
A SQL Server Computed Column is a virtual column that is not stored physically on the table, unless it is previously specified as PERSISTED. A computed Column value is calculated using a specific expression that can be constant, function, data from other columns on the same table or a combination of these types connected together by one or more operators.
The Computed Column’s value will be calculated each time the column is referenced in a query. If the Computed Column is specified as PERSISTED while creating a table using a CREATE TABLE statement or after the table creation using the ALTER TABLE statements, the column’s value will be physically stored in the table, and will be updated automatically if any column involved in the Computed Column expression is changed.
The PERSISTED property is important for the Computed Columns as many additional features depend on that property. Setting the Computed Column as PERSISTED will reduce the expression value calculation overhead at runtime but it will consume more space on the underlying disk. The Computed Column should be deterministic in order to be set to PERSISTED. For example, you can’t use the GETDATE() value in the Computed Column expression if you want to set the column to PERSISTED, as the result will be different each time you retrieve it and will not be deterministic.
The Computed Column can be referenced by a SELECT statement columns list, WHERE or ORDER BY clauses, but it can’t be used in an INSERT or UPDATE statements as the value will be calculated automatically. A Computed Column cannot be used in a DEFAULT, FOREIGN KEY or NOT NULL constraints. If the expression that is used to define the Computed Column value is deterministic, the Computed Column can be involved in a PRIMARY KEY or UNIQUE constraint. The Nullability of the Computed Column is defined automatically by the SQL Server Database Engine itself, so that, you will not specify that column property in the column definition.
Let us create two new tables in the SQLShackDemo testing database with a computed column in each table that calculate the age of the employee when he is employed to serve a certain survey required by the HR team. The first table CompanyEmployees will have a virtual Computed Column which value will be calculated at runtime, and the CompanyEmployees_Persisted table that have a PERSISTED Computed Column that will save the expression value physically in the table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
