NULL, job_name VARCHAR(128) NOT NULL, job_frequency VARCHAR(25) NOT NULL, -- ONE-TIME, DAILY, WEEKLY, MONTHLY, MONTHLY-RELATIVE, AGENT_STARTUP, COMPUTER_IDLE job_frequency_interval INT NOT NULL, job_frequency_subday_type VARCHAR(25) NOT NULL, -- UNUSED, AT_TIME, SECONDS, MINUTES, HOURS job_frequency_subday_interval INT NOT NULL, job_frequency_relative_interval VARCHAR(25) NOT NULL, -- UNUSED, FIRST, SECOND, THIRD, FOURTH, LAST job_frequency_recurrence_factor INT NOT NULL, job_start_date_utc DATE NOT NULL, job_start_time_utc TIME NOT NULL, job_start_datetime_utc DATETIME NOT NULL, job_end_date_utc DATE NOT NULL, job_end_time_utc TIME NOT NULL, job_end_datetime_utc DATETIME NOT NULL, job_date_created_utc DATETIME NOT NULL, schedule_date_created_utc DATETIME NOT NULL, job_schedule_description VARCHAR(250), job_count INT NOT NULL, PRIMARY KEY CLUSTERED (job_id, schedule_uid)); |
In addition, we’ll create a table that will contain a full list of job runs:
|
1 2 3 4 5 6 |
CREATE TABLE #future_job_runs ( job_id UNIQUEIDENTIFIER NOT NULL, schedule_uid UNIQUEIDENTIFIER NOT NULL, job_run_time_utc DATETIME NOT NULL, job_run_time_local DATETIME NOT NULL, PRIMARY KEY CLUSTERED (job_id, job_run_time_utc)); |
We’ll insert rows into this table in each section of this article as we build up a complete set of job runs. While this table may hold a large number of rows, it’s narrow enough so as to not consume any significant amount of space as we work through this challenge.
Some other variables we’ll use throughout our scripts:
- @start_time_utc: The start of the time frame to generate job schedules for (in UTC).
- @end_time_utc: The end of the time frame to generate job schedules for (in UTC).
- @start_time_local: The start of the time frame to generate job schedules for (in local server time).
- @end_time_local: The end of the time frame to generate job schedules for (in local server time).
- @return_summarized_data: A bit that will be 1 when we want a single summary row per job and 0 when we want a full list of all job runs.
- @include_startup_and_idle_jobs_in_summary_data: When 1, will include a reference to jobs with schedules that run on Agent startup or when CPU is idle. When 0, these jobs will be ignored.
- @end_date_local_int: This is a convenience value that is the YYYYMMDD integer representation of the end date. This will reduce the complexity of code in a section of our work later on.
These may be hard-coded or treated as parameters, depending on your use-case. We also will declare and populate a temporary table:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE #days_affected (calendar_date DATE NOT NULL PRIMARY KEY CLUSTERED); INSERT INTO #days_affected (calendar_date) SELECT Dim_Date.Calendar_Date FROM dbo.Dim_Date WHERE Dim_Date.Calendar_Date >= CAST(@start_time_utc AS DATE) AND Dim_Date.Calendar_Date <= @end_time_utc; |
This provides us date coverage for recurring jobs, as well as an easy join to a calendar table, when needed.
One-Time Schedules
These jobs run on a specified date and time and will not recur.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, job_summary.job_start_datetime_utc, DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_datetime_utc) AS job_run_time_local FROM #job_summary job_summary WHERE job_frequency = 'ONE-TIME' AND job_summary.job_start_datetime_utc BETWEEN @start_time_utc AND @end_time_utc AND job_summary.job_start_datetime_utc >= job_summary.job_date_created_utc AND job_summary.job_start_datetime_utc >= job_summary.schedule_date_created_utc; |
We will also update the job schedule description with an easily readable explanation of what the schedule means:
|
1 2 3 4 |
UPDATE job_summary SET job_schedule_description = 'One time, at ' + CAST(job_summary.job_start_datetime_utc AS VARCHAR(MAX)) + ' UTC (' + CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_datetime_utc) AS VARCHAR(MAX)) + ' local)' FROM #job_summary job_summary WHERE job_frequency = 'ONE-TIME'; |
For these jobs, we need only insert a single row at the appropriate time and we are all set!
Recurring Schedules
For schedules that can recur, we have additional work that will require us to iterate through schedules and time periods to ensure a full list of job runs is generated. To do this, we’ll declare a variety of variables that will be needed for different types of recurring jobs:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @job_counter UNIQUEIDENTIFIER; DECLARE @schedule_counter UNIQUEIDENTIFIER; DECLARE @datetime_counter DATETIME; DECLARE @job_frequency_subday_interval INT; DECLARE @active_start_datetime DATETIME; DECLARE @active_end_datetime DATETIME; DECLARE @active_start_time TIME; DECLARE @active_end_time TIME; DECLARE @job_frequency_interval INT; DECLARE @job_frequency_relative_interval VARCHAR(10); DECLARE @day_of_week_in_month TINYINT; |
We’ll review these in more detail as they are used. From here, we can address each type of schedule and how we can generate a run list for each one for whatever time period we throw at it.
