

In this article, we’ll present a couple of common best practices regarding the performance of Integration Services (SSIS) packages. These are general guidelines for package design and development which guarantee a good performance in most use cases. However, there are always exceptional cases and outliers. The mantra of “measure twice, cut once” also applies here. Thoroughly test any changes to your packages to conclude that a change made a positive effect. This means not only running the in the designer, but also on the server. Also, this article is not an exhaustive list of all possible performance improvements for SSIS packages. It merely represents a set of best practices that will guide you through the most common development patterns.
Let’s get started with data flow performance.
#1 Use a SQL statement in the source component
Well, this only applies of course if your source supports SQL. For a flat file, you just need to select the columns you need. The idea behind this statement is that when you write a SQL statement that will already optimize the data for the SSIS data flow:
- You only select the columns that you need
- You already perform the necessary data type conversions using CAST or CONVERT
- You can already perform complex logic such as joining different tables together
- You can filter the data
- You can sort the data if needed
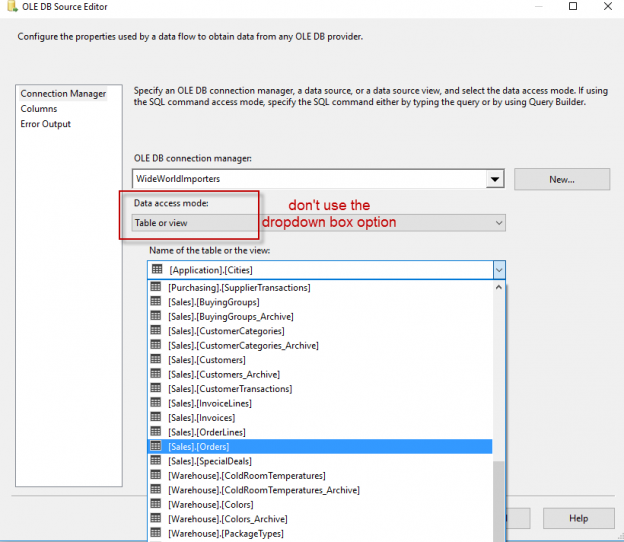
Whatever you do, don’t use the dropdown box to select a table. There’s no logic you can add, it will select all columns and all rows of the table and it’s actually slower than using a SQL statement (as it uses OPENQUERY behind the scenes).

Change the Data Access Mode to SQL Command or SQL Command from variable. The second option is useful if you want to dynamically build your query using expressions.
#2 Get as many rows as you can into a buffer
The SSIS data flow uses memory buffers to manage the data flowing through the data flow. It’s very important that you can get as many rows into one single buffer. Imagine a line of people passing buckets to put out a fire. The more water you can get into a bucket, the quicker you can put out a fire. To achieve this goal, you can take two actions:
- Only select the columns you need (that’s why #1 is important). If you bring unnecessary columns into the data flow, you waste precious buffer space.
- Keep the columns as small as possible. If the total row length is smaller, you can fit more rows into a buffer. Try converting the columns to a smaller size in the source if possible (see also #1). The data flow takes the maximum size of each column to calculate the total row length. For example, if a column has the size VARCHAR(4000), the data flow will assume a length of 4000 bytes, even if the actual rows contain much less data.
#3 Don’t use the default buffer settings
While we’re on the topic of buffers, let’s look at some data flow properties:
- DefaultBufferSize: the default size of a buffer which is set to 10MB.
- DefaultBufferMaxRows: the default number of rows the data flow will try to put in a buffer. This is set to 10,000 rows.
When calculating the buffer size, the data flow uses these two properties. If one property is reached, the size of the buffer is not further enlarged. For example, if the row size is 1MB, the data flow wil put 10 rows into the buffer, since the maximum buffer size will then be met. If the row size is only 1KB, the data flow will use the maximum of 10,000 rows.

