
In this article, we will be discussing Microsoft Neural Network in SQL Server. This is the seventh article of our SQL Server Data mining techniques series. Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, and Linear Regression are the other techniques that we discussed until this article.
What is an Artificial Neural Network?
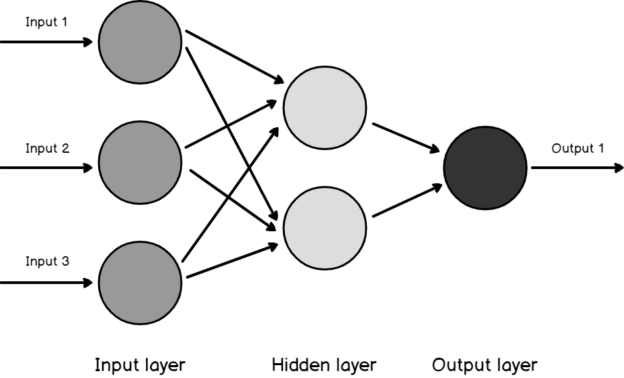
An Artificial Neural Network (ANN) can be considered as a classification and as a forecasting technique. Microsoft Neural Network in SQL Server is typically a more sophisticated technique than Decision Trees and Naïve Bayes. This technique tries to simulate how the human brain works. In this technique, there are three layers, Input, Hidden, and Output, as shown in the below screenshot.
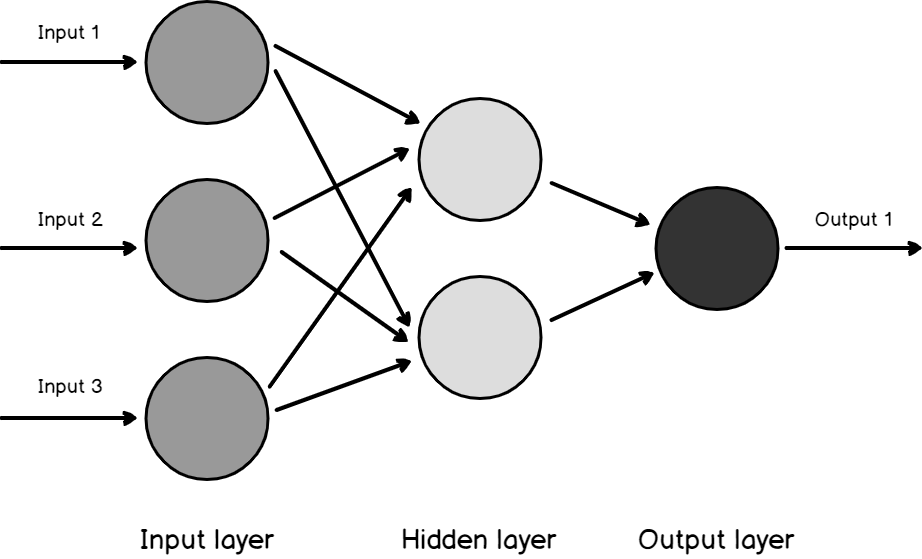
The input layer is mapped to the input attributes. If you remember the AdventureWorks example, we are looking at Age, Gender, Number of Children are the inputs to the Input layer.
The Hidden layer is an intermediate layer where every input with weightage is received to each node in the hidden layer.
The Output layer is mapped to the predicted attributes. In our AdventureWorks example, Bike Buyer will be mapped to the output layer.
A neuron is a basic unit that combines multiple inputs and a single output. Combinations of inputs are done with different techniques, and the Microsoft Neural Network uses Weighted Sum. Maximum, Average, logical AND, logical OR are the other techniques used by the different implementation.
After these inputs are calculated, then the activation function is used. In theory, sometimes, small input will have a large output, and on the other hand, large input might be insignificant to the output. Therefore, typically non-linear functions are used for activation. In Microsoft Neural Network uses tanh as the hidden layer activation function and sigmoid function for the output layer.
Backpropagation
Backpropagation is the core part of the Artificial Neural Network. Unlike other techniques, this technique has the learning capability. The Learning capability is achieved via Backpropagation. In this technique, the error is calculated, and the weights points will be modified.