Daily Schedules
These schedules represent jobs that run once per day on a given set of days or multiple times per day on a given set of days. For those that only occur once per day, we can generate schedules by cross joining our set of days that we are reporting over:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Daily, once per day INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) AS job_run_time_utc, DATEADD(HOUR, @utc_offset * -1, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME)) AS job_run_time_local FROM #job_summary job_summary CROSS JOIN #days_affected days_affected WHERE job_summary.job_frequency = 'DAILY' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN @start_time_utc AND @end_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN job_summary.job_start_datetime_utc AND job_summary.job_end_datetime_utc AND job_summary.job_frequency_subday_type IN ('UNUSED', 'AT_TIME') AND ((DATEPART(DW, days_affected.calendar_date) & job_summary.job_frequency_interval = 0 AND job_summary.job_frequency_interval > 1) OR job_summary.job_frequency_interval = 1); UPDATE job_summary SET job_schedule_description = 'Daily' + CASE WHEN job_summary.job_frequency_interval > 1 THEN ', every ' + CAST(job_summary.job_frequency_interval AS VARCHAR(MAX)) + ' days' ELSE '' END + ', at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' |
The result of the above query will be a row per day per job. The filters control a variety of timing constraints that are worth noting here:
- The job should have been created prior to our start time. If the job did not exist yet, then a job run would not have occurred
- The schedule should have been created prior to our start time. If the schedule did not exist yet, then jobs could not have used it
- The job run day matches the set of days bounded by our start and end times
- The job run time is within the hours that the job is supposed to run
These ensure we maintain a high level of accuracy with respect to each job’s intended runtime, as well as the create dates for jobs & schedules.
The next set of daily jobs to consider are those that run daily, but multiple times. These will be a bit more challenging to collect as we need to preserve the relative time intervals between each job run. For example, a job that runs every 7 hours will not occur at the same times each day, whereas a job that runs every 2 hours will.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
-- Daily, every N hours, minutes, or seconds IF EXISTS (SELECT * FROM #job_summary WHERE job_frequency = 'DAILY' AND job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS')) BEGIN DECLARE job_cursor CURSOR FOR SELECT job_summary.job_id, job_summary.schedule_uid, DATEADD(DAY, -1, CAST(CAST(@start_time_utc AS DATE) AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME)) AS datetime_counter, CASE WHEN job_summary.job_frequency_subday_type = 'SECONDS' THEN job_summary.job_frequency_subday_interval WHEN job_summary.job_frequency_subday_type = 'MINUTES' THEN job_summary.job_frequency_subday_interval * 60 WHEN job_summary.job_frequency_subday_type = 'HOURS' THEN job_summary.job_frequency_subday_interval * 3600 END AS job_frequency_subday_interval, job_summary.job_start_datetime_utc, job_summary.job_end_datetime_utc, job_summary.job_start_time_utc, job_summary.job_end_time_utc, job_summary.job_frequency_interval FROM #job_summary job_summary WHERE job_summary.job_frequency = 'DAILY' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc AND job_summary.job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS'); OPEN job_cursor; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time, @job_frequency_interval; WHILE @@FETCH_STATUS = 0 BEGIN WHILE @datetime_counter < @start_time_utc BEGIN SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END WHILE @datetime_counter <= @end_time_utc BEGIN IF (@datetime_counter BETWEEN @active_start_datetime AND @active_end_datetime) AND ((@active_start_time <= @active_end_time AND CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND @active_end_time) OR (@active_start_time > @active_end_time AND ((CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND '23:59:59.999') OR CAST(@datetime_counter AS TIME) BETWEEN '00:00:00' AND @active_end_time))) AND ((DATEPART(DW, @datetime_counter) & @job_frequency_interval = 0 AND @job_frequency_interval > 1) OR @job_frequency_interval = 1) BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT @job_counter, @schedule_counter, @datetime_counter AS job_run_time_utc, DATEADD(HOUR, @utc_offset * -1, @datetime_counter) AS job_run_time_local; END SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END UPDATE job_summary SET job_schedule_description = 'Daily' + CASE WHEN job_summary.job_frequency_interval > 1 THEN ', every ' + CAST(job_summary.job_frequency_interval AS VARCHAR(MAX)) + ' days' ELSE '' END + ', every ' + CASE WHEN @job_frequency_subday_interval >= 3600 THEN CAST(@job_frequency_subday_interval / 3600 AS VARCHAR(MAX)) + ' hour(s)' WHEN @job_frequency_subday_interval >= 60 THEN CAST(@job_frequency_subday_interval / 60 AS VARCHAR(MAX)) + ' minute(s)' ELSE CAST(@job_frequency_subday_interval AS VARCHAR(MAX)) + ' second(s)' END + ' starting at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' + CASE WHEN @active_start_time <> '00:00:00' OR @active_end_time <> '23:59:59' THEN ', between the hours of ' + LEFT(CAST(@active_start_time AS VARCHAR(MAX)), 8) + ' UTC and ' + LEFT(CAST(@active_end_time AS VARCHAR(MAX)), 8) + ' UTC' ELSE '' END + CASE WHEN @active_start_datetime > @start_time_utc OR @active_end_datetime < @end_time_utc THEN ', between the dates of ' + CAST(CAST(@active_start_datetime AS DATE) AS VARCHAR(MAX)) + ' and ' + CAST(CAST(@active_end_datetime AS DATE) AS VARCHAR(MAX)) ELSE '' END FROM #job_summary job_summary WHERE job_summary.job_id = @job_counter AND job_summary.schedule_uid = @schedule_counter; |
This code is a bit more complex as we need to perform the same analysis as above, but for each and every job run. Iterating through jobs and run times may not seem to be an efficient solution, but as table access is not a part of the run time looping, it executes quite quickly. An additional liberty taken at this point is to normalize job run frequency into seconds. This allows us to manage jobs that increment run times by hours, minutes, and seconds all in a single set of queries.
The end result of the above code will be a set of scheduled job runs for each job per day that it is run. For jobs that run very often, this can be a long list that may be too large to be of use on its own. Summarizing data will help resolve this and reduce a long run list into a single row with start and end datetimes, as well as expected run counts.
Weekly Schedules
Despite the name, weekly schedules may occur once or more than once per week on a given set of days. As a result, the code for this is very similar to that of daily schedules, with a single additional filter that will validate if a given date is in the set of days a job schedule is configured to run on.
The following is all of the code necessary to process weekly schedules:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) AS job_run_time_UTC, DATEADD(HOUR, @utc_offset * -1, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME)) AS job_run_time_local FROM #job_summary job_summary CROSS JOIN #days_affected days_affected WHERE job_frequency = 'WEEKLY' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN @start_time_utc AND @end_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN job_summary.job_start_datetime_utc AND job_summary.job_end_datetime_utc AND job_summary.job_frequency_subday_type IN ('UNUSED', 'AT_TIME') AND job_summary.job_frequency_interval & POWER(2, DATEPART(DW, days_affected.calendar_date) - 1) = POWER(2, DATEPART(DW, days_affected.calendar_date) - 1); UPDATE job_summary SET job_schedule_description = 'Weekly, on ' + LEFT(CASE WHEN job_summary.job_frequency_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END, LEN(CASE WHEN job_summary.job_frequency_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END) - 1) + ' at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' FROM #job_summary job_summary WHERE job_frequency = 'WEEKLY' AND job_summary.job_frequency_subday_type IN ('UNUSED', 'AT_TIME'); -- Schedules that are weekly, but every N seconds, minutes, or hours. IF EXISTS (SELECT * FROM #job_summary WHERE job_frequency = 'WEEKLY' AND job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS')) BEGIN DECLARE job_cursor CURSOR FOR SELECT job_summary.job_id, job_summary.schedule_uid, DATEADD(DAY, -1, CAST(CAST(@start_time_utc AS DATE) AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME)), CASE WHEN job_summary.job_frequency_subday_type = 'SECONDS' THEN job_summary.job_frequency_subday_interval WHEN job_summary.job_frequency_subday_type = 'MINUTES' THEN job_summary.job_frequency_subday_interval * 60 WHEN job_summary.job_frequency_subday_type = 'HOURS' THEN job_summary.job_frequency_subday_interval * 3600 END, job_summary.job_frequency_interval, job_summary.job_start_datetime_utc, job_summary.job_end_datetime_utc, job_summary.job_start_time_utc, job_summary.job_end_time_utc