These two default settings haven’t been changed since the release of SSIS in 2005. Apparently, a time where memory was still crazy expensive. The first thing you’ll want to do is set these properties to a much higher value. There’s no “golden” number that will guarantee optimal performance all the time. Sometimes a smaller buffer is better if the source is really slow, sometimes a bigger buffer is better if you don’t have many columns and a very fast source. Keep in mind that buffers can be too big as well. Think about the line of people passing buckets. If the buckets are too big, it takes too long to fill them with water and the fire still rages on. In reality, it takes some testing to find the optimal settings for your data flow. Typically I run my package first with the default settings and I monitor the execution time. Then I enlarge the buffers – to 30MB and 50,000 rows for example – and see what effect it has. And then I try to determine if the package is better off with even larger buffers, or if they need to be a bit smaller.
Luckily, all this testing can now largely be avoided by one new property introduced in SQL Server 2016: AutoAdjustBufferSize. When this property is set to True, it will automatically adjust the size of the buffer so that the DefaultBufferMaxRows setting is met. For example, if you have set it to 40,000 rows, the data flow will automatically scale the buffer size so that the buffers will contain 40,000 rows. Unfortunately, this property is set to False by default.
In conclusion, make those buffers bigger. This can really have a drastic impact on the performance.
#4 Avoid blocking transformations
Even if you followed the previous tips to the letter, performance can still be terrible if you use a blocking transformation. These are the types of transformations in a data flow:
- Non-blocking. The buffers are unchanged and “flow” through the transformation. The data flow performs the transformation on a memory buffer and moves on to the next. Examples are: derived column, data type conversion, conditional split …
- Semi-blocking. The buffer can change in size; either in the number of columns or in the number of rows. However, there is no blocking behavior. Examples are the Union All, Merge and Merge Join.
- Blocking. The bane of SSIS performance. These transformations need to read all the buffers before they can output even one single buffer. This can lead to memory pressure which causes the SSIS package to spill to disk. In other words, your package runs now for hours instead of minutes or seconds. Examples are Sort and Aggregate.
All transformations can also be divided into two categories: synchronous and asynchronous. Synchronous means the buffer doesn’t change in size at all. All non-blocking transformations are synchronous. Sometimes this isn’t obvious: the Multicast component creates multiple output paths, which seems like multiple buffers are being created. However, behind the scenes it’s still the same memory buffer. Asynchronous components do change the size of the buffer. Columns can be added or removed. Rows can be added or removed as well. All blocking and semi-blocking transformations are asynchronous.
The rule is simple: avoid asynchronous transformations. In most cases, these are blocking anyway. The Union All has the benefit of the doubt: it’s the least bad asynchronous transformation. However, if you can design your package so you can avoid it, it’s recommended that you do. The Merge and Merge Join are to be avoided as well, because they require sorted input. You can sort in the data flow, but the Sort component is a blocking transformation, so it needs to be avoided. An alternative is to sort in the source component, for example by adding an ORDER BY clause to the SQL statement. The data flow needs to know the data is sorted though. You can do this by setting the IsSorted property to true on the output in the Advanced Editor (to open the advanced editor, right-click on the source and select it from the context menu).

You also need to indicate which columns are sorted. Keep in mind that this doesn’t sort the data for you! This is just metadata information.

#5 Don’t use the OLE DB command transformation
Don’t use it. Ever. Unless you have really small data sets and you’re 100% sure they won’t grow. The OLE DB command executes the SQL statement for every row in the buffer. This means if 1 million rows pass through the transformation, the SSIS package will sent 1 million SQL statements to the server. Most likely the transaction log will blow up and it might even fill your disks completely.
A work around is to write the records to a staging table and then use a Execute SQL Task to do a set-based SQL statement. In other words, use the Execute SQL Task to run one single UPDATE statement instead several thousand UPDATE statements.
Stay tuned for more performance tricks in next article Integration Services (SSIS) Performance Best Practices – Writing to the Destination.
Reference links
- Understanding Synchronous and Asynchronous Transformations
- Non-blocking, Semi-blocking and Fully-blocking components
- Sort Data for the Merge and Merge Join Transformations
- Data Flow Performance Features
See more
For a collection of SSIS tools including SSIS package comparison, SSIS system performance monitoring and SSIS documentation, see ApexSQL SSIS tools


Koen has over 7 years of experience in developing data warehouses, cubes, and reports using the Microsoft BI stack. Somehow he has developed a particular love for Integration Services along the way.
He has a blog at http://www.sqlkover.com and he is a frequent speaker at local SQL Server events. You can find him on Twitter as @Ko_Ver.
View all posts by Koen Verbeeck