USE [SQLShackDemo] GO CREATE TABLE [dbo].[CompanyEmployees]( [EmpID] [int] IDENTITY (1,1) NOT NULL PRIMARY KEY, [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpBirthDate] [datetime] NULL, [EmpEmploymentDate] [datetime] NULL, [EmpEmploymentAgeInYears] AS (DATEDIFF(YY,[EmpBirthDate],[EmpEmploymentDate])) ) ON [PRIMARY] GO CREATE TABLE [dbo].[CompanyEmployees_Persisted]( [EmpID] [int] IDENTITY (1,1) NOT NULL PRIMARY KEY, [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpBirthDate] [datetime] NULL, [EmpEmploymentDate] [datetime] NULL, [EmpEmploymentAgeInYears] AS (DATEDIFF(YY,[EmpBirthDate],[EmpEmploymentDate])) PERSISTED ) ON [PRIMARY] GO |
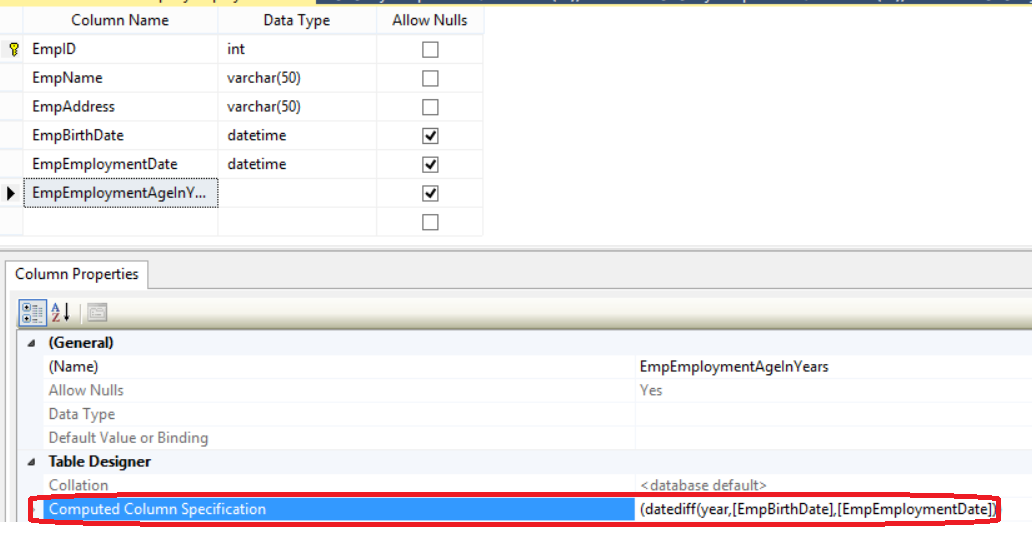
The expression of the Computed Column can be also set and modified using the SQL Server Management Studio, by opening the table design window and checking the Computed Column Specification column property as follows:
After that, we will fill the first table CompanyEmployees with one hundred thousand records using ApexSQL Generate, taking into consideration that this tool will automatically know that the EmpEmploymentAgeInYears is a Computed Column and exclude it from the insertion process:
We will fill the second table CompanyEmployees_Persisted with the same data from the first table in order to have a fair comparison during our test using the below T-SQL INSERT statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[CompanyEmployees_Persisted] ([EmpName] ,[EmpAddress] ,[EmpBirthDate] ,[EmpEmploymentDate]) SELECT [EmpName] ,[EmpAddress] ,[EmpBirthDate] ,[EmpEmploymentDate] FROM [CompanyEmployees] GO |
As we mentioned previously, the Computed Column in the CompanyEmployees table is a virtual column that will be calculated at runtime, while the Computed Column in the CompanyEmployees_Persisted table is PERSISTED, with its value saved in the table itself, consuming more space from the table. If we try to query the sp_spaceused for both CompanyEmployees and CompanyEmployees_Persisted tables:
|
1 2 3 4 5 6 |
sp_spaceused 'CompanyEmployees' GO sp_spaceused 'CompanyEmployees_Persisted' GO |
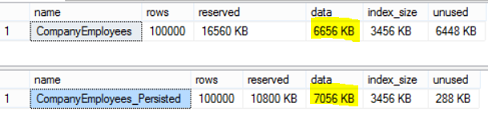
The result will show us that, the space consumed by storing the data in the CompanyEmployees_Persisted table (7056 KB) is larger than the space consumed by storing the data in the CompanyEmployees table (6656), with extra 400KB used to store the PERSISTED Computed Column values:
Looking at the other side of the performance equation, calculating the values of the virtual Computed Column at the runtime will have an extra performance overhead. If we try to run the below SELECT statements on both tables:
|
1 2 3 4 5 6 7 8 9 |
