
In this article, I am going to explain what Amazon S3 is and how to connect to it using python. This article will be focused on beginners who are trying to get their hands on python and working around the AWS ecosystem. AWS, as you might know, is one of the largest cloud providers along with Microsoft Azure and Google Cloud Platform. There are a lot of services offered by Amazon including AWS S3. Amazon S3, also abbreviated as Amazon Simple Storage Service is a storage service offered by the cloud provider that enables the users to store any kind of files in this service. It is designed to make web-scale computing easier for developers.
As per the definition provided by Wikipedia – “Amazon S3 or Amazon Simple Storage Service is a service offered by Amazon Web Services (AWS) that provides object storage through a web service interface.” The individual storage units of Amazon S3 are known as buckets. These buckets can also be considered as the root directory under which all the subsequent items will be stored. All the directories and files are considered as objects within the S3 ecosystem. These objects are represented by a unique and user-assigned key. You can access the Amazon S3 buckets by using any one of the following four ways.
- Using the Amazon console web interface
- Using the Amazon CLI (command line interface)
- Using the Amazon SDK for any programming language
- Using the REST APIs
Objects or items that are stored using the Amazon CLI or the REST APIs are limited to 5TB in size with 2KB of metadata information. Read more about Amazon S3 from the official documentation from Amazon.
Prerequisites
As already mentioned, in this article we are going to use AWS S3 and python to connect to the AWS service, the following pre-requisites must be already fulfilled.
- A valid AWS Account – In order to access the S3 environment, you must have a valid AWS subscription. If you are new to AWS, please create a new account by signing up for AWS at https://console.aws.amazon.com
- Python 3.7 – You must have python executable installed on your machine. You can download python by visiting https://www.python.org/downloads/ and select the correct version as per your operating system
- Visual Studio Code – In this article, we are going to use the Visual Studio Code as the code editor. You are free to choose any other code editors of your choice
Using AWS S3 from the console
Once you have signed up for Amazon Web Services, log in to the console application. Click on Services and select S3 under Storage.

Figure 1 – Starting up S3
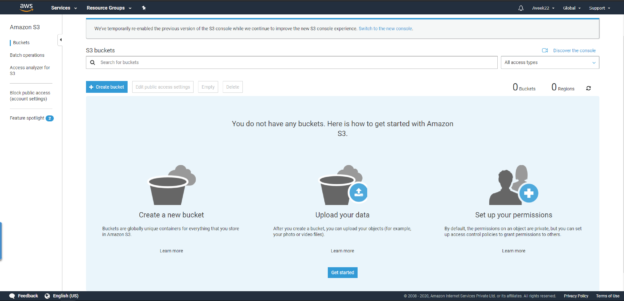
You will see that the S3 home screen opens up which looks something like below.

Figure 2 – AWS S3 Home Screen
As you can see in the figure above, I have not created any buckets within my S3. Let us go ahead and create some buckets first. I will create two buckets with the names as follows.
- sql-server-shack-demo-1
- sql-server-shack-demo-2

Figure 3 – Creating the S3 buckets
Repeating the same for both the buckets. Once the buckets are created you can see the list as follows.

Figure 4 – S3 buckets created
I am also going to upload a sample CSV file into one of the buckets just to read the data from it later on during the tutorial.

Figure 5 – Sample CSV file uploaded
Generate the Secret Tokens
Now that we have created our buckets in S3, the next step is to go ahead and generate the credentials to access the S3 buckets programmatically using Python. You can follow this tutorial to generate the AWS credentials or follow the official documentation from Amazon. Once these credentials are generated, please save this information to a secured location. A sample of the access key and the secret key are as follows.
ACCESS KEY: AKIAIOSFODNN7EXAMPLE
SECRET KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Writing the python code
So, now we have our buckets ready in S3 and we have also generated the access credentials that are required to connect to the AWS environment from the python file. Let us now go ahead and start writing our code.
First, we need to import the following boto3 module into our code. This is the AWS SDK for python provided by Amazon. If you do not have this installed on your machine, please get it installed using the Python PIP. Additionally, we will also make use of the python pandas module so that we can read data from the S3 and store them into a pandas data frame. You can run the following commands to install the modules if not already done.
pip install boto3
pip install pandas
This command will install the module on your machine. Since I have already installed it earlier, it will show the following message.

