

Introduction
There are three types of physical join operators in SQL Server, namely Nested Loops Join, Hash Match Join, and Merge Join. In this article, we will be discussing how these physical join operators are working and what are the best practices for these different joins.
As you are aware, there are different types of logical joins, Inner Join, Outer Join (Left, Right, Full) and cross joins that you performed in order to achieve the required results as shown in the below figure.

Source: https://www.reddit.com/r/SQL/comments/aysflk/sql_join_chart_custom_poster_size/
Depending on data volume and the available indexes, different types of physical join operators are used. Therefore, by knowing the details of physical operators, you can improve query performance.
Nested Loops Join
Nested Loops Join has a very simple mechanism. Out of the two tables, the table with a smaller number of records is selected, and it will loop through the second table until matches are found. As you can see this is a not very scalable option for large tables. Hence this is mainly used when there is a table with a smaller number of records and the joining column is indexed in the second table.
Let us create two simple tables with the following scripts.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE Table1 (ID INT) INSERT INTO Table1 VALUES (1),(5),(3),(6),(7) CREATE TABLE Table2 (ID INT PRIMARY KEY CLUSTERED) INSERT INTO Table2 VALUES (1),(2),(5),(6),(3),(8),(7) |
The above script will create two tables and insert few records. Let us join these two tables with the following query.
|
1 2 |
SELECT * FROM Table1 INNER JOIN Table2 ON Table1.ID = Table2.ID |
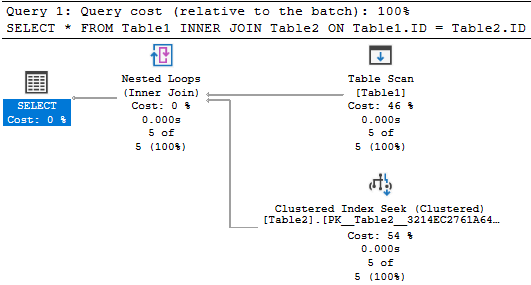
You will see the following query plan from the following figure for the above query.

As seen from the above execution plan, the smaller table is selected as the outer table and nested loops join will occur with the inner table.
It is important to remember that you don’t need to join these tables in the same order in your script. Even if you join them differently, the database engine will use the same query plan by identifying the table with smaller records. If you execute the following query, you will get the same execution as above.
|
1 2 |
SELECT * FROM Table2 INNER JOIN Table1 ON Table2.ID = Table1.ID |
There are several other usages of the Nested Loops physical join that are listed below.
Key Lookup
Not only for table joins, but Nested Loops joins are also used for key lookups. Let us run the following query in the sample database, AdventureWorks database on the Product table in which there is a clustered index on the ProductID column and a non-clustered index on the ProductNumber column.
|
1 2 3 |
SELECT ProductID, Name FROM Production.Product WHERE ProductNumber = 'CA-6738' |
Since there is a non-clustered index on the ProductNumber column, mostly likely that the non-clustered index will be used. Please note that if there are large number of records, there can be a situation where it will perform a clustered index scan instead of the Non-Clustered index seek.
Let us look at the query plan for the above query.

Though no join statement is used in the above query, it has used a Nested Loops join in order to combine the Non-clustered index and retrieve the Product Name from the clustered index. If you want to avoid the Nested Loops join, you can create an include index as shown below.
|
1 2 3 4 |
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_ProductNumber2] ON [Production].[Product] ( [ProductNumber] ASC ) INCLUDE (Name) |
Then the new query plan would look like the following and you will see that nested loops join is removed.

Since new query requirements can be covered from the non-clustered index, there is no need to fetch data from the clustered index. Therefore, the requirement of Nested Loops joins will not be there.
Cross Join
When cross joins are performed, the only possible way of joining these tables is via Nested Loops Join. Let us execute the following query to observe the different scenarios.
|
1 2 |
SELECT * FROM Sales.SalesOrderHeader CROSS JOIN Production.Product |
You will see from the following query plan that Nested Loops Join is used ignoring the sizes of the table.

Thus, the Cross Join queries are slower and should not be used against large volume tables.
Table Variable
Let’s see what is the behavior of the Joins when the table variable is used to join. To Demonstrate, we will use the following query with a table variable.
|
1 2 3 4 5 6 7 8 |
DECLARE @ProductTable TABLE (ProductID INT,ProductName VARCHAR(50)) INSERT INTO @ProductTable (ProductID,ProductName) SELECT ProductID,Name FROM Production.Product SELECT D.ProductID,D.OrderQty,P.ProductName,D.UnitPrice,D.LineTotal FROM Sales.SalesOrderDetail D INNER JOIN @ProductTable P ON D.ProductID = P.ProductID |
You will see the following query plan for the above join query.

This is due to the fact that the database engine is estimating that the Table variable has one record. Since a table with one record is a small table, the above query uses the Nested Loops join.
This can be verified from the query plan as shown in the below figure.

As you can see, though there are 504 records in the table, the engine has been estimated for only one record.
Merge Join
The Merge join is the most efficient join in SQL Server. In simple terms, if you see a Merge Join, your query plan is an efficient query plan and you do not need to do many changes to improve query performances. Since the Merge Join operator uses sorted data inputs, it can use any two large datasets.
Let us look at the following query.
|
1 2 3 |
SELECT* FROM Sales.SalesOrderDetail D INNER JOIN Sales.SalesOrderHeader H ON H.SalesOrderID = D.SalesOrderID |
The following figure shows the query plan for the above query which shows Merge Join.

You need to verify how it receives the sorted input to the Merge Join. If it receives data from the index, then it would be fine. However, if SQL Server does perform any operation to sort the data stream, then you may need to look at the indexes and better try to modify the indexes in order to achieve better results.
Further, if there are duplicates for the joining conditions or many to many relationships between the join conditions, a Work table will be created in the tempdb which may result in performance issues and Tempdb contention. Therefore, if there are duplicates you may try to resolve those data duplication issues before joining the tables if possible.
Hash Match Join
The mechanism for hash match Join is to create a hash table and then match records. Hash table creates in the memory. However, since Hash Match Join will be used for a large dataset, most likely that memory will not be sufficient to hold the data. In that type of situation, Hash Match Join uses tempdb heavily. Further, Hash Match Join is a blocking join that means until the entire join is completed, users will not get the data output. These two properties make Hash Match join a slow operator to join tables in SQL Server. In the case you observe a Hash Match Join in the query plan, you need to look at how to improve the performance. In the case of a data warehouse, hash joins are fine but not for transactional systems. Mainly, you need to look at modifying the indexes or include new indexes. In addition, you may look at the options of rewriting the queries.
One important factor to note here, that Hash Match Join is utilized only for Equi joins.
Summary
In this article, we looked at different physical join operators in SQL Server namely, Nested Loops Join, Merge Join, and Hash Match Join. Nested Loops are used to join smaller tables. Further, nested loop join uses during the cross join and table variables.
Merge Joins are used to join sorted tables. This means that Merge joins are utilized when join columns are indexed in both tables while Hash Match join uses a hash table to join equi joins.
It is important to understand the usages of the different physical join operations. In order to achieve better results, we can look at the options of modifying the indexes or adding new indexes. Further, we can rewrite queries to achieve better results by changing the physical operators.
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021