

Introduction
Most IT professionals started their studies or careers by learning programming languages like Basic, Cobol, C, Pascal, Java and so on. Those languages produce results using a sequence of operations or procedures. For this reason, this approach is called procedural programming.
In SQL Server, we can find an equivalent language called Transact SQL, also known as T-SQL. But SQL Server is a database engine and we can do a lot more than just tell him how to produce results: with data management instructions at our disposal like SELECT statement or Common Tabular Expressions feature, we can tell SQL Server what we want to get instead and let it deduct the « how ».
As an example, if we want to list customers who bought something last week, in T-SQL, we will write a SELECT query on a Customers table, join it to an Invoices table and filter on an InvoiceDate column. In regular programming language, we would have to write a program which does everything that is performed by SQL Server database engine plus what we want to get: open Invoices and Customers list files, read it one row at a time and create the results set then close it.
This means that operations in SQL Server are performed on a complete set of rows and returns a subset of the rows it manipulated.
As a SQL Server professional, we must be aware of the power of a database engine and get the best out of it, not simply see Transact SQL as another procedural language! Furthermore, if T-SQL is designed for set manipulation, we could expect performance improvement using this « set-based » approach.
This article is the first part of a series of three articles that will deal with set-based programming. In this article, we will focus on the simple “problem” of getting the minimum and maximum values of a column, so as its sum. We will first discuss about different T-SQL instructions and objects that we will use to actually implement solutions using both approaches. Then we will have a look at details of these implementations. While this “problem” can be easily solved by a complete T-SQL beginners, even not aware of set-based programming approach, it will help us to reveal some points of interest in building a deeper knowledge on set-based approach.
T-SQL objects and instructions
In this section, we will consider the instructions to be used to implement the example of this article. As explained above, this example is totally silly but it is there to pinpoint the power of SQL Server database engine, even for simple operations. By the way, this reflects what could be done applications that do not use a Database Engine.
Procedural objects and instructions in T-SQL
There are a few procedural objects and instructions that can be used by a developer to perform a given task.
Firstly, we have control-flow operators that we can find in regular programming languages: WHILE, BREAK, CONTINUE, IF…ELSE, TRY…CATCH…
Secondly, there are cursors. Cursors are especially useful for applications that need to process one row at a time. It can be seen as a double linked list.
Microsoft defines a T-SQL cursor as:
They are based on the DECLARE CURSOR syntax and are used mainly in Transact-SQL scripts, stored procedures, and triggers. Transact-SQL cursors are implemented on the server and are managed by Transact-SQL statements sent from the client to the server. They may also be contained in batches, stored procedures, or triggers.
Like INT, VARCHAR and other data types, Cursors are declared in T-SQL batches. SQL Server comes with associated instructions to manage it:
- OPEN to tell SQL Server to run the query and populate cursor with results set;
- CLOSE to tell SQL Server to release resources used by cursor;
- FETCH to tell SQL Server to retrieve a specific row from cursor. When we use this function, we can get the outcome of FETCH instruction in @@FETCH_STATUS variable. If it’s set to 0, this means that the instruction succeeded.
Set-based instructions in T-SQL
In T-SQL, for this set-based approach, we will use so called « aggregate functions ». These functions perform a calculation on a set of values and produce a single value.
Functions we will use in following example (sum, max, min) are good candidates as aggregate functions. Actually, they are implemented in SQL Server and optimized so that we could get the best out of SQL Server database engine.
If you were to find, for instance, the total amount of time they spent on SQLShack (with the assumption that there is a table populated to keep track of user activity), you would need to use the GROUP BY instruction to tell SQL Server that you want the return of SUM aggregate function per user.
Summary
As a summary, you will find below a table with the instructions and objects at our disposal to write procedural or set-based code. This table will be reviewed at the end of following articles.
| Procedural Approach | Set-Based Approach |
|
SELECT and other DML operations,
WHILE, BREAK, CONTINUE, IF…ELSE, TRY…CATCH… Cursors (OPEN, FETCH, CLOSE) DECLARE |
SELECT and other DML operations,
Aggregate functions (MIN, MAX, AVG, SUM…) |
Example implementations
In this section, we will use the instructions and objects defined above to implement a solution to the problem of getting values for min, max and sum of a given column.
We will fist create a table and populate it with some data. Then review an example of implementation for a procedural approach and its noticeable aspects and we will do the same for set-based approach implementation. Finally, compare results and conclude.
Example setup
Let’s say we have the following table:
|
1 2 3 4 5 |
CREATE TABLE #Example1 ( ValueInt INT ) ; |
and populate it with random data
|
1 2 3 4 5 6 |
INSERT INTO #Example1 SELECT ABS(CHECKSUM(NewId())) % 20 GO 10 |
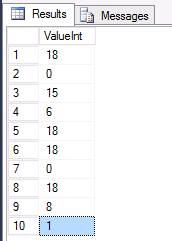
If we take a look at its content, we will get something like this:
A procedural implementation
In regular languages, we would get the data set and loop on values to set results into variables then display these results. This is what is done in following T-SQL statement.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
-- To display some timing info: SELECT CONVERT(VARCHAR(32),GETDATE(),121) as StartTimeStamp ; DECLARE intValues CURSOR LOCAL FOR SELECT * FROM #Example1 ; DECLARE @TotalVals INT = 0; DECLARE @MinValue INT; DECLARE @MaxVal INT; DECLARE @CurVal INT; OPEN intValues; -- init FETCH NEXT FROM intValues INTO @CurVal; SET @MinValue = @CurVal; SET @MaxVal = @CurVal; WHILE(@@FETCH_STATUS = 0) BEGIN SET @TotalVals = @TotalVals + @CurVal; SET @MinValue = CASE WHEN @MinValue > @CurVal THEN @CurVal ELSE @MinValue END; SET @MaxVal = CASE WHEN @MaxVal < @CurVal THEN @CurVal ELSE @MaxVal END; -- Carry on the loop FETCH NEXT FROM intValues INTO @CurVal; END; CLOSE intValues; -- Display results SELECT @TotalVals as SumOfValues, @MinValue as MinValue, @MaxVal as MaxValue ; -- To display some timing info: SELECT CONVERT(VARCHAR(32),GETDATE(),121) as EndTimeStamp ; |
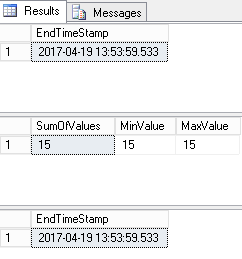
The results should look like as follows.
We can see that this code took 3 ms to run and provide its results. If we want to have a look on timed and IO statistics, we might run the following statement:
|
1 2 3 4 |
set statistics io on set statistics time on |
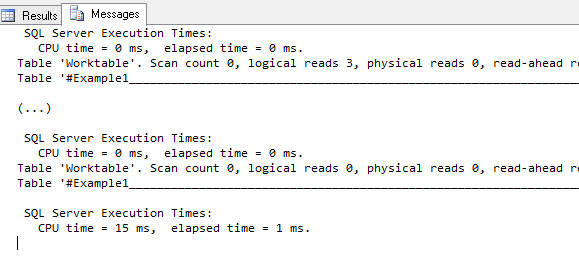
We won’t list all the output when running again the code that implements our example, but we will focus on some points that are taken out of this output. As you will see when you execute the code, there is a lot of stuff that is performed by SQL Server.
First of all, SQL Server had to use CPU time to parse and compile this code.