Let us see how Microsoft Neural Network in SQL Server works.
- At the initial stage, random values between -1 to 1 are assigned as weightages
- For the training set. The algorithm calculated the output and output error
- The Backpropagation process calculates the error for each output and hidden neurons in the network
- The weightages are modified
- Repeat from step 2 until the condition is satisfied with minimum error
Implementing an Artificial Neural Network in SQL Server
Let us do the same example of Bike Buyer that we did for Naïve Bayes and Decision Trees. Like we did for all the other examples, let us create the Data Source pointing to the AdventureWorksDW database and Data Source View with vTargetMail.
Then let us select the Microsoft Neural Network, as shown in the following screenshot.
Then let us select the Input and Predict attribute, as shown in the below screenshot.
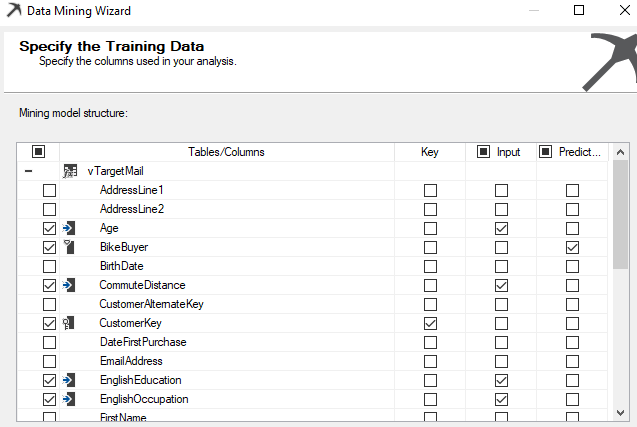
We have chosen input attributes that will make sense to predict the bike buyer. For example, we do not think that attributes such as Address, email address are important variables.
Next is to change the Content-Type. Though Neural Network supports continuous types, in this example, only Yearly Income should be continuous, and other content types should be changed to Discrete due to the nature of the data set. After those changes, the screen should be as follows.
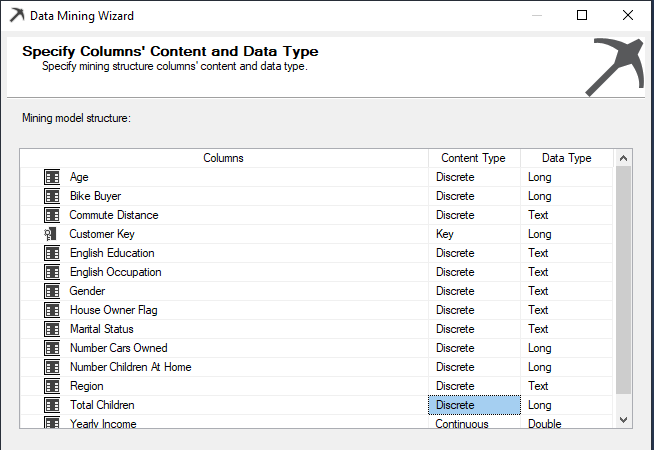
After this modification, the rest of the wizard can be configured with default values, as we discussed in our first article of the series.
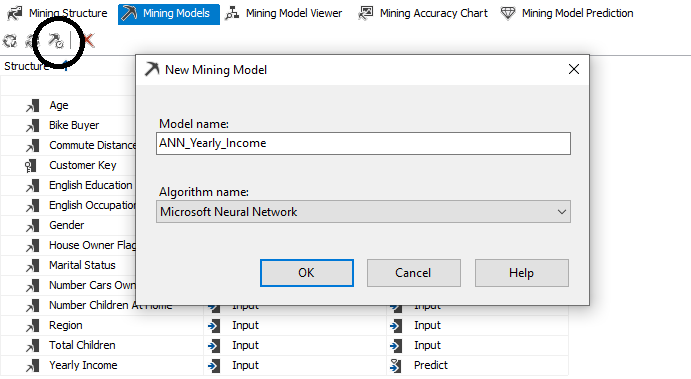
The above model is to perform classification whether the customer is a bike buyer or a not. Now, let us add another neural network model to forecast yearly income, like the decision tree algorithm, Microsoft Neural Network in SQL Server can be used as a classification and forecasting technique.