FROM #job_summary job_summary WHERE job_summary.job_frequency = 'WEEKLY' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc AND job_summary.job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS'); OPEN job_cursor; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time; WHILE @@FETCH_STATUS = 0 BEGIN WHILE @datetime_counter < @start_time_utc BEGIN SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END WHILE @datetime_counter <= @end_time_utc BEGIN IF @job_frequency_interval & POWER(2, DATEPART(DW, @datetime_counter) - 1) = POWER(2, DATEPART(DW, @datetime_counter) - 1) AND (@datetime_counter BETWEEN @active_start_datetime AND @active_end_datetime) AND ((@active_start_time <= @active_end_time AND CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND @active_end_time) OR (@active_start_time > @active_end_time AND ((CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND '23:59:59.999') OR CAST(@datetime_counter AS TIME) BETWEEN '00:00:00' AND @active_end_time))) BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT @job_counter, @schedule_counter, @datetime_counter AS job_run_time_utc, DATEADD(HOUR, @utc_offset * -1, @datetime_counter) AS job_run_time_local END SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END UPDATE job_summary SET job_schedule_description = 'Weekly, on ' + LEFT(CASE WHEN job_summary.job_frequency_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END, LEN(CASE WHEN job_summary.job_frequency_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN job_summary.job_frequency_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END) - 1) + ', every ' + CASE WHEN @job_frequency_subday_interval >= 3600 THEN CAST(@job_frequency_subday_interval / 3600 AS VARCHAR(MAX)) + ' hour(s)' WHEN @job_frequency_subday_interval >= 60 THEN CAST(@job_frequency_subday_interval / 60 AS VARCHAR(MAX)) + ' minute(s)' ELSE CAST(@job_frequency_subday_interval AS VARCHAR(MAX)) + ' second(s)' END + ' starting at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' + CASE WHEN @active_start_time <> '00:00:00' OR @active_end_time <> '23:59:59' THEN ', between the hours of ' + LEFT(CAST(@active_start_time AS VARCHAR(MAX)), 8) + ' and ' + LEFT(CAST(@active_end_time AS VARCHAR(MAX)), 8) ELSE '' END + CASE WHEN @active_start_datetime > @start_time_utc OR @active_end_datetime < @end_time_utc THEN ', between the dates of ' + CAST(CAST(@active_start_datetime AS DATE) AS VARCHAR(MAX)) + ' and ' + CAST(CAST(@active_end_datetime AS DATE) AS VARCHAR(MAX)) ELSE '' END FROM #job_summary job_summary WHERE job_summary.job_id = @job_counter AND job_summary.schedule_uid = @schedule_counter; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time; END CLOSE job_cursor; DEALLOCATE job_cursor; END |
As before, we handle schedules that occur once-per-day separately from those that recur within each day. An additional filter to ensure we only include job runs on the correct days is to compare the bitwise job_frequency_interval with the day of the week:
|
1 |
AND job_summary.job_frequency_interval & POWER(2, DATEPART(DW, days_affected.calendar_date) - 1) = POWER(2, DATEPART(DW, days_affected.calendar_date) - 1); |
If the bitwise sum can be bitwise divided evenly by two raised to the power of the numeric value of the day of the week minus 1, then the job is supposed to run on that day. For example, consider a job that is expected to run on Sunday, Wednesday, and Friday. Those days are represented by 1, 4, and 6, respectively. For this schedule, job_frequency_interval will be 41 (0101001). When we check days of the week against that binary number, those that hit a one in the digits will be included in the schedules run times, whereas those with zeroes will not.
Monthly Schedules
These are quite similar to daily schedules in that they run on a given day of the month and may run once or multiple times on that given day. Since only a single day per month is affected, our code is simpler and we do not need to check bitwise values to determine what days a job should run on (what a relief!):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
