

In this article, we will learn what is an Azure Lake Database conceptually, and the different components of this solution, followed by its practical implementation in upcoming articles.
Introduction
In the journey of data when the age of computers began, data storage and processing had limits of processing power and storage capacity. Innovation in these spaces paved the way to store increasing amounts of data with an increasing amount of processing speeds as well as an increasing amount of storage capacities. An increase in scale gave rise to different ways of modeling data structures to suit the nature of hosting, processing, and consumption. It started with simple data structures, followed by popular data models or suites like relational and transactional databases (OLTP), data warehouse, master data management systems, analytical databases (OLTP), data marts, operational data stores, no SQL databases, data lakes, and data lake houses. The latest addition in this space is cloud data-lake based databases. The Azure version of such databases is known as Azure Lake Database.
What is an Azure Synapse Lake Database?
A large volume of transactions gave birth to database management systems, typically relational databases. When an eco-system of such databases grew, there was a need to correlate data from these OLTP databases. This paved way for the data warehouse paradigm where data from every corner of the business was gathered in a denormalized fashion. Data lacked consistency across transactional database systems working in silos. This paved way for master data management system to bring standardized data in data warehouses. Data warehouses had too much data for consumers to consume as-is. The volume was too huge to process ad-hoc data analysis requests by power users. This gave birth to analytical data stores (OLAP), which pre-aggregated data from data warehouses and allowed power users to use this data typically for their dashboards and Management Information Systems (MIS). This is the traditional journey of data management.
With the innovation in data storage and the need to process the internet scale of data, frameworks like Hadoop were born and gave way to the paradigm of Data Lake. With the advent of the cloud, the concept of isolation of compute and storage was emphasized to bring robustness and decoupling in the data architecture. Data Lake encouraged the concept of dumping data in an as-is format and using compute power as required on the desired datasets unlike in databases where data and compute are tightly coupled. This facilitated bringing all types of databases relational and no-SQL databases on a common ground logically known as a data lake. Data lake became an easy ground for data hoarding or data dumping. Data warehouses had been in existence for decades, and when data lake is used to dump raw data in the form of files from all sorts of databases, there was a need for a solution that allowed data warehouse and data lake to co-exist to use to best of both worlds. Data warehouses allow easy and managed correlation of data while data lake brings the de-coupling between compute and storage. This concept started taking shape in the form of Data Lake House in the past year. Apache Hudi and Databricks Delta Lake are two of the most popular formats using which many analytical databases have positioned Lake House capabilities. Azure seems to have launched a similar capability in a more intuitive way. Azure’s data warehouse offering is Azure Synapse Analytics which supports three different types of compute tiers in the form of serverless pool, dedicated SQL pool and Apache spark pool. In my opinion, Lake Database is a new capability in Azure Synapse Analytics that can support building a lake house on Azure Platform using Azure Data Lake as the underlying storage layer and Azure Synapse Analytics as the computer layer.
Components of Azure Lake Database in Azure Synapse Analytics
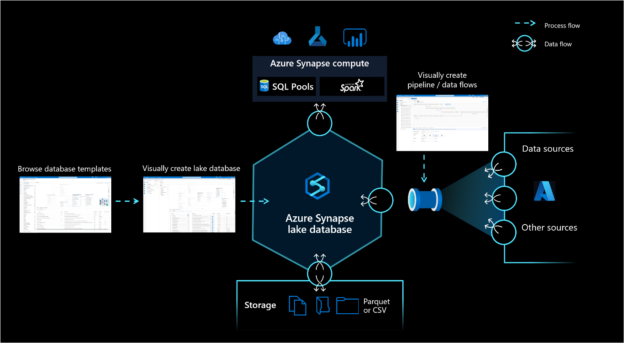
Shown below is the official diagram of the Azure Lake Database conceptual view. The core components that make up this overall solution with Azure Lake Database at the center of it are Azure Synapse compute pools, Database Templates Gallery to visually create data lake tables, Azure Data lake storage as the underlying storage mechanism, Azure data pipelines (typically created using Azure Data Factory framework) to ingest data in the Azure Synapse Lake Database from various supported data sources.