SELECT [EmpID], [Empname],[EmpEmploymentAgeInYears] FROM [dbo].[CompanyEmployees] WHERE [EmpEmploymentAgeInYears]>=50 GO SELECT [EmpID], [Empname],[EmpEmploymentAgeInYears] FROM [dbo].[CompanyEmployees_Persisted] WHERE [EmpEmploymentAgeInYears]>=50 |
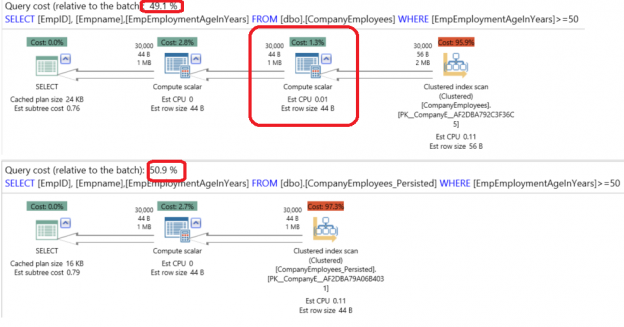
The execution plans comparison using the APEXSQL PLAN application will show us that, both SELECT statements will perform a Clustered Index Scan on the related tables with similar costs, with extra step performed on the table with the virtual Computed Column to calculate the Computed Column values as below:
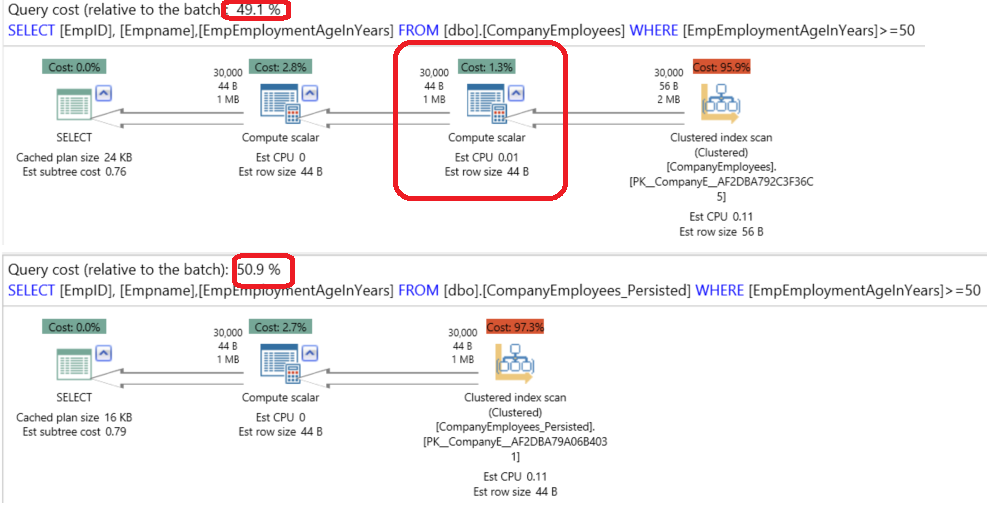
Also as expected, querying the CompanyEmployees table with the virtual Computed Columns will take more time (326 ms) than the querying the CompanyEmployees_Persisted table that took (303ms) with extra 23ms calculating the Computed Column values in the CompanyEmployees table:

To enhance the performance of the queries that reference to the Computed Colum, it is recommended to create an index on that Computed Column. There are number of requirements that should be met before adding the index.
The first requirement is that; the Computed Column expression should be deterministic. This requires that all functions that are referenced by the expression are deterministic and precise, all columns that are referenced in the Computed Column expression must be from the same table that contains the Computed Column and the expression does not pull data from more than one row such as aggregating multiple rows.
The second requirement for creating an index on a Computed Column is that the Computed Column expression should be precise. This requires that the expression data type is not Float or Real and the data type of the columns involved in the Computed Column expression is not Float or Real.
The third requirement is that the expression of the Computed Column cannot evaluate to the image, text or ntext data types. The Computed Column that is derived from these three datatypes can be involved in the non-clustered index as non-key columns in the include part of the index. Take into consideration that, if the Computed Column is PERSISTED, then you are able to create an index on the Computed Column if it is deterministic but not precise. In addition, if the Computed Column is PERSISTED and references a CLR function, you can create an index on that column without checking its deterministic, as the SQL Server Database Engine is not able to check if that function is truly deterministic and cannot prove with accuracy if a function that evaluates the computed column expressions is both deterministic and precise.
