
In this article, we are going to learn how SQL variables negatively affect query performance and also examine the causes of this issue.
Introduction
SQL variables are used to store a single data value during the execution period of a query and they are widely used in the design of the queries. The local variables are declared by the users and their name starts with @ sign. The first initialization of the value of the local variable is set to the NULL value.
The following syntax defines how to declare a local SQL variable:
|
1 |
DECLARE { @LOCAL_VARIABLE data_type [ = value ] } |
The drawback of the SQL variables is that the query optimizer can not know these variables’ values during the query plan generation process. For this reason, the query optimizer can not use statistics information efficiently. In this case, the query optimizer uses an unexact estimated number of rows of information and as a result, it can not generate effective and optimal execution plans. There is no doubt that an inefficient query plan can get us in trouble.
Pre-requirements
In this article, we will use the Adventureworks2017 sample database for our examples. At the same time, we will also use the Create Enlarged AdventureWorks Tables script to obtain an enlarged version of the Adventureworks database.
It is useful to take a look at some concepts related to the statistics without going through the details of the examples.
SQL Server Statistics
SQL Server statistics are the metadata objects that store distribution information of the column values. Statistics are the main input of the query optimizer because they hold the distribution of the table data and the optimizer uses this statistical information to estimate how many rows will be returned from a query. For the high performer queries, SQL Server requires a high degree of accuracy of this statistical information to generate more effective query plans.
- You can see the article, SQL Server Statistics and how to perform Update Statistics in SQL to learn more details about the statistics
DBCC SHOW_STATISTICS
DBCC SHOW_STATISTICS command displays the header, the density, and the histogram datasets of statistics. These datasets include detailed information about the statistics.
|
1 |
DBCC SHOW_STATISTICS ('Person.Person','PK_Person_BusinessEntityID') |

The header data shows the basic information about the statistics. It gives information about the when last update time of the statistics and rows number of tables. The rows number identifies the total number of the underlying table when the statistics were last updated. The Rows Sampled column shows how many rows were analyzed to generate the statistics.
The density vector date set shows the distribution of values. The All Density column value always between 0 and 1 and if this value is closer to zero the column values are unique.
The histogram displays the statistical distribution of the column values:
- RANGE_HI_KEY column identifies the upper bound value for a histogram step
- RANGE_ROWS column identifies the number of rows greater than the previous histogram step upper bound and not equal to the current upper bound value
- EQ_ROWS The number of rows that column value equals the upper bound of the histogram step
Estimated Number of Rows
When trying to find out a solution to a query performance problem, we often hear the name of the same property. This property is the Estimated Number of Rows and this property value is calculated using the statistics. The Estimated Number of Rows is an estimation of how many rows the operator will return per execution and it is calculated during the compilation of the query plan by the optimizer. Accuracy of the Estimated Number of Rows value calculation is significantly important for the query optimizer because a query memory amount calculation is based on the estimated number of rows and rows size if so this value is incorrect to the desired memory calculation will be incorrect.
How The Estimated Number of Rows is Calculated by The Query Optimizer
In this part of the article, we will learn how the query optimizer calculates the estimated number of rows. Firstly, we will enable the actual execution plan and execute the query using literal values.
|
1 2 3 4 |
SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate FROM Sales.SalesOrderHeaderEnlarged WHERE ModifiedDate BETWEEN '20140616' AND '20140620' |

As seen in the above image, the query plan suggests an index but before creating this index we will look at the SELECT operator OptimizerStatsUsage property. This property list all statistics names that were used during the execution of the query by the optimizer.

The LastUpdate time is equal to the execution time of the query because the Auto Create Statistics option is enabled, and the SQL optimizer creates statistics on the nonindexed columns that are used in a query predicate. As a second step, we will look at the Index Scan operator Estimated Number of Rows attribute.

The Estimated Number of Rows shows 10991,9 but how this value is calculated. The answer is very simple, using the statistic histogram. The histogram details can be displayed through the following query.
|
1 |
DBCC SHOW_STATISTICS('Sales.SalesOrderHeaderEnlarged', '_WA_Sys_0000001A_4AD81681') WITH HISTOGRAM |

In the histogram:
- 762,7984 is the number of rows that the ModifiedDate column value is equal to ‘2014-06-16’
- 4421,455 is the number of rows that ModifiedDate column value greater than ‘2014-06-16’ and ModifiedDate less than ‘2014-06-19’
- 5807,669 is the number of rows that a ModifiedDate value is equal to ‘2014-06-19’
When we sum these three values (762,7984 + 4421,455 + 5807,669 = 10.991,9224) equals the the estimated number of rows in the above execution plan.