DECLARE job_cursor CURSOR FOR SELECT job_summary.job_id, job_summary.schedule_uid, DATEADD(DAY, job_summary.job_frequency_interval - 1, DATEADD(DAY, -1 * DATEPART(DAY, CAST(@start_time_utc AS DATE)) + 1, CAST(CAST(@start_time_utc AS DATE) AS DATETIME))) + CAST(job_summary.job_start_time_utc AS DATETIME), CASE WHEN job_summary.job_frequency_subday_type = 'SECONDS' THEN job_summary.job_frequency_subday_interval WHEN job_summary.job_frequency_subday_type = 'MINUTES' THEN job_summary.job_frequency_subday_interval * 60 WHEN job_summary.job_frequency_subday_type = 'HOURS' THEN job_summary.job_frequency_subday_interval * 3600 END, job_summary.job_frequency_interval, job_summary.job_start_datetime_utc, job_summary.job_end_datetime_utc, job_summary.job_start_time_utc, job_summary.job_end_time_utc FROM #job_summary job_summary WHERE job_frequency = 'MONTHLY' AND job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS') AND job_frequency_recurrence_factor = 1 AND job_summary.job_frequency_relative_interval = 'UNUSED' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc; OPEN job_cursor; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time; WHILE @@FETCH_STATUS = 0 BEGIN WHILE @datetime_counter < @start_time_utc BEGIN SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END WHILE @datetime_counter <= @end_time_utc BEGIN IF (@datetime_counter BETWEEN @active_start_datetime AND @active_end_datetime) AND DATEPART(DAY, @datetime_counter) = @job_frequency_interval AND ((@active_start_time <= @active_end_time AND CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND @active_end_time) OR (@active_start_time > @active_end_time AND ((CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND '23:59:59.999') OR CAST(@datetime_counter AS TIME) BETWEEN '00:00:00' AND @active_end_time))) BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT @job_counter, @schedule_counter, @datetime_counter AS job_run_time_utc, DATEADD(HOUR, @utc_offset * -1, @datetime_counter) AS job_run_time_local END SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END UPDATE job_summary SET job_schedule_description = 'Monthly, on day ' + CAST(job_summary.job_frequency_interval AS VARCHAR(MAX)) + ' of the month' + ', every ' + CASE WHEN @job_frequency_subday_interval >= 3600 THEN CAST(@job_frequency_subday_interval / 3600 AS VARCHAR(MAX)) + ' hour(s)' WHEN @job_frequency_subday_interval >= 60 THEN CAST(@job_frequency_subday_interval / 60 AS VARCHAR(MAX)) + ' minute(s)' ELSE CAST(@job_frequency_subday_interval AS VARCHAR(MAX)) + ' second(s)' END + ' starting at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' + CASE WHEN @active_start_time <> '00:00:00' OR @active_end_time <> '23:59:59' THEN ', between the hours of ' + LEFT(CAST(@active_start_time AS VARCHAR(MAX)), 8) + ' and ' + LEFT(CAST(@active_end_time AS VARCHAR(MAX)), 8) ELSE '' END + CASE WHEN @active_start_datetime > @start_time_utc OR @active_end_datetime < @end_time_utc THEN ', between the dates of ' + CAST(CAST(@active_start_datetime AS DATE) AS VARCHAR(MAX)) + ' and ' + CAST(CAST(@active_end_datetime AS DATE) AS VARCHAR(MAX)) ELSE '' END FROM #job_summary job_summary WHERE job_summary.job_id = @job_counter AND job_summary.schedule_uid = @schedule_counter; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time; END CLOSE job_cursor; DEALLOCATE job_cursor; |
While the use-case for a schedule that runs multiple times per day monthly is odd, we include it for completeness as SQL Server does allow us to do unusual things like that. In theory, there could be a need to have a unique job recur once per month for additional coverage over the course of a significant day.
Monthly-Relative Schedules
Whereas monthly schedules occur on a specific day within the month, such as the 1st day, last day, or the 15th, relative schedules occur on a given instance of a day per month, such as the 2nd Tuesday, 4th Wednesday, or last Friday. As a result, the exact date will vary from month-to-month. This is the schedule type where a calendar table is very handy and will save us a ton of work when processing these schedules!
The following code is broken into similar sections as earlier: One for jobs that occur a single time on a given day and another for those that repeat within the target day:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) AS job_run_time_UTC, DATEADD(HOUR, @utc_offset * -1, CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME)) AS job_run_time_local FROM #job_summary job_summary CROSS JOIN #days_affected days_affected INNER JOIN dbo.Dim_Date ON days_affected.calendar_date = Dim_Date.Calendar_Date WHERE job_frequency = 'MONTHLY-RELATIVE' AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN @start_time_utc AND @end_time_utc AND CAST(days_affected.calendar_date AS DATETIME) + CAST(job_summary.job_start_time_utc AS DATETIME) BETWEEN job_summary.job_start_datetime_utc AND job_summary.job_end_datetime_utc AND job_summary.job_frequency_subday_type IN ('UNUSED', 'AT_TIME') AND Dim_Date.Day_of_Week = job_summary.job_frequency_interval AND