

In this article, we will learn different methods that are used to update the data in a table with the data of other tables. The UPDATE from SELECT query structure is the main technique for performing these updates.
An UPDATE query is used to change an existing row or rows in the database. UPDATE queries can change all tables’ rows, or we can limit the update statement affects for certain rows with the help of the WHERE clause. Mostly, we use constant values to change the data, such as the following structures.
The full update statement is used to change the whole table data with the same value.
|
1 2 |
UPDATE table SET col1 = constant_value1 , col2 = constant_value2 , colN = constant_valueN |
The conditional update statement is used to change the data that satisfies the WHERE condition.
|
1 2 3 |
UPDATE table SET col1 = constant_value1 , col2 = constant_value2 , colN = constant_valueN WHERE col = val |
However, for different scenarios, this constant value usage type cannot be enough for us, and we need to use other tables’ data in order to update our table. This type of update statement is a bit complicated than the usual structures. In the following sections, we will learn how to write this type of update query with different methods, but at first, we have to prepare our sample data. So let’s do this.
Preparing the sample data
With the help of the following query, we will create Persons and AddressList tables and populate them with some synthetic data. These two tables have a relationship through the PersonId column, meaning that, in these two tables, the PersonId column value represents the same person.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
CREATE TABLE dbo.Persons ( PersonId INT PRIMARY KEY IDENTITY(1, 1) NOT NULL, PersonName VARCHAR(100) NULL, PersonLastName VARCHAR(100) NULL, PersonPostCode VARCHAR(100) NULL, PersonCityName VARCHAR(100) NULL) GO CREATE TABLE AddressList( [AddressId] [int] PRIMARY KEY IDENTITY(1,1) NOT NULL, [PersonId] [int] NULL, [PostCode] [varchar](100) NULL, [City] [varchar](100) NULL) GO INSERT INTO Persons (PersonName, PersonLastName ) VALUES (N'Salvador', N'Williams'), (N'Lawrence', N'Brown'), ( N'Gilbert', N'Jones'), ( N'Ernest', N'Smith'), ( N'Jorge', N'Johnson') GO INSERT INTO AddressList (PersonId, PostCode, City) VALUES (1, N'07145', N'Philadelphia'), (2, N'68443', N'New York'), (3, N'50675', N'Phoenix'), (4, N'96573', N'Chicago') SELECT * FROM Persons SELECT * FROM AddressList |

UPDATE from SELECT: Join Method
In this method, the table to be updated will be joined with the reference (secondary) table that contains new row values. So that, we can access the matched data of the reference table based on the specified join type. Lastly, the columns to be updated can be matched with referenced columns and the update process changes these column values.
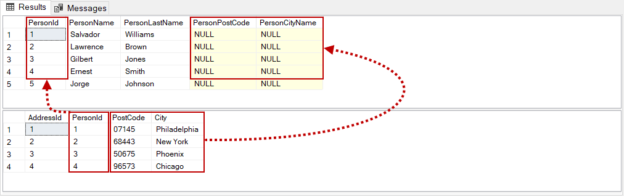
In the following example, we will update the PersonCityName and PersonPostCode columns data with the City and PostCode columns data of the AdressList table.
|
1 2 3 4 5 6 7 8 |
UPDATE Per SET Per.PersonCityName=Addr.City, Per.PersonPostCode=Addr.PostCode FROM Persons Per INNER JOIN AddressList Addr ON Per.PersonId = Addr.PersonId |

After the execution of the update from a select query the output of the Persons table will be as shown below;
|
1 |
SELECT * FROM Persons |

Let’s try to understand the above code:
We typed the table name, which will be updated after the UPDATE statement. After the SET keyword, we specified the column names to be updated, and also, we matched them with the referenced table columns. After the FROM clause, we retyped the table name, which will be updated. After the INNER JOIN clause, we specified the referenced table and joined it to the table to be updated. In addition to this, we can specify a WHERE clause and filter any columns of the referenced or updated table. We can also rewrite the query by using aliases for tables.
|
1 2 3 4 5 6 7 8 |
UPDATE Per SET Per.PersonCityName=Addr.City, Per.PersonPostCode=Addr.PostCode FROM Persons Per INNER JOIN AddressList Addr ON Per.PersonId = Addr.PersonId |
Performance Tip:
Indexes are very helpful database objects to improve query performance in SQL Server. Particularly, if we are working on the performance of the update query, we should take into account of this probability. The following execution plan illustrates an execution plan of the previous query. The only difference is that this query updated the 3.000.000 rows of the Persons table. This query was completed within 68 seconds.