We may ask, why a huge difference exists between the Actual Number of Rows and the Estimated Number of Rows values. The question-answer is very simple the histogram data is generated only % 5,747 of the data.

Now, we will create the suggested index and re-execute the same query.
|
1 2 3 |
CREATE NONCLUSTERED INDEX IX_ModifiedDate_001 ON [Sales].[SalesOrderHeaderEnlarged] ([ModifiedDate]) INCLUDE ([RevisionNumber],[TerritoryID]) |
After creating the index, the execution plan of the query will completely change. The clustered index scan operator replaces its place with a clustered index seek operator.

At the same time, we can not see any difference between the Actual Number of Rows and the Estimated Number of Rows values.

The SamplingPercent value shows %100 because creating an index generates new statistics to touch every column value.

When we re-calculate the estimated number of rows using the histogram.
|
1 |
DBCC SHOW_STATISTICS('Sales.SalesOrderHeaderEnlarged', 'IX_ModifiedDate_001') WITH HISTOGRAM |

In the histogram:
- 1459 is the number of rows that the ModifiedDate column value is equal to ‘2014-06-16’
- 4409 is the number of rows that ModifiedDate column value greater than ‘2014-06-16’ and ModifiedDate less than ‘2014-06-20’
- 1932 is the number of rows that a ModifiedDate value is equal to ‘2014-06-20’
When we sum these three values (1459+ 4409 + 1932 = 7800) equals the estimated number of rows in the above execution plan.
SQL Variable and Statistics Interaction
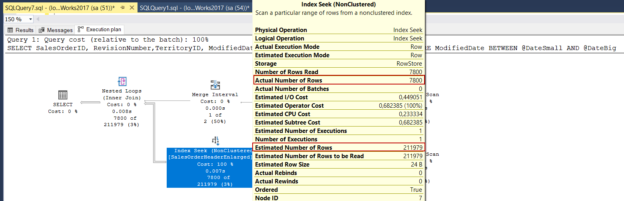
After executing the following query the query plan will change but the Estimated Number of Rows value dramatically increase.
|
1 2 3 4 5 6 |
DECLARE @DateSmall AS DATE = '20140616' DECLARE @DateBig AS DATE = '20140620' SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate FROM Sales.SalesOrderHeaderEnlarged WHERE ModifiedDate BETWEEN @DateSmall AND @DateBig |

The reason for this situation is that the query optimizer has no idea which value is held in the SQL variable so it can not use the histogram efficiently. The query optimizer uses 16% of all data as the estimated number of rows. Another interesting thing about this execution plan is that we can not see the OptimizerStatUsage option in the SELECT operator attributes.
As for how to get rid of this problem, we can use the sp_executesql stored procedure. sp_executesql is a built-in procedure that allows us to dynamically run SQL statements and it also allows us to parameterize them. In the following query, we will declare the parameter of the and then we set its values.
|
1 2 3 4 5 6 7 8 9 |
DECLARE @SQL NVARCHAR(2000) DECLARE @Param1 AS DATE ='20140616' DECLARE @Param2 AS DATE ='20140620' SET @SQL = 'SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate FROM Sales.SalesOrderHeaderEnlarged WHERE ModifiedDate BETWEEN @DateSmall AND @DateBig' EXEC sp_executesql @SQL, N'@DateSmall DATE , @DateBig DATE' , @DateSmall = @Param1 ,@DateBig=@Param2 |

As we can see in the execution plan details that sp_executesql performs much better than the query that used SQL variable.At the same time we can use RECOMPILE hint to avoid of this type of SQL variable problems.
|
1 2 3 4 5 6 7 |
DECLARE @DateSmall AS DATE = '20140616' DECLARE @DateBig AS DATE = '20140620' SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate FROM Sales.SalesOrderHeaderEnlarged WHERE ModifiedDate BETWEEN @DateSmall AND @DateBig OPTION (RECOMPILE) |
Conclusion
In this article, we have learned some hidden secrets about the statistics and how the SQL variables effects performance of the queries. The local variables are widely used by database persons but these usage types slow down the query performance due to unavailable statistical data. Using the sp_execute procedure can help to resolve this problem.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023