job_summary.job_frequency_relative_interval IN ('FIRST', 'SECOND', 'THIRD', 'FOURTH', 'LAST') AND Dim_Date.Day_of_Week_in_Month = CASE WHEN job_summary.job_frequency_relative_interval = 'FIRST' THEN 1 WHEN job_summary.job_frequency_relative_interval = 'SECOND' THEN 2 WHEN job_summary.job_frequency_relative_interval = 'THIRD' THEN 3 WHEN job_summary.job_frequency_relative_interval = 'FOURTH' THEN 4 WHEN job_summary.job_frequency_relative_interval = 'LAST' THEN (SELECT MAX(MAX_CHECK.Day_of_Week_in_Month) FROM Dim_Date MAX_CHECK WHERE MAX_CHECK.Calendar_Month = Dim_Date.Calendar_Month AND MAX_CHECK.Calendar_Year = Dim_Date.Calendar_Year AND MAX_CHECK.Day_of_Week = Dim_Date.Day_of_Week) END AND job_summary.job_frequency_recurrence_factor = 1; UPDATE job_summary SET job_schedule_description = 'Monthly, on the ' + job_summary.job_frequency_relative_interval + CASE WHEN job_frequency_interval = 1 THEN ' Sunday' WHEN job_frequency_interval = 2 THEN ' Monday' WHEN job_frequency_interval = 3 THEN ' Tuesday' WHEN job_frequency_interval = 4 THEN ' Wednesday' WHEN job_frequency_interval = 5 THEN ' Thursday' WHEN job_frequency_interval = 6 THEN ' Friday' WHEN job_frequency_interval = 7 THEN ' Saturday' END + ' of the month' + ' at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' FROM #job_summary job_summary WHERE job_frequency = 'MONTHLY-RELATIVE' AND job_summary.job_frequency_subday_type IN ('UNUSED', 'AT_TIME') AND job_summary.job_frequency_recurrence_factor = 1; -- Monthly schedules that run monthly on a given day, but multiple times. IF EXISTS (SELECT * FROM #job_summary WHERE job_frequency = 'MONTHLY-RELATIVE' AND job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS') AND job_frequency_recurrence_factor = 1) BEGIN DECLARE job_cursor CURSOR FOR SELECT job_summary.job_id, job_summary.schedule_uid, DATEADD(DAY, job_summary.job_frequency_interval - 1, DATEADD(DAY, -1 * DATEPART(DAY, CAST(@start_time_utc AS DATE)) + 1, CAST(CAST(@start_time_utc AS DATE) AS DATETIME))) + CAST(job_summary.job_start_time_utc AS DATETIME), CASE WHEN job_summary.job_frequency_subday_type = 'SECONDS' THEN job_summary.job_frequency_subday_interval WHEN job_summary.job_frequency_subday_type = 'MINUTES' THEN job_summary.job_frequency_subday_interval * 60 WHEN job_summary.job_frequency_subday_type = 'HOURS' THEN job_summary.job_frequency_subday_interval * 3600 END, job_summary.job_frequency_interval, job_summary.job_start_datetime_utc, job_summary.job_end_datetime_utc, job_summary.job_start_time_utc, job_summary.job_end_time_utc, job_summary.job_frequency_relative_interval FROM #job_summary job_summary WHERE job_frequency = 'MONTHLY-RELATIVE' AND job_frequency_subday_type IN ('SECONDS', 'MINUTES', 'HOURS') AND job_frequency_recurrence_factor = 1 AND job_summary.job_frequency_relative_interval IN ('FIRST', 'SECOND', 'THIRD', 'FOURTH', 'LAST') AND job_summary.job_date_created_utc <= @start_time_utc AND job_summary.schedule_date_created_utc <= @start_time_utc; OPEN job_cursor; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time, @job_frequency_relative_interval; WHILE @@FETCH_STATUS = 0 BEGIN WHILE @datetime_counter < @start_time_utc BEGIN SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END WHILE @datetime_counter <= @end_time_utc BEGIN SELECT @day_of_week_in_month = (SELECT Dim_Date.Day_of_Week_in_Month FROM dbo.Dim_Date WHERE Dim_Date.Calendar_Date = CAST(@datetime_counter AS DATE)) IF @job_frequency_interval = DATEPART(DW, @datetime_counter) AND (@datetime_counter BETWEEN @active_start_datetime AND @active_end_datetime) AND ((@active_start_time <= @active_end_time AND CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND @active_end_time) OR (@active_start_time > @active_end_time AND ((CAST(@datetime_counter AS TIME) BETWEEN @active_start_time AND '23:59:59.999') OR CAST(@datetime_counter AS TIME) BETWEEN '00:00:00' AND @active_end_time))) AND @day_of_week_in_month = CASE WHEN @job_frequency_relative_interval = 'FIRST' THEN 1 WHEN @job_frequency_relative_interval = 'SECOND' THEN 2 WHEN @job_frequency_relative_interval = 'THIRD' THEN 3 WHEN @job_frequency_relative_interval = 'FOURTH' THEN 4 WHEN @job_frequency_relative_interval = 'LAST' THEN (SELECT MAX(MAX_CHECK.Day_of_Week_in_Month) FROM Dim_Date MAX_CHECK WHERE MAX_CHECK.Calendar_Month = DATEPART(MONTH, @datetime_counter) AND MAX_CHECK.Calendar_Year = DATEPART(YEAR, @datetime_counter) AND MAX_CHECK.Day_of_Week = DATEPART(DW, @datetime_counter)) END BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT @job_counter, @schedule_counter, @datetime_counter AS job_run_time_utc, DATEADD(HOUR, @utc_offset * -1, @datetime_counter) AS job_run_time_local END SELECT @datetime_counter = DATEADD(SECOND, @job_frequency_subday_interval, @datetime_counter); END UPDATE job_summary SET job_schedule_description = 'Monthly, on the ' + job_summary.job_frequency_relative_interval + CASE WHEN job_frequency_interval = 1 THEN ' Sunday' WHEN job_frequency_interval = 2 THEN ' Monday' WHEN job_frequency_interval = 3 THEN ' Tuesday' WHEN job_frequency_interval = 4 THEN ' Wednesday' WHEN job_frequency_interval = 5 THEN ' Thursday' WHEN job_frequency_interval = 6 THEN ' Friday' WHEN job_frequency_interval = 7 THEN ' Saturday' END + ' of the month' + ', every ' + CASE WHEN @job_frequency_subday_interval >= 3600 THEN CAST(@job_frequency_subday_interval / 3600 AS VARCHAR(MAX)) + ' hour(s)' WHEN @job_frequency_subday_interval >= 60 THEN CAST(@job_frequency_subday_interval / 60 AS VARCHAR(MAX)) + ' minute(s)' ELSE CAST(@job_frequency_subday_interval AS VARCHAR(MAX)) + ' second(s)' END + ' starting at ' + LEFT(CAST(job_summary.job_start_time_utc AS VARCHAR(MAX)), 8) + ' UTC (' + LEFT(CAST(DATEADD(HOUR, @utc_offset * -1, job_summary.job_start_time_utc) AS VARCHAR(MAX)), 8) + ' local)' + CASE WHEN @active_start_time <> '00:00:00' OR @active_end_time <> '23:59:59' THEN ', between the hours of ' + LEFT(CAST(@active_start_time AS VARCHAR(MAX)), 8) + ' and ' + LEFT(CAST(@active_end_time AS VARCHAR(MAX)), 8) ELSE '' END + CASE WHEN @active_start_datetime > @start_time_utc OR @active_end_datetime < @end_time_utc THEN ', between the dates of ' + CAST(CAST(@active_start_datetime AS DATE) AS VARCHAR(MAX)) + ' and ' + CAST(CAST(@active_end_datetime AS DATE) AS VARCHAR(MAX)) ELSE '' END FROM #job_summary job_summary WHERE job_summary.job_id = @job_counter AND job_summary.schedule_uid = @schedule_counter; FETCH NEXT FROM job_cursor INTO @job_counter, @schedule_counter, @datetime_counter, @job_frequency_subday_interval, @job_frequency_interval, @active_start_datetime, @active_end_datetime, @active_start_time, @active_end_time, @job_frequency_relative_interval; END CLOSE job_cursor; DEALLOCATE job_cursor; END |
The primary difference between these schedules and previous is the need to check a calendar table to determine what date matches the scheduling clause. The 1st Tuesday of February could be February 1st or it could be the 7th. The CASE statement that checks this is not terribly pretty, but converts FIRST, SECOND, THIRD, FOURTH, and LAST into numbers that can be compared against the day-of-week-in-month for any given date. Fortunately, since the date range we are analyzing are more likely to be a small set of days (and not numbering millions of days), performance here is not going to be an issue.
Startup and CPU Idle Schedules
These are special schedules that are included here for completeness and are optional. The bit @include_startup_and_idle_jobs_in_summary_data is used to filter them out if they are not needed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
IF @include_startup_and_idle_jobs_in_summary_data = 1 BEGIN IF EXISTS (SELECT * FROM #job_summary WHERE job_frequency = 'COMPUTER IDLE') BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, '1/1/1901' AS job_run_time_utc, '1/1/1901' AS job_run_time_local FROM #job_summary job_summary WHERE job_frequency = 'COMPUTER IDLE'; UPDATE job_summary SET job_schedule_description = 'Runs when computer is idle.' FROM #job_summary job_summary WHERE job_frequency = 'COMPUTER IDLE'; END IF EXISTS (SELECT * FROM #job_summary WHERE job_frequency = 'AGENT STARTUP') BEGIN INSERT INTO #future_job_runs (job_id, schedule_uid, job_run_time_utc, job_run_time_local) SELECT job_summary.job_id, job_summary.schedule_uid, '1/1/1901' AS job_run_time_utc, '1/1/1901' AS job_run_time_local FROM #job_summary job_summary WHERE job_frequency = 'AGENT STARTUP'; UPDATE job_summary SET job_schedule_description = 'Runs when SQL Server Agent starts.' FROM #job_summary job_summary WHERE job_frequency = 'AGENT STARTUP'; END END |
This data is relatively simple to generate and allows us to maintain insight into jobs that may matter to us under special circumstances. If not, they can easily be omitted via the bit flag or removed from code altogether if there will never be a need for them.
Using Our Creation
When we string all of this code together into a stored procedure, we can run it on any SQL Server for a time period and get back a job listing. The parameters introduced earlier will be used as stored procedure parameters so that we can quickly execute this from whatever target maintenance database we wish.