Figure 6 – Installing the AWS SDK for Python – Boto3
Let us now import this module into our python code.
|
1 2 |
import boto3 import pandas |
Once the module has been imported into the code, the next step is to create an S3 client and a resource that will allow us to access the objects stored in our S3 environment. Both the client and the resource are available to connect to the S3 objects. The client is a low-level functional interface, whereas the resource is a high-level object-oriented interface. If you want to work with single S3 files, you can choose to work with the client. However, if you need to work with multiple S3 buckets and need to iterate over those, then using resources would be ideal. Let us go ahead and create both of these. Also, we need to specify the credentials while creating the objects. You can use the code below to create the client and the resource.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Creating the low level functional client client = boto3.client( 's3', aws_access_key_id = 'AKIA46SFIWN5AMWMDQVB', aws_secret_access_key = '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', region_name = 'ap-south-1' ) # Creating the high level object oriented interface resource = boto3.resource( 's3', aws_access_key_id = 'AKIA46SFIWN5AMWMDQVB', aws_secret_access_key = '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', region_name = 'ap-south-1' ) |
Once both the objects are created, let us go ahead and try to display a list of all the buckets within our S3 environment. Use the code below to print a list of all the buckets.
|
1 2 3 4 5 6 7 |
# Fetch the list of existing buckets clientResponse = client.list_buckets() # Print the bucket names one by one print('Printing bucket names...') for bucket in clientResponse['Buckets']: print(f'Bucket Name: {bucket["Name"]}') |
The output of the above code is as follows.

Figure 7 – Printing bucket names from AWS S3
Now that we have listed all the existing buckets within our Amazon S3 environment, let us go ahead and try to create a new bucket with the name “sql-server-shack-demo-3”. In order to create a bucket in the S3, you need to specify the name of the bucket which has to be unique across all the regions of the AWS platform. However, the buckets can be created in a region which is geographically nearer to you so that the latency may be minimized. You can use the following code to create a bucket in S3.
|
1 2 3 4 5 6 |
# Creating a bucket in AWS S3 location = {'LocationConstraint': 'ap-south-1'} client.create_bucket( Bucket='sql-server-shack-demo-3', CreateBucketConfiguration=location ) |
Once you run the above code, the S3 bucket will be automatically created in the region specified. You can verify the same by running the previous code to list all the buckets in the S3 environment.

Figure 8 – New S3 bucket created
Finally, let us go ahead and try to read the CSV file that we had earlier uploaded to the Amazon S3 bucket. For that, we will be using the python pandas library to read the data from the CSV file. First, we will create an S3 object which will refer to the CSV file path and then using the read_csv() method, we will read data from the file. You can use the following code to fetch and read data from the CSV file in S3.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Create the S3 object obj = client.get_object( Bucket = 'sql-server-shack-demo-1', Key = 'sql-shack-demo.csv' ) # Read data from the S3 object data = pandas.read_csv(obj['Body']) # Print the data frame print('Printing the data frame...') print(data) |
Once you run the above code, you will see that the CSV file has been read and the data frame has been displayed on your console as follows.

Figure 9 – Reading data from Amazon S3
Conclusion
In this article, we have learned what Amazon S3 is and how to use the same. Amazon S3 is a storage service provided by AWS and can be used to store any kind of files within it. We have also learned how to use python to connect to the AWS S3 and read the data from within the buckets. Python makes use of the boto3 python library to connect to the Amazon services and use the resources from within AWS.
Table of contents

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021