
After discussing a wide range of aspects in Azure Machine Learning, now it is time to move into a new area, Text Analytics and we have dedicated this article to Language Detection in Azure Machine Learning for Text Analytics.
Before this article, we have discussed multiple machine learning techniques such as Regression analysis, Classification Analysis, Clustering, Recommender Systems and Anomaly detection of Time Series in Azure Machine Learning. Further, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation and Hyper Tune parameters in this article series to date and now it’s time to focus on a different aspect in Machine Learning which is text analytics.
Text Analytics
In modern days, text analytics has become an important technique and there are many problems related to Text Analytics such as Content-Based recommendation, Text Classification. As you can imagine, text analytics is challenging in many aspects as there are various techniques to be done depending on the language that you are focusing on. Some of those techniques are tokenization, stemming, and lemmatization. Azure machine learning supports different options for text analytics as shown in the below figure.

Before we do all these pre-processing and other tasks, it is essential to perform Language Detection in Azure Machine Learning for Text Analytics.
Language Detection in Azure Machine Learning
There are more than 7,000 languages that are being used in the world today. Due to this fact, it is guaranteed that user-generated data will have multiple languages. Every language has unique features. Therefore, to perform preprocessing tasks, we need to identify the language. Since text analytics has a non-schematic structure. Therefore, users will enter different types of text including text in multiple languages. Therefore, language detection for Text Analytics is an important process before we start any other pre-processing techniques.
Let us look at a data sample that consists of multiple languages such as English, Spanish, French, Sinhala, Japanese, Arabic, etc.

Let us import this data to the Azure Machine learning to detect languages as we did in the first article of the series. The CSV file is updated to the new data set in Azure Machine learning with relevant comments. Let us drag and drop the uploaded data set and add Select Columns in Dataset control in order to remove unnecessary columns for the data set.

Let us look at the data output from the Select Columns in DataSet control as shown below.

Now the task is to identify the language from Detect Languages control. In this control, you need to select the text that you are looking for Language Detection in Azure Machine Learning.

You can select only one column for language detection in Azure Machine Learning. If you are looking forward to detecting language in multiple columns, you need to include multiple Detect Languages Control.

Detect Languages control has very simple configurations as shown in the above screenshot. The Upper bound on several languages to detect option decides how many languages to detect. By default, this option is the one that means every text is assigned to the only language when there are multiple languages in one text.
Let us look at the output of the Detect Language control as shown below.

Language Detection in Azure Machine learning has identified each text language with the score. If the score is 100% for English that means the text is 100% English. Now you can filter only the English text by using the Split Data Control as shown below.

After the data split is completed, the first port will give English data while the other port will provide non-English data. The first port will now provide you with only the text in English as shown below.

This is the complete Experiment with Language Detection.

With this process, now you are ready to process the text in English.
Extract Key Phrases from Text
One of the main techniques in text analytics is Extract Key phrases in Text. Identification of key phrases may lead to sentiment analysis and Opinion mining etc. After the language detection in Azure Machine Learning is done, Extract Key Phrases from Text control can be used to extract the keywords from texts.

In the Extract Key Phrases from Text, you need to specify the language. At the moment this control supports languages such as English, Spanish, French, Dutch, German and Italian are configurable.

There is an additional option in the language drop-down named, Column Contains Language. In this option, you can extract key phrases from multiple languages, but you need to provide the language information in a different column as shown below.

In the above configuration, the Text Language column is chosen as the language column and the text column is used to extract key phrases. Finally, the output is shown below.

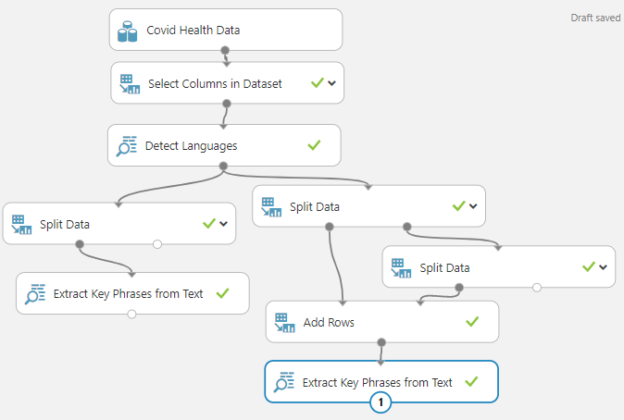
You can see that the last row is Italian text and in which key phrases are extracted like English texts. Finally, the entire experiment will look like the following.

In the above experiment, two extract Key phrases from the text are used after the Language Detection in Azure Machine Learning. One of them is to extract key phrases for the English language while the other Extract key phrases from Text control is to extract key phases for English and Italian. This option does not work for all the languages and if you pass a language that does not compatible, this control will fail.
Please note that Add Rows control is used to merge English and Italian data.
Preprocess Text
Every language provides us with different challenges. Therefore, before we start analysis there are preprocess tasks that need to be performed on the dataset. Let us look at what types of process task that can be applied after the Language Detection in Azure Machine Learning is performed.
First of all, we do not need words like, “a, and, the” to be in the data set as they won’t add any semantic meaning to the text. These are called stop words and we can maintain a list of stop words by using the Enter Data Manually control and configure as shown below.

Next, we need to configure Preprocess text control as shown in the below figure.

There are a few configurations that need to be done in order to preprocess text as shown in the below figure.

As you know. Numbers, special characters URLs, email addresses, stop words can be considered as noise when it comes to text analytics. So those noises are removed from this control.
Lemmatization is standardizing the text. For example, whether it is “ran, run or running”, though there are grammatical differences, it has the same semantic meaning. Therefore, by Lemmatization, it will convert to one standard format.
Some text as acronyms such as Covid, AWS, MS, etc. These words have to be converted to the same text so that proper analysis can be carried out. After the Preprocessing is completed, you can perform another Extract Key phrase from the text to retrieve many improved keywords.
You can access the entire Experiment including the Language Detection in Azure Machine Learning from https://gallery.azure.ai/Experiment/Text-Analytics-50
Conclusion
This article started another area in Azure Machine Learning that is Text Analytics. We focused mainly on how to perform Language Detection in Azure Machine Learning. In that, we experienced that we can detect the language as well as the score for language detection. Further, we introduced two additional Text Analytic-related controls such as Extract Key Phrases from Text and Preprocess Text. Preprocess Text is a kind of data cleaning in text analytics in which noisy words such as email addresses, URLs, etc. are removed. Lemmatizations are another important process in the Preprocess text. The Extract Key Phrases from text control allows extracting keywords so that we can determine the sentiment and opinion of the users.
References
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021