Then, we see that, as we use a cursor, SQL Server creates a Worktable that will be scanned during execution.
Alternately, we could have used another implementation that consists in replacing cursor usages by the following query:
|
1 2 3 4 5 6 |
SELECT TOP 1 @CurVal = ValueInt FROM #Example1 WHERE ValueInt > @ CurVal |
But this won’t produce the good value for sum if table #Example1 contains multiple occurrences of a value.
Set-based implementation
Now, let’s do it using a set-based approach and aggregate functions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT CONVERT(VARCHAR(32),GETDATE(),121) as StartTimeStamp ; select SUM(ValueInt) as SumOfValues, MIN(ValueInt) as MinValue, MAX(ValueInt) as MaxValue FROM #Example1 ; SELECT CONVERT(VARCHAR(32),GETDATE(),121) as EndTimeStamp ; |
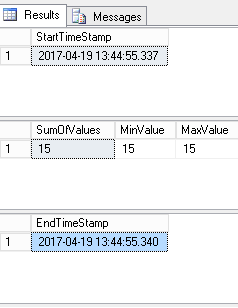
This results to something like following screen capture:
Results comparison
And let’s compare time and IO statistics:

When comparing screenshots, we see that the actual execution time is 3 times higher in the procedural version than in set-based approach. This can be explained when we take a look at the number of operations performed by SQL Server in procedural version to produce the exact same results as in set-based version.
To get a better overview of performance, we could generate a bigger table than with just ten rows and compare timing and resources consumption for both implementations provided above.
Cleanups
This ends the example and following statement will clean the temporary table we created:
|
1 2 3 |
DROP TABLE #Example1 |
Conclusion
This article provides us further reasons to get interested in set-based programming:
- It’s concise and easier to read;
- It avoids unnecessary resource consumption, so looks promising in regards to performance. We can see in this simple example that procedural version leads to worktable creation and a lot more I/O and CPU operations than in set-based version.
Now, let’s dive into real set based programming techniques and build solutions that can be very helpful!
Further readings
As explained in the introduction, this article is part of a series of article. Next article will consider the concept of “set” and provide an overview of the implementation of this concept in T-SQL.
Next articles in this series:
- From mathematics to SQL Server, a fast introduction to set theory
- T-SQL as an asset to set-based programming approach
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018