You can add another mining model the same structure without creating another structure, as shown in the below screenshot.
After the model is created, you need to change the Yearly Income to predict, as shown in the below screenshot.
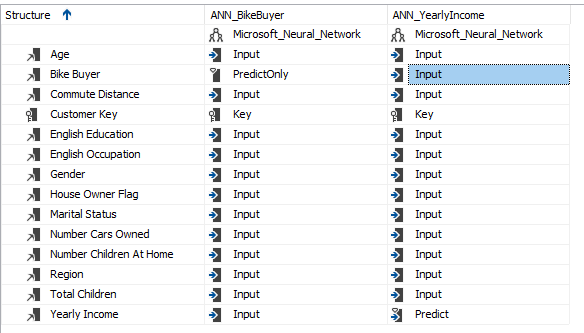
Now you have two mining models in the same data mining structure.
Then let us process both models together and view the results. Further, if you want, you can process the model by model.
Model Viewer
Let us view the results for the Bike Buyer prediction model built using the Microsoft Artificial Neural Network algorithm, as shown in the below screenshot.
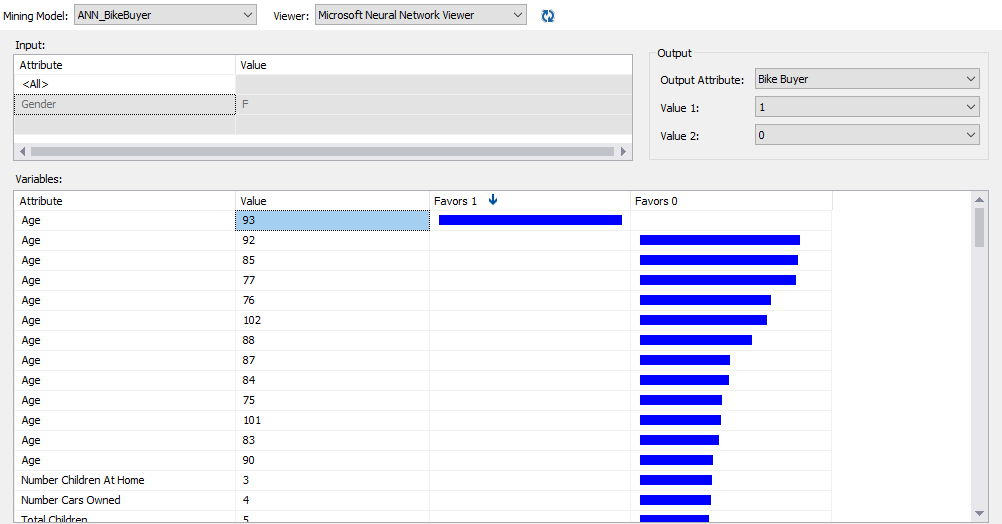
Above screenshot indicates that Customers whose age is 93 are more favorable of buying a car. Further, we can filter the results. The following screenshot shows the results for Single, Female who has two cars.
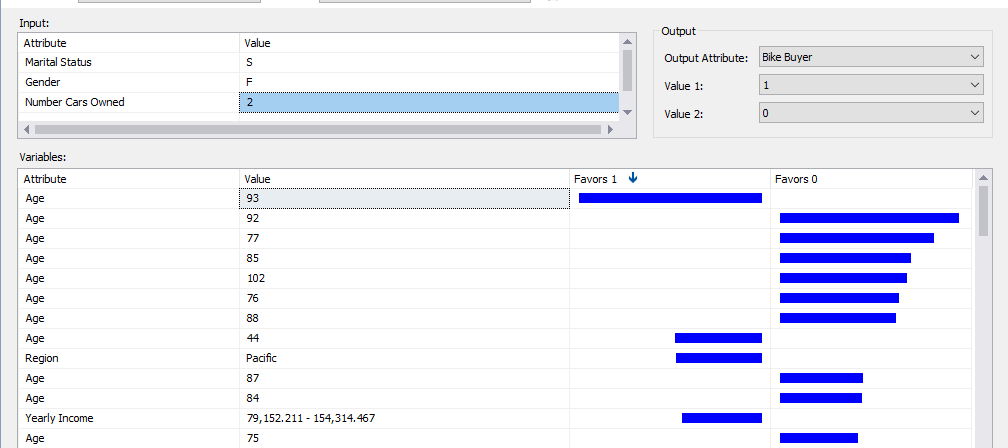
By analyzing these views, the user can understand what are contributing attributes towards the classification of a Bike Buyer.