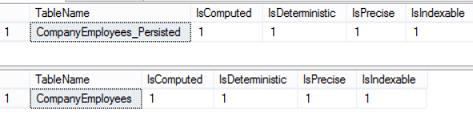
Let us check the IsComputed, IsDeterministic, IsPrecise and IsIndexable Computed Column properties from both tables created previously as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT 'CompanyEmployees_Persisted' AS TableName, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees_Persisted'), 'EmpEmploymentAgeInYears','IsComputed') AS IsComputed, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees_Persisted'), 'EmpEmploymentAgeInYears','IsDeterministic') AS IsDeterministic, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees_Persisted'), 'EmpEmploymentAgeInYears','IsPrecise') AS IsPrecise, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees_Persisted'), 'EmpEmploymentAgeInYears','IsIndexable') AS IsIndexable GO SELECT 'CompanyEmployees' AS TableName, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees'), 'EmpEmploymentAgeInYears','IsComputed') AS IsComputed, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees'), 'EmpEmploymentAgeInYears','IsDeterministic') AS IsDeterministic, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees'), 'EmpEmploymentAgeInYears','IsPrecise') AS IsPrecise, COLUMNPROPERTY( OBJECT_ID('DBO.CompanyEmployees'), 'EmpEmploymentAgeInYears','IsIndexable') AS IsIndexable |
The results from both tables show us that the EmpEmploymentAgeInYears column from these tables is Computed Column, and that the expression used to calculate its values is deterministic and precise, so that the result is that this column is indexable:
Now we will create a non-clustered index on the EmpEmploymentAgeInYears Computed Column in addition to the EmpName column as below:
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_BirthMonth ON dbo.CompanyEmployees (EmpEmploymentAgeInYears,Empname) GO |
Then trying to SELECT from that table without using the newly created non-clustered index in the first statement and using the newly created non-clustered index in the second one:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [EmpID], [Empname],[EmpEmploymentAgeInYears] FROM [dbo].[CompanyEmployees] WITH (INDEX(PK__CompanyEmp)) WHERE [EmpEmploymentAgeInYears]>=50 GO SELECT [EmpID], [Empname],[EmpEmploymentAgeInYears] FROM [dbo].[CompanyEmployees] WHERE [EmpEmploymentAgeInYears]>=50 GO |
Wow. The execution plans comparison using the APEXSQL PLAN application show us a big enhancement when indexing the Computed Column, where the performance enhanced more than 5 times when querying the indexed Computed Column as follows:
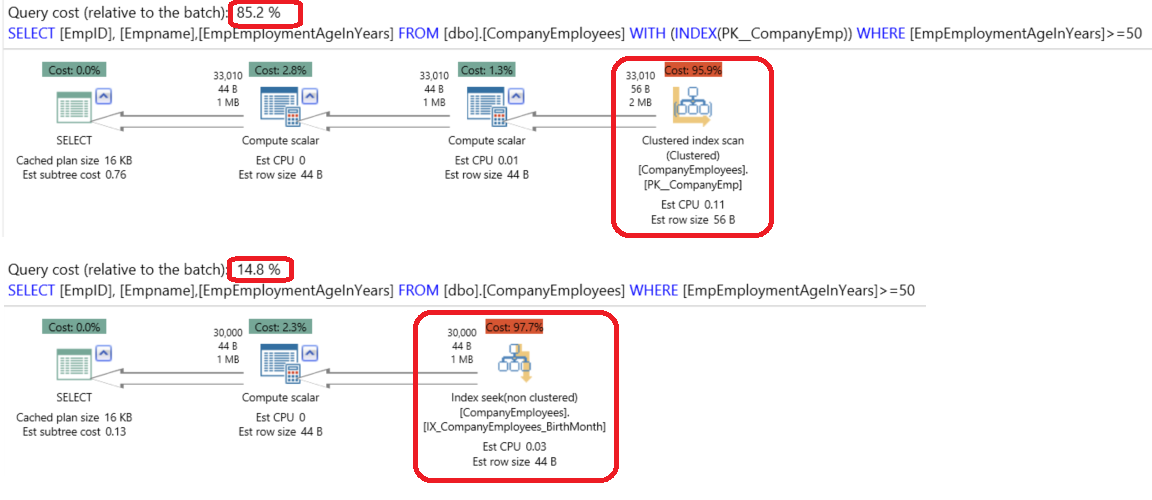
The enhancement is also made clear by checking the Time Statistics difference between the two executions. Where executing the query using the non-clustered index is better than executing it without that index by 1.2 times, as you can see from the following statistics:

Conclusion
The SQL Server Computed Column is a special type of column that can be stored in a table if specified as PERSISTED or calculated at runtime when the column is used in the query. As with any other types of columns, you can index that column to enhance the search process. There are number of requirements that the Computed Column should meet in order to be indexed. During the demo of this article, we have checked these prerequisites before creating the index. After that, we have created an index on the Computed Column and saw clearly the performance enhancement when using that index by comparing execution plans before and after the index in addition to the enhancement in the execution time.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021