Here is an execution of the final stored proc on my local server, which contains a variety of test jobs and schedules:
|
1 2 3 4 5 6 7 |
EXEC dbo.generate_job_schedule_data @start_time_utc = NULL, @end_time_utc = NULL, @start_time_local = '1/21/2019 00:00:00', @end_time_local = '1/21/2019 02:00:00', @return_summarized_data = 1, @include_startup_and_idle_jobs_in_summary_data = 0; |
The results are as follows:

Since I passed in local times as parameters, the results are coordinated to those times, though UTC is also returned for informational purposes. The results are summarized and include the first and last run times for each job, as well as the total job count and a friendly description of the job schedule.
We can adjust the proc execution to include startup & idle CPU jobs, like this:
|
1 2 3 4 5 6 7 |
EXEC dbo.generate_job_schedule_data @start_time_utc = NULL, @end_time_utc = NULL, @start_time_local = '1/21/2019 00:00:00', @end_time_local = '1/21/2019 02:00:00', @return_summarized_data = 1, @include_startup_and_idle_jobs_in_summary_data = 1; |

The results are the same as the previous example, with the addition of rows for the idle CPU and startup jobs. Note that the job run count is zero for each of these jobs as there is no predictable execution during the time period specified. Despite that, knowing those jobs exist can be useful when planning (or recovering) from maintenance.
Similarly, we can enter times in UTC:
|
1 2 3 4 5 6 7 |
EXEC dbo.generate_job_schedule_data @start_time_utc = '1/21/2019 05:00:00', @end_time_utc = '1/21/2019 07:00:00', @start_time_local = NULL, @end_time_local = NULL, @return_summarized_data = 1, @include_startup_and_idle_jobs_in_summary_data = 1; |
The results will be identical to the previous example as the UTC times provided are equivalent to the local times on my server.
Lastly, we can expand the job run times so that they are not summarized. This can be useful if we want to crunch our own metrics, or if the schedules run list is short enough to eyeball manually:
|
1 2 3 4 5 6 7 |
EXEC dbo.generate_job_schedule_data @start_time_utc = '1/21/2019 05:00:00', @end_time_utc = '1/21/2019 07:00:00', @start_time_local = NULL, @end_time_local = NULL, @return_summarized_data = 0, @include_startup_and_idle_jobs_in_summary_data = 0; |

In this example, a total of 80 rows were returned, one per distinct job execution. This can be a large data set, so summarizing will typically be the desired way to return this data for most use-cases.
With this tool, we can map out expected job executions for any time period, past or future. This can have many applications, such as:
- Planning maintenance and ensuring that no jobs are missed while the SQL Server Agent service is not running
- Looking back at an outage and determining if any significant job runs were missed
- Correlating performance or error conditions with Agent job schedules
- Understanding job schedules and usage of SQL Server Agent
Exceptions and Customization
Some jobs fall outside of the useful bounds of this process and we may want to omit them via changes to our code. Common jobs that we would want to ignore are:
- Always-running jobs: Some jobs are built with frequent schedules but are continuously running. As a result, they will appear to the operator as frequent or missed jobs, but in reality, they are running normally. While an odd design pattern, you may wish to omit jobs such as these from the results to avoid confusion
- Jobs that are resilient: Some jobs are built to rerun and catch up with any missed work. As a result, we may not care when they run, so long as they eventually succeed
- Jobs that run very often: These are probably resilient jobs that are built to withstand errors or missed runs and we may not care as much about their schedules
As with any maintenance tool, we should also consider opportunities to customize. The inputs, filters, and outputs of the stored procedure are somewhat arbitrary. Additions can easily be made without having to dig too deeply into the code.
Different organizations have different data needs and some servers may specialize in specific types of jobs. This may lead to a need to track job importance or priority, which could easily be added as a dimension to this data.
Adjusting how we handle disabled jobs or schedules, or job/schedule creation times is as easy as removing filters on each section of code.
Conclusion
Being able to quickly map out all expected job runs for a given time period can be a huge time saver. We can predict future SQL Server Agent schedules, more confidently plan maintenance, and respond to outages with a better knowledge of what was missed.
The natural next step for this stored procedure is to compare its results to SQL Server Agent’s job history in order to automate a process that can check for missed jobs and alert an operator when this happens.
Heavy use of bitwise math may make this code intimidating, but customization will largely avoid the need to interact with any complex logic. Most meaningful changes can be accomplished by adding or removing simple filters from the initial job summarization, or by adjusting filters common to each other section of code throughout the process.
References and Further Reading
A calendar table is required by this process. While we can code around this, the results would be much longer and sloppier. Code for my calendar table is included in this article and you may learn more about its creation and use here: Designing a Calendar Table
msdb.dbo.sysschedules is one of the more complicated system tables. The following MSDN link explains it in far more detail, which can be helpful when customizing this code: dbo.sysschedules (Transact-SQL)
T-SQL script used in this article
Table of contents
| Generating Schedules with SQL Server Agent |
| Detecting and Alerting on SQL Server Agent Missed Jobs |

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019