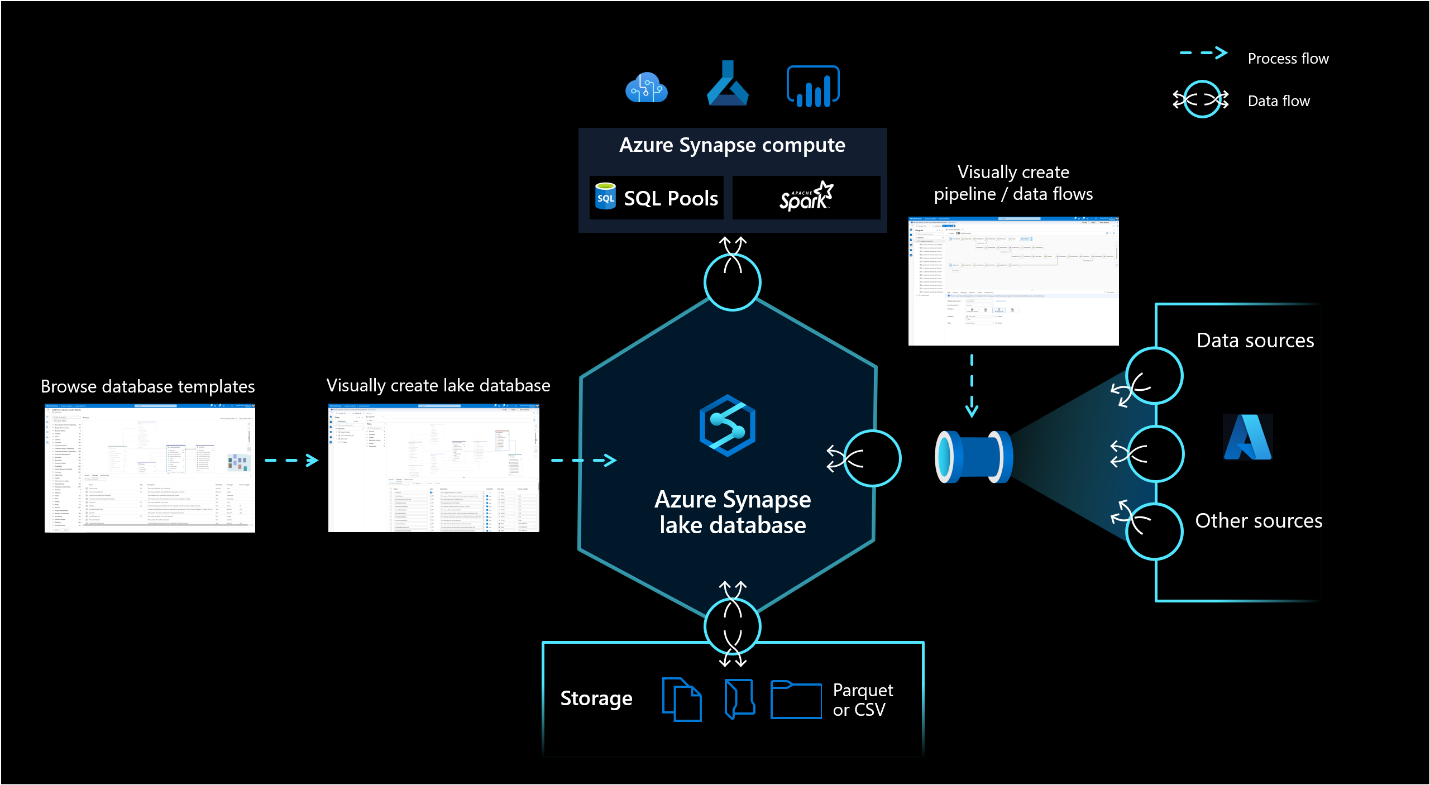
Let’s understand these components that make up Data Lakehouse on Azure Synapse Analytics one by one.
