

This article gives you an overview of cataloging AWS RDS SQL Server database objects like tables and views, using AWS Glue service.
Introduction
An enterprise IT landscape often consists of a large number of databases and even more database objects. Data is often exchanged between multiple sources and target databases. The standard practice is to maintain a central inventory of data repositories and database objects. This repository is also called the metadata catalog, which holds just the schema definition of database objects. ETL tools can refer to this centralized catalog while pointing to the source and target database objects. AWS RDS for SQL Server is one of the databases supported by AWS RDS service and enterprises host large production workloads on Amazon RDS SQL Server database instances. And with it comes the need to catalog the database. AWS offers AWS Glue service that supports crawling data repositories to create a metadata catalog. In this article, we will learn how to catalog Amazon RDS SQL Server database objects using AWS Glue.
AWS RDS SQL Server Instance
It’s assumed that an operational instance of Amazon RDS SQL Server is already in place. If you are new to Amazon RDS for SQL Server, you can read this article, Getting started with AWS RDS SQL Server, to create a new instance. Once your instance is ready, it would look as shown below. For this exercise, any SQL Server instance using any edition of SQL Server will work. It is assumed that you have the required privileges to administer the AWS RDS SQL Server database instance.

Crawling AWS RDS SQL Server with AWS Glue
Next, you would need an active connection to the SQL Server instance. You can refer to my last article, How to connect AWS RDS SQL Server with AWS Glue, that explains how to configure Amazon RDS SQL Server to create a connection with AWS Glue. This step is a pre-requisite to proceed with the rest of the exercise. You can navigate to connections under the data catalog section in the left pane and create a new connection to the SQL Server instance. Once the connection is in place, click on the Crawlers in the left pane and you would see an interface as shown below.

Click on the Add crawler button to start creating a new crawler. The first step of defining a crawler is shown below. Provide a relevant name for the crawler. You can add tags to the crawler add more information about the crawler like purpose, owner, environment etc. Security configuration allows us to configure encryption. In our case it’s not required, so we can use the default values for the rest of the details. Once the values are filled up, click Next.

In this step, we need to specify the source data repository for the crawlers. We can select either data repositories or already cataloged objects. In our case, as we are going to point the crawler to AWS RDS SQL Server instance, we will choose the Data stores option. After selecting this option, click Next.

AWS Glue supports three types of data stores or repositories based on the mode of access. Data files hosted on S3 files, databases that support JDBC connectivity, and AWS DynamoDB database are the three types of data repositories that are supported. We would be using JDBC connectivity to connect to the AWS RDS SQL Server database instance, so select the JDBC option.

As mentioned earlier, we need to have a connection to our AWS RDS SQL Server instance to select from the connection list. If you do not have any instance available, click on Add connection and create a new connection to the SQL Server instance. The “Include path” section expects the path to database objects. It supports wild-card patterns as well as exact object paths. The format that is generally followed is mydatabase/myschema/myobjects. It’s interesting to understand the effect of providing an incorrect path. So, for now, let’s just mention the master database, and our connection also points to the master database. Alternatively, if you intend to catalog many objects, and ignore only a few objects like system objects, then you can use exclude patterns and just mention objects that should not be crawled and cataloged. After updating the details, click Next.

In this step, if we intend to add data from multiple stores using the same crawler, you can select Yes to add another data store details. Else we can select the default value No. In this case, we do not want to add any other store, so we will use the default value and click Next.

In this step, we need to select the IAM Role that would have access to the AWS RDS SQL Server instance. You can use the built-in AWS Glue Service Role that can access AWS RDS or you can create a custom role that has the required privileges. Once the role is selected, click Next.

In this step, we need to specify how frequently we intend to execute the crawler. In our case, we can select Run on-demand, so that the crawler will get executed only when we explicitly execute it. If you intend to schedule it, you can select other options as required.

In this step, we need to specify that when the database objects are crawled, where the crawler should create the metadata definition of the crawled objects. The database mentioned here is the AWS Glue database which will hold the metadata definition of the crawled objects. You can use the default database or create a new one by clicking on the Add database. In our case, we will use the default value. The rest of the options can be configured to adding prefixes to cataloged objects, configuring grouping options when AWS S3 based data, and cataloging behavior when changed to already cataloged objects are detected.

The default behavior of the crawler is to update the object definition if a change of definition is detected in the source for already cataloged objects and marked the table as deprecated if an already cataloged object is not found in the source. In our case, we can use the default values and click on Next. This will take us on the Review page, where we can review the details and click on Finish to create the crawler.

Executing crawlers with AWS Glue
Once the crawler is created, it would appear in the list as shown below. It will ask whether we want to execute the crawler. You can execute the crawler by clicking on Run it now link or selecting the crawler and clicking on the Run crawler button.

Once the crawler is executed, it will initiate a connection to AWS RDS SQL Server instance, read the definition of the objects that we mentioned in the include path, and create metadata objects in the catalog. Once the crawler completes execution you would find the details whether any new tables were created or updated. In our case, you would find that no tables got updated or created, though the crawler completed successful execution. The reason is the incorrect format of the path we mentioned in the include path setting.

For the purpose of the demonstration, we can create a new database and a table in the AWS RDS SQL Server instance as shown below. Alternatively, if you already have a database and a table, you can use the same too. Here we have the database name as “rahul” and a table named “test” in this database. And let’s say that we intend to crawl and catalog the table test.

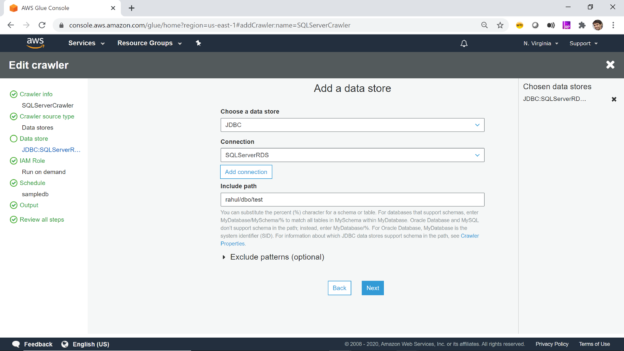
Select the crawler and click on the edit crawler to edit the crawler. Move to the step where we can configure the include path setting as shown below. Mention rahul/dbo/test as the include path, where rahul is the database name, dbo is the schema, and the test is the table. Ensure that the connection being used by the crawler also points to the same database in the AWS RDS SQL Server instance.

Save the crawler configuration and execute the crawler again. This time you should be able to see the value of 1 in the Tables added field, which means a new table was created in the metadata catalog.

AWS Glue Metadata Catalog Tables
Navigate to the Tables option under databases on the left-hand pane, there you would find the table listed with the name rahul_dbo_test. Open the table and you would find the details as shown below. It would mention the name of the crawler that created the crawler, classification of the object as sqlserver, and deprecated status as No. At the bottom, you would find the field definitions as well.

Once this table is available in the metadata catalog, you can start using it as the source or target of AWS Glue ETL jobs as shown below.

In this way, we can crawl an Amazon RDS SQL Server database instance and catalog objects in the AWS Glue metadata catalog.
Conclusion
In this article, we learned how to use AWS Glue crawlers to catalog database objects from AWS RDS SQL Server instances. We learned how to configure the crawler behavior as well as expressions to specify what objects should be crawled and cataloged. Finally, after the objects were cataloged, we explored the metadata definition of the cataloged object from the AWS Glue metadata catalog.
Table of contents
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023