We added a non-clustered index on Persons table before to update and the added index involves the PersonCityName and PersonPostCode columns as the index key.

The following execution plan is demonstrating an execution plan of the same query, but this query was completed within 130 seconds because of the added index, unlike the first one.

The Index Update and Sort operators consume 74% cost of the execution plan. We have seen this obvious performance difference between the same query because of index usage on the updated columns. As a result, if the updated columns are being used by the indexes, like this, for example, the query performance might be affected negatively. In particular, we should consider this problem if we will update a large number of rows. To overcome this issue, we can disable or remove the index before executing the update query.
On the other hand, a warning sign is seen on the Sort operator, and it indicates something does not go well for this operator. When we hover the mouse over this operator, we can see the warning details.

During the execution of the query, the query optimizer calculates a required memory consumption for the query based on the estimated row numbers and row size. However, this consumption estimation can be wrong for a variety of reasons, and if the query requires more memory than the estimation, it uses the tempdb data. This mechanism is called a tempdb spill and causes performance loss. The reason for this: the memory always faster than the tempdb database because the tempdb database uses the disk resources.
You can see this SQL Server 2017: SQL Sort, Spill, Memory and Adaptive Memory Grant Feedback fantastic article for more details about the tempdb spill issue.
UPDATE from SELECT: The MERGE statement
The MERGE statement is used to manipulate (INSERT, UPDATE, DELETE) a target table by referencing a source table for the matched and unmatched rows. The MERGE statement can be very useful for synchronizing the table from any source table.
Now, if we go back to our position, the MERGE statement can be used as an alternative method for updating data in a table with those in another table. In this method, the reference table can be thought of as a source table and the target table will be the table to be updated. The following query can be an example of this usage method.
|
1 2 3 4 5 6 7 8 9 |
MERGE Persons AS Per USING(SELECT * FROM AddressList) AS Addr ON Addr.PersonID=Per.PersonID WHEN MATCHED THEN UPDATE SET Per.PersonPostCode=Addr.PostCode , Per.PersonCityName = Addr.City; SELECT * FROM Persons |

Now let’s tackle the previous update from a select query line by line.
|
1 |
MERGE Persons AS Per |
We have typed the Persons table after the MERGE statement because it is our target table, which we want to update, and we gave Per alias to it in order to use the rest of the query.
|
1 |
USING(SELECT * FROM AddressList) AS Addr |
After the USING statement, we have specified the source table.
|
1 |
ON Addr.PersonID=Per.PersonID |
With the help of this syntax, the join condition is defined between the target and source table.
|
1 2 |
WHEN MATCHED THEN UPDATE SET Per.PersonPostCode=Addr.PostCode; |
In this last line of the query, we chose the manipulation method for the matched rows. Individually for this query, we have selected the UPDATE method for the matched rows of the target table. Finally, we added the semicolon (;) sign because the MERGE statements must end with the semicolon signs.
UPDATE from SELECT: Subquery Method
A subquery is an interior query that can be used inside of the DML (SELECT, INSERT, UPDATE and DELETE) statements. The major characteristic of the subquery is, they can only be executed with the external query.
The subquery method is the very basic and easy method to update existing data from other tables’ data. The noticeable difference in this method is, it might be a convenient way to update one column for the tables that have a small number of the rows. Now we will execute the following query and then will analyze it.
|
1 2 3 4 |
UPDATE Persons SET Persons.PersonCityName=(SELECT AddressList.PostCode FROM AddressList WHERE AddressList.PersonId = Persons.PersonId) |

After the execution of the update from a select statement the output of the table will be as below;
|
1 |
SELECT * FROM Persons |

As we can see, the PersonCityName column data of the Persons table have been updated with the City column data of the AddressList table for the matched records for the PersonId column. Regarding this method, we should underline the following significant points.
- If the subquery could not find any matched row, the updated value will be changed to NULL
-
If the subquery finds more than one matched row, the update query will return an error, as shown below:

- Many times the subquery update method may not offer satisfying performance

Conclusion
In this article, we learned to update the data in a table with the data where they are contained in other tables. The query structure, “UPDATE from SELECT” can be used to perform this type of data update scenario. Also, we can use alternative MERGE statements and subquery methods.
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023