

In this article, we will learn how to ingest data into Azure Synapse Analytics with a focus on using PolyBase to load the data.
Introduction
Azure Synapse Analytics is Microsoft’s data warehousing offering on Azure Cloud. It supports three types of runtimes – SQL Serverless Pool, SQL Dedicated Pool, and Spark Pools. As there are a variety of data sources on Azure, it’s very obvious that there can be varying types and volumes of data that would have to be loaded into Azure Synapse pools. There are three major types of data ingestion approaches that can be used to load data into Synapse. The COPY command is the most flexible and elaborate mechanism, where someone can execute this command from a SQL pool to load data from supported data repositories. This command is convenient to load ad-hoc and small to medium-sized data loads into Synapse. The second method of loading data is the Bulk Insert, where the method name is self-relevant regarding the approach functionality. To ingest the data from supported repositories into dedicated SQL pools, PolyBase is as efficient and at times it’s even more efficient than the COPY command. This article will help you understand the process to ingest data into Azure Synapse Analytics using PolyBase to load the data.
Pre-requisites
To load the data the first pre-requisite is that we need to have some sample data. Azure SQL Database is one of the most frequently used sources of relational data. While creating it, we have the option to create it with sample data as well. It’s assumed that an instance of Azure SQL Database is already in place and populated with sample data.
Secondly, as we are going to load data in Azure Synapse Analytics, we need an instance of synapse created with a dedicated SQL pool. As polyBase works best with dedicated SQL pools, we are considering loading data into a dedicated pool instead of an on-demand serverless SQL pool. It’s assumed that an instance of Azure Synapse Analytics dedicated pool is ready to use. One of these pre-requisites are in place, we can proceed with the next steps.
Ingesting data with PolyBase
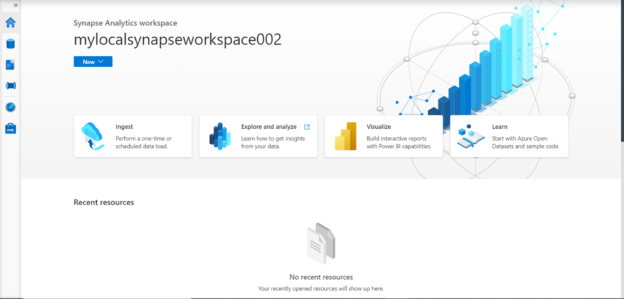
Open Synapse Studio from the Azure Synapse Analytics workspace, and it looks as shown below. This is the gateway for us to start the process of developing a data pipeline that would load data into Azure Synapse Analytics.

As we intend to ingest data into the dedicated SQL pool of Azure Synapse Analytics, we will click on the Ingest tile, which will invoke the Copy Data wizard which we typically use while working with Azure Data Factory. Once this screen pops-up, it would look as shown below. The first step is to provide a name and description for the ingestion pipeline that we are going to create. We can select a task cadence or schedule when this task or pipeline should be executed. The default frequency is Run once now, which works for us. So we will leave it to the default value and click on the Next button.

In the next step, we need to select the data source from which we are going to load the data. Azure Synapse Analytics supports many types of data sources. In our case it’s Azure SQL Database, so select the same as shown below.

In the next step, we need to provide the connection details as well as credentials of the Azure SQL Database. Once done, click on the Test connection button as shown below to test the connectivity. Once the connectivity is successful, we can move to the next step by clicking on the Next button.

In the next step, we need to select the desired database objects i.e. tables or views, which will create the dataset that would be populated into the dedicated SQL pool. Select the tables as shown below and click on the Next button.

We can configure the properties like query time out, isolation level, partition options, etc. before moving to the next step as well as shown below. We can view the schema as well as preview the data too.

In this step, we need to select the destination now, which is Azure Synapse Analytics. Select the destination as shown below and click on the Continue button.

Configure the connection properties and credentials of the SQL pool as shown below. Once done, click on the Test connection button to test the connectivity with this pool. Ensure that you specify SQL pool with SQL authentication, as it’s very easy to confuse the dedicated SQL pool with an on-demand serverless SQL pool. Once the connection is successful, click on the Create button and move to the next step.

In this step, now that we have already selected the source and destination, we need to provide the mapping details to specify that data from source tables will be loaded into which destination tables along with field-by-field mappings. We have the option to use an existing table or create a new table altogether. For now, we will assume that we do not have any tables already in the destination, and so we will create new tables. We have the option to specify the schema and name of the target tables that would be created when the pipeline is executed. Once done, click on the Next button.

In the next step, we need to configure the Settings at the data pipeline level. One of the key settings is data consistency verification – which verifies the source data with the data populated in the destination. We can specify the fault tolerance level and whether to log the pipeline execution details. The next setting is whether to stage the data before loading it into the dedicated SQL pool. We would need to stage the data to use polyBase, so keep this setting on.

As we are going to use staging in the data pipeline, we need to provide a linked service where the data can be staged. We can use a Data Lake Storage Account Gen2 to stage the data. Either create a new account or use an existing account to use for staging as shown below. Once the staging account has been created, specify the path in the storage account where the data can be staged.
The next important setting is the Copy method, which is the most critical setting in the flow. This determines whether polyBase or copy command or bulk insert mechanism would be used to load the data in Azure Synapse Analytics.

Scroll down and then you should be able to see the configuration details related to PolyBase. Although we can configure these details, for now, we can continue with the default configuration. Configuring the details related to polyBase provides more fine-grained control on how polyBase will deal with data, parallelism and errors while loading the data. Once done, click on the Next button to proceed to the next step.

Now we are on the Summary step, where we just need to review the details of all the configurations we have done so far. Ensure that the details are accurate and proceed to the next step. Please keep in view that as soon as we proceed to the next step, it would start the execution of the data pipeline.

In this final step, which is the Deployment step, the pipeline would be deployed or executed, which means that it will populate the data from Azure SQL Database to the dedicated SQL pool of Azure Synapse Analytics. To verify that the data loaded successfully, we can log on to the dedicated SQL pool using SQL Server Management Studio (SSMS) and verify that the new tables got created and the data got populated into those new tables.

In this way, we can easily create a data pipeline to ingest data into Azure Synapse’s dedicated SQL pool.
Conclusion
In this article, we started with an existing setup of Azure SQL Database with sample data as the source and an instance of Azure Synapse Analytics’s instance with a dedicated SQL pool. We used Synapse Studio to create a data pipeline that would load the data from Azure SQL Database into the dedicated SQL pool using PolyBase as the mechanism for data load and learned the configuration options for creating a data pipeline as well as for using PolyBase.
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023