Let us look at the Year Income prediction model viewer, as shown in the below screenshot.
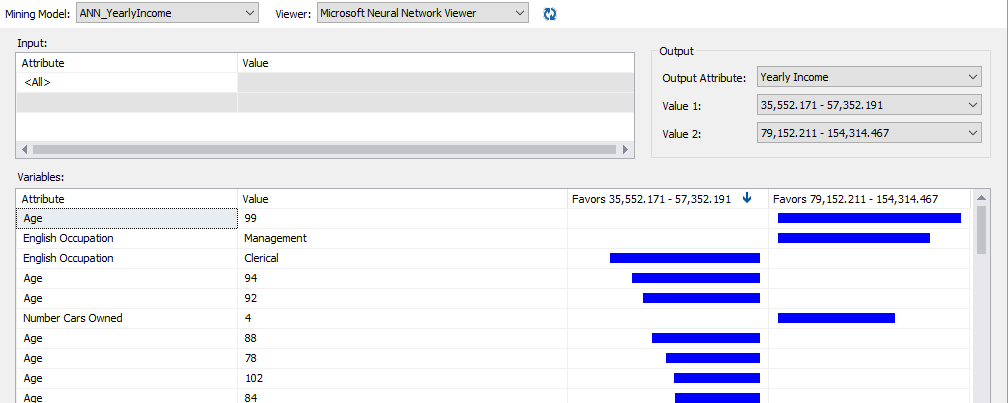
Since Yearly Income is a continuous attribute, you can choose them in ranges, as shown above. In this model, we can filter for several attributes. Similarly, you can get an understanding of what are the most significant factors for each range of Yearly Income attribute.
Prediction
Let us see how we can use these models to predict. As we discussed in the previous article, Microsoft Neural Network in SQL Server can be used to predict from DMX queries and the provided user interface.
Following is the user interface for making predictions:
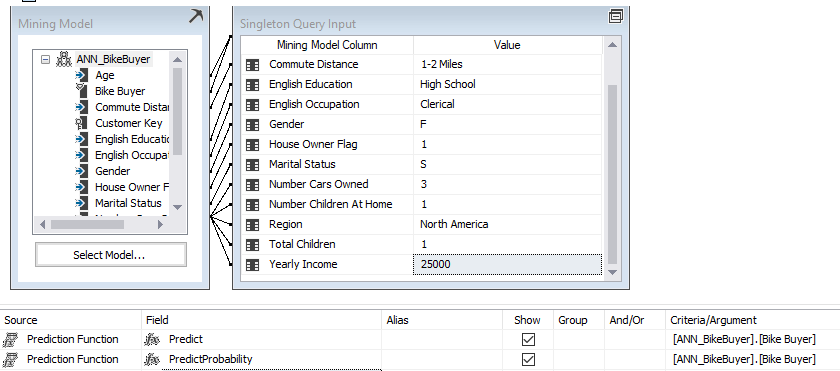
The same results can be achieved by using a DMX query from the SQL Server Management Studio (SSMS), as shown in the below screenshot.