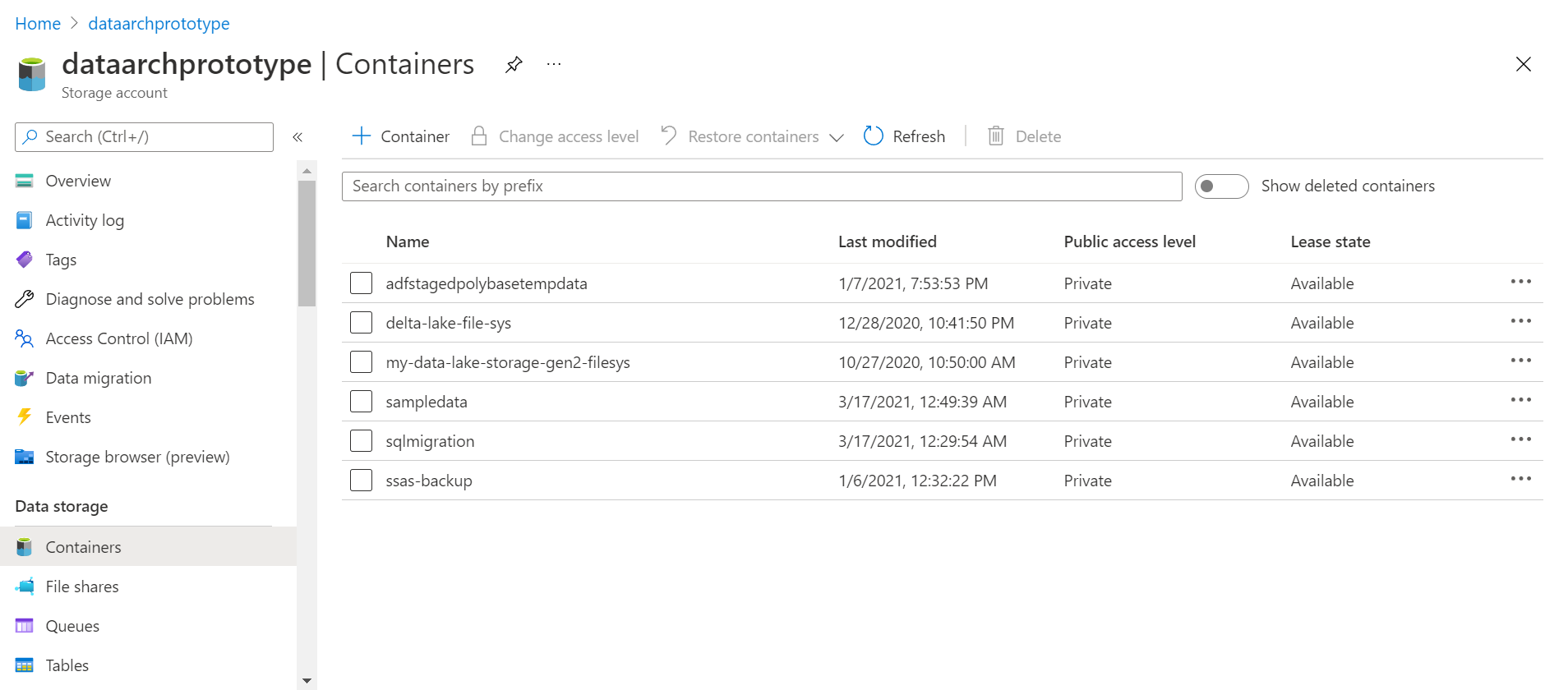
Azure Data Lake Storage – Popularly known as ADLS, this service supports storing of data in the form of blob storage which can be organized hierarchically. It supports many data management features like replication across availability zones for high availability and disaster recovery, data life cycle management, data version, data sharing, data security and various other features. This service forms the basis of a data lake where it can be used as the storage layer for a variety of data processing and data consumption services. A screenshot of the ADLS dashboard is shown below.
