
In this 4th article for the Amazon Aurora series, we will discuss and implement an Amazon Aurora Serverless cluster.
Introduction
Amazon Aurora offers a managed relational database environment compatible with MySQL and PostgreSQL databases. Traditionally, database administrators monitor and manage their database environment for infrastructure resources such as storage, CPU, and memory. Sometimes, due to unexpected application load, it might be challenging to scale the resources quickly. You cannot predict the actual requirements, but you can predict based an approximate amount of resources based on past database growths.
Imagine a database that does starts, stops, increases or decreases the compute resources as per your application load. Aurora manages the storage and computes capacity for you without your intervention. It increases or decreases the capacity as per your application requirements. It charges you only for the actively used instance capacity. Therefore, if your application has free space in storage volume and aurora shrinks the resources for you, it saves the cost for you.
In the previous article, we explored the provisioned Amazon Aurora clusters. AWS provides the Serverless configuration for automatic resource management.
- Note: The term Serverless might be confusing for you. It is a term used to highlight that you do not have to manage any backend resources such as a server, hardware, storage, and networking. There are still servers, but it is not visible or accessible directly to you.
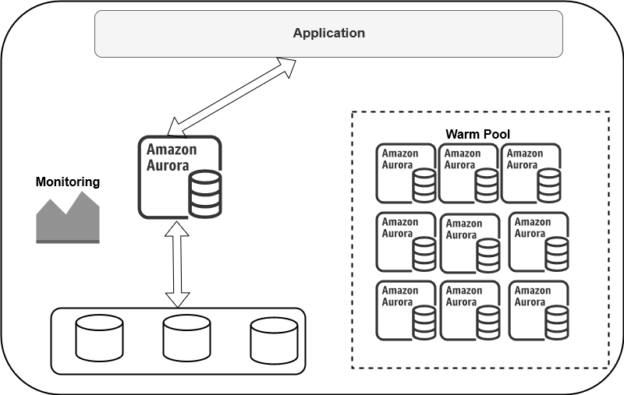
Look at the below high-level diagram for Amazon Aurora Serverless architecture:
- It maintains a warm pool of aurora instances in the serverless configuration
- The monitoring service captures and monitors the compute resources ( CPU, Memory, Storage)

If the compute threshold crosses, aurora gets the instance from the warm pool, transfers the buffer pool and distributes the workload.

Similarly, if the resource usage is low (below threshold), it reduces the capacity. It releases the instance back into the warm pool.

It pauses (stop) or resumes (start) the instances automatically based on the application workload. If there is no user workload (no active) session, it pauses the Amazon Aurora clusters. As shown below, it is a fully managed Amazon Aurora Serverless architecture that requires no manual intervention.
Autoscale Compute & Memory
Amazon Aurora Serverless uses the Aurora Capacity Unit (ACU). This ACU is a combination of CPU (processing) and RAM (memory) capacity. To create an Amazon aurora serverless cluster, we define a minimum and maximum ACU.
- Minimum ACU: It is the minimum capacity to which the aurora can scale down. The minimum ACU is 1 with 2 GB RAM
- Maximum ACU: It is the maximum capacity to scale up the aurora cluster resources. The maximum ACU is 256 with 488 GB RAM
The storage automatically scales up & down from 10 gibibytes (GiB) to 128 tebibytes (TiB) as per data requirements. It is similar to a provisioned aurora cluster. AWS uses the scaling point for resources up and down. For example, if the resources are up due to an increase in consumption, it requires a cool-down period of 15 minutes. It also follows 5 mins (310 seconds) for each cool down event.
Amazon Aurora Serverless deployment
To deploy the aurora serverless cluster, login to the AWS web console and click on Create Database in the RDS dashboard.
Select the Amazon Aurora as engine type and required compatible edition – MySQL or PostgreSQL.

In the capacity type, select the Serverless option. By default, it shows a compatible Aurora (MySQL) version however if you wish to use a specific version, check its compatibility with the serverless feature using AWS documentation.

Enter the DB cluster identifier for your serverless configuration.

Scroll down and configure the capacity settings. It is a critical parameter for your Amazon aurora serverless configuration.
Select the minimum and maximum of ACU’s from the drop-down values. We have two additional but optional configurations as well.
- Force scaling the capacity to the specified values when the timeout is reached: Aurora finds a scaling point once you change the capacity. It times out if aurora could not find out a scaling point. We can use this property to force scaling the capacity in case of timeouts
- Pause compute capacity after consecutive minutes of inactivity: If there is no activity for a specified amount of time, aurora pauses the compute capacity. For example, if we configure the 30 minutes inactivity period, Aurora pauses (stops) the compute once it has 30 minutes of idle time. It does not charge you when the cluster is in pause status. It reduces for aurora billing. In this case, it only charges you for the database storage. Later, once a user connects, it resumes the cluster operations automatically

Scroll down, and in the additional network configuration, you can enable the Data API. It enables the SQL HTTP endpoint that you can use to run the SQL queries without any external client tools. You can directly use the RDS console to query the database.

The remaining configuration is similar to a provisioned aurora database cluster. Once the cluster is deployed, you can see it does not show you cluster and writer\reader replica details.

Connecting to your Amazon Aurora Serverless Clusters
You can connect to your Amazon Aurora Serverless cluster in the following ways:
Using the Aurora endpoints: It is a similar way of connecting using a provisioned aurora cluster. You can use endpoint information and connect using MySQL clients or applications. You can refer to the article, Rewind or Forward the Amazon Aurora Cluster using the backtrack feature for more details

Using in-built RDS query

You can directly query the aurora serverless cluster in the RDS console. Select the cluster and go-to actions -> Query.

It opens the connect to database menu. On this page, enter the following information:
- Database cluster name: It is auto-filled information for your aurora cluster
- Database user name: Enter the credentials that we specified for aurora cluster creation. In my case, it is the admin user id
- Enter database password: Specify the password for the admin user
- Enter the name of the database: We entered the [SQLShackDemo] database in the initial database creation option during cluster formations. You can specify the database name or skip it
- Query statement separator: You can choose the query statement separator. Usually, it uses semicolon for this purpose

Click on Connect to the database. It connects to the database and displays a query to return the tables information from the information_schema.

Click on Run, and it returns the result in the bottom window. You can export the results in a CSV format as well.

Let’s create a MySQL table and insert records into the [SQLShackDemo] database using an in-built query editor. Write your MySQL statements and execute them.

In the below image, we see the table records of [authrordata] table:

Checking the ACU utilizations and logs
Click on the aurora cluster name in the RDS dashboard and navigate to the Monitoring tab. On the monitoring tab, we can see a few useful graphs:

- Serverless Database capacity: In this graph, we can see ACU utilizations. We can see that aurora changes the ACU based on the requirements
- CPU utilization: Once the CPU utilization increases above a threshold, it increases the serverless database capacity
- DB Connections
To check more details, we can view aurora cluster logs. In the aurora logs, you can see the timestamp for the aurora DB cluster pause, resume, scaling up and down.
In the last line, we see that it scales down the capacity from 4 capacity units to 2 capacity units due to autoscaling.

In the idle database, you can note that the size reduces to zero capacity units.

You should clean up your AWS resources to avoid the cost if there are not in use. To do so, select the cluster and click on Delete.

Conclusion
In this article, we explored the Amazon Aurora Serverless architecture and configurations. It automatically aligns the resources based on the application workload, connections, CPU and memory usages.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023