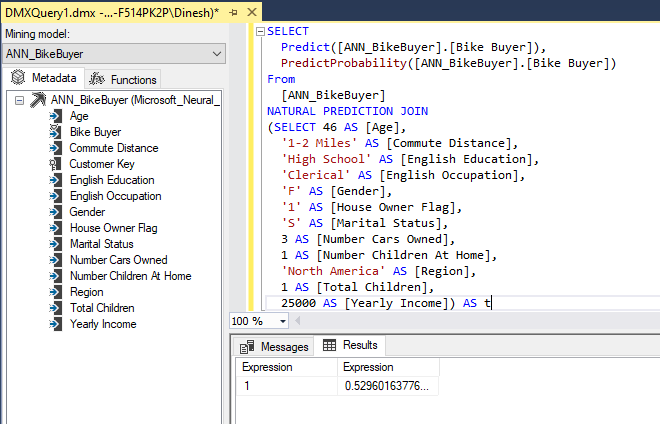
Let us forecast the Yearly Income using the ANN_YearlyIncome model from the DMX, as shown below.
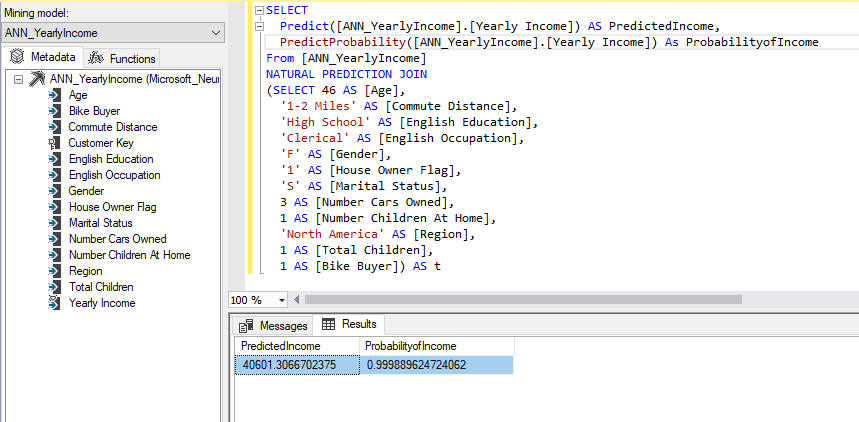
In case you are accessing data mining models from the application, DMX queries can be used.
Model Parameters
There are Microsoft Artificial Neural Network related model parameters to achieve better results. As we discussed in the previous articles, by changing the parameter values, you will be able to achieve better results. All of these parameters are available only in Enterprise edition.
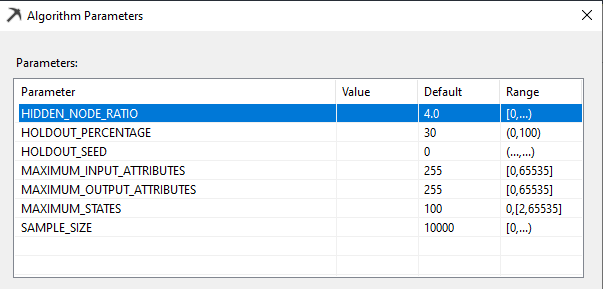
HIDDEN_NODE_RATIO
This parameter specifies a number used in determining the number of nodes in the hidden layer. The algorithm calculates the number of nodes in the hidden layer as HIDDEN_NODE_RATIO * sqrt({the number of input nodes} * {the number of output nodes}).
HOLDOUT_PERCENTAGE
This parameter specifies the percentage of cases within the training data used to calculate the holdout error for this algorithm. HOLDOUT_PERCENTAGE is used as part of the stopping criteria while training the mining model. The default value for this parameter is 30.
HOLDOUT_SEED
This parameter specifies a number to use to seed the pseudo-random generator when randomly determining the holdout data for this algorithm. This value is unique to this algorithm and is unrelated to any holdout parameters set in the mining structure. The default values for this parameter is 0
SAMPLE_SIZE
This parameter defines the number of cases that are used to train the model. The algorithm either uses the number specified by SAMPLE_SIZE or total_cases * (1 – HOLDOUT_PERCENTAGE/100), depending on which one is smaller.
Conclusion
Microsoft Artificial Neural Network in SQL Server is one of the most sophisticated algorithms available in the SQL Server Data Mining family. This technique tries to simulate how the brain works with input and outputs. Further, this technique can be used to solve classification and regression problems like the Decision Tree algorithm. Both discrete and continuous input variables can be used for this technique.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021