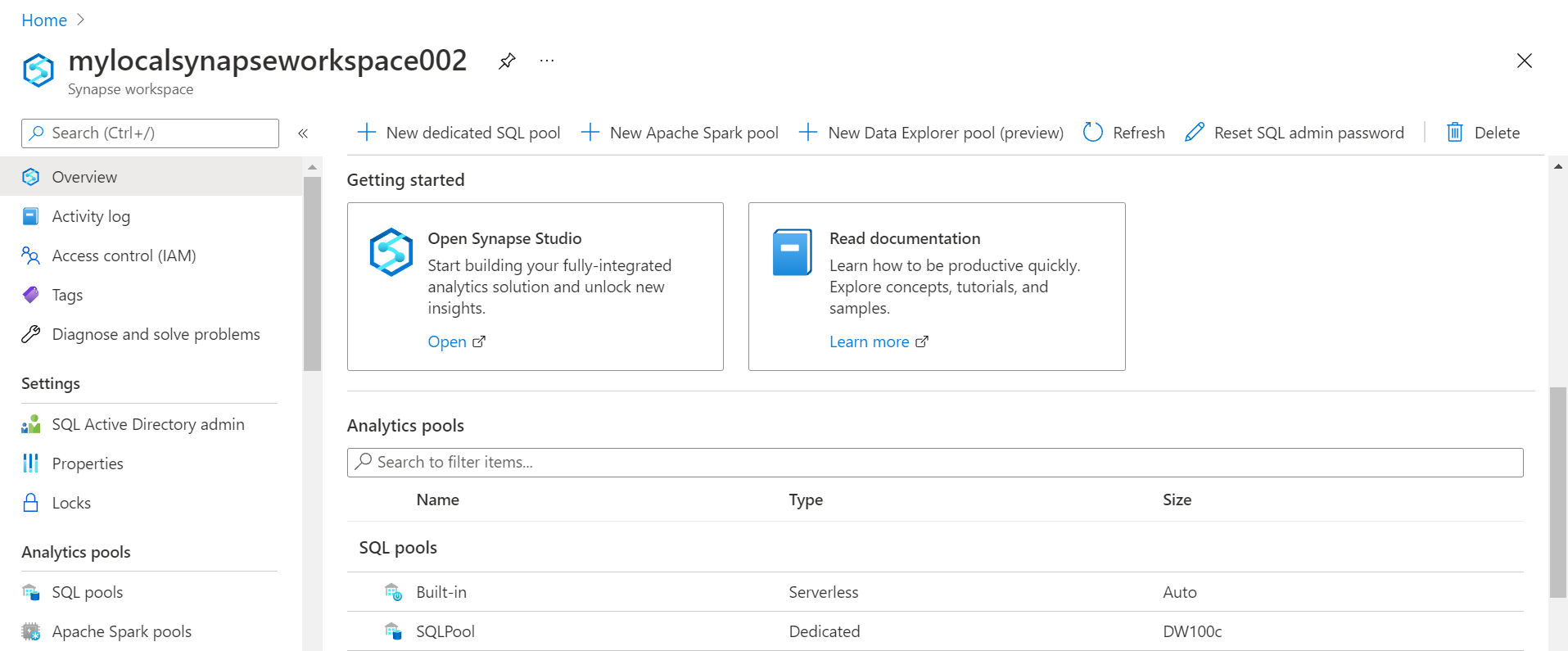
Azure Synapse Analytics – Synapse is Azure’s data warehouse offering on the Azure cloud. Using the Azure Synapse Analytics service one can create different compute tiers that use different types of storage. Synapse serverless pool uses the Azure Data Lake Storage, while the dedicated SQL pool and Apache Spark pool uses their individual storage layers and supports different level and types of data processing at different pricing tiers. Synapse forms the compute tier of a Data Lake House which is a fusion of Data Lake and Data Warehouse, where Synapse brings the warehouse-related capabilities. A snapshot of the Azure Synapse Analytics Dashboard is shown below.
Azure Synapse Lake Database – This is the new data structure that the Azure Synapse service has launched in preview mode (as of the draft of this article). This structure is supported on Azure Synapse Serverless SQL pool and Spark pool. This is the key component to create a Data Lake House on Azure Synapse, with the alternative being delta lake kind of data structures. Lake Database is more intuitive and has a metadata element linked to it with a visual designer to model metadata tables underneath it. This structure can be activated from Azure Synapse Analytics Studio as shown below.
Data pipelines and Data Flows – Using the Azure Data Factory framework (which is Azure’s ETL offering) on Azure Synapse Analytics, one can create data pipelines and data flows that can use Lake Database as the metadata container or frame, into which data can be ingested. The same can be used typically by a data consumer as well to consume data like one would consume data from any other normal database or table from a relational database. A screenshot of data pipelines and data flows on Azure Synapse Analytics is shown below.
Lake Database is a new way of defining data structures on data that would be hosted on Data Lake (ADLS) and data processed with Data Warehouse (Synapse) to ultimately cater a Data Lake House solution for the desired use-cases. In the upcoming articles, we will learn how to work with the different components of a Lake Database and explore the features supported by it.
Conclusion
In this article, we learned about the history of database management systems in a chronological order that led to the modern data lake house paradigm. We then conceptually analyzed the different components of the Azure Synapse Lake Database and then explored the function of each component of the Lake Database architecture diagram from a high level.


She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023