

The SELECT statement is probably the most important SQL command. It’s used to return results from our database(s) and no matter how easy that could sound, it could be really very complex. In this article, we’ll give an intro to the SELECT statement and we’ll cover more complex stuff in the upcoming articles.
Motivation
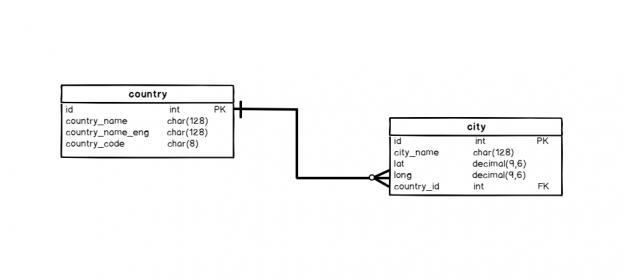
In this series, we had 4 articles so far and we’ve created a simple database, populated it with some data and explained what are primary and foreign keys. These are prerequisites needed to start “playing” with our data:

In real-life situations, you’ll probably won’t insert all the data into the database. Data shall be either inserted manually by multiple users of your application/system or by some automated process(es). In these cases, you’ll either:
- Analyze data, most probably by using SELECT statements
- Track system performance
- Make changes in the data model to support new features
Well, I guess you get it, you’ll keep the system running and analyze what’s stored in there. The analytics part is probably cooler because you’ll be able to create reports and see what happened before, and if you have enough data and knowledge of statistics, you’ll be able to predict the future (as much as this is possible). I can hardly imagine doing any analytics when working with databases without writing a SELECT statement.
SELECT statement – Syntax
All SQL commands are important and needed, especially these 4 most commonly used – SELECT, INSERT, UPDATE, DELETE. Therefore, saying that the SELECT statement is the most important one is not true. It’s as important as others are but it’s definitely most commonly used. Being able to write a SELECT to get exactly what you wanted is a very desirable knowledge these days. Besides writing a statement that returns the correct result, you should almost (if you write a one-time query and it takes 2 seconds instead of 0.1 seconds, you can live with that) always make sure that the query is written in an optimal way.
Let’s take a look at the Transact-SQL SELECT statement syntax:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Syntax for SQL Server and Azure SQL Database <SELECT statement> ::= [ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ] <query_expression> [ ORDER BY { order_by_expression | column_position [ ASC | DESC ] } [ ,...n ] ] [ <FOR Clause>] [ OPTION ( <query_hint> [ ,...n ] ) ] <query_expression> ::= { <query_specification> | ( <query_expression> ) } [ { UNION [ ALL ] | EXCEPT | INTERSECT } <query_specification> | ( <query_expression> ) [...n ] ] <query_specification> ::= SELECT [ ALL | DISTINCT ] [TOP ( expression ) [PERCENT] [ WITH TIES ] ] < select_list > [ INTO new_table ] [ FROM { <table_source> } [ ,...n ] ] [ WHERE <search_condition> ] [ <GROUP BY> ] [ HAVING < search_condition > ] |
I’ll simplify this syntax to focus on the things I want to explain in this article:
|
1 2 3 4 5 6 7 8 |
SELECT [TOP X] attributes & values FROM first_table INNER / LEFT / RIGHT JOIN second_table ON condition(s) ... other joins if needed WHERE condition(s) GROUP BY set of attributes HAVING condition(s) for group by ORDER BY list attributes and order; |
SELECT statement – Very simple examples
Only the line with the SELECT keyword is required in the select statement. After this reserved keyword, we’ll list everything we want to see in our result. These could be values, attributes from tables, results of (mathematical or logical) operations, etc. Lets’ take a look at a few simple examples:
|
1 2 3 4 5 |
SELECT 1; SELECT 1+2; SELECT 1+2 AS result; SELECT 1+2 AS first_result, 2*3 AS second_result; SELECT (CASE WHEN 1+2 > 2*3 THEN 'greater' ELSE 'smaller' END) AS comparison; |
The result displayed in the SQL Server Management Studio after executing them is the following:

Let’s quickly explain what happened here.
First of all, in all these 5 queries, we haven’t used a single table from our database. In real-life situations, this could hardly prove to be usable in any case, but it will serve its’ purpose here.
The things we should remember from here are:
- The SELECT keyword is the only one required in the SELECT statement
- You can perform mathematical operations in SQL (SELECT 1+2;). If your column is the result of a calculation it won’t have any name in the result, so you’ll have “(No column name)”
- If you want to give a (different) name to the column in the result you can use AS and alias name (SELECT 1+2 AS result;)
- You can have more than 1 column in your result (SELECT 1+2 AS first_result, 2*3 AS second_result;), and usually that shall be the case
- You can even compare values or results of a calculation in the SELECT part of the statement (SELECT (CASE WHEN 1+2 > 2*3 THEN ‘greater’ ELSE ‘smaller’ END) AS comparison;)
The chance that you’ll really need to write a query like any of these 5 examples while performing any serious tasks is next to nothing. Still, all of the previous bullets are correct for complex queries too, and I guess it was easier to explain them on really simple examples.
SELECT statement – Using the single table
Now we’re ready for the next step and that is to use data from our database. The data model is the same as the one used in the previous article. We’ll start with two simple SELECTs:
|
1 2 3 4 5 |
SELECT * FROM country; SELECT * FROM city; |
The result is given in the picture below:

Both statements do the same thing, but for different tables. The * after SELECT means that we’ll select all columns from that table.
Note: It’s nice (almost the rule) to put each keyword (SELECT, FROM, JOIN, WHERE…) in the new line.
In case we need only some columns from the table, we should list all the columns we need after the SELECT keyword:
|
1 2 |
SELECT id, country_name FROM country; |

As expected, we have only 2 columns in the result. While it’s common sense to return only the columns you’re interested in, later it’s even more than that. If your table has a large number of columns or you join a few tables, listing only the columns you need is much more than desirable.
Note: You should always list only the columns you need in the result. A chance that you’ll use * and return all columns is very low. You’ll probably do that only when you want to take a look at the content of that table for the first time.
The next thing we want to do is to not only select columns, but also select rows we want in the result. We’ll do that by using the WHERE keyword. Let’s take a look at 3 examples:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT id, country_name_eng FROM country WHERE id = 2; SELECT id, country_name_eng FROM country WHERE id > 2; SELECT id, country_name_eng FROM country WHERE id = 6; |
The result is given in the picture below:

In all three SELECT statements, we’ve used the id column in the WHERE part of the statement.
This column is also the primary key of the table. Therefore, the first select can find only 1 record with id = 2. For the same reason, the third statement couldn’t find any record – there is no record with id = 6.
The second statement returned all records with id > 2, so our result had multiple rows.
SELECT Statement – Using multiple tables
The last thing we’ll do in this article is to select data from both tables in our model. Before we do that, let’s remind ourselves that these tables are related via foreign key (city.county_id = country.id). We’ll need to use this condition every time we use both these tables:

If we don’t use condition, the query will join all records from the first table with all records from the second table. This generates not only the large output but also relates values that actually are not related (only some of them truly match). For example, Berlin is obviously not in the USA, but a query like this would say it so. Therefore, we need to add join conditions to get the correct result.
Note: If you join two (or more) tables without a join condition, you’ll get a combination of all rows with each other (Cartesian product).
Now, we’ll join tables using the join condition and also add one more condition in the WHERE part of the query:
|
1 2 3 4 |
SELECT city.id AS city_id, city.city_name, country.id AS country_id, country.country_name, country.country_name_eng, country.country_code FROM city INNER JOIN country ON city.country_id = country.id WHERE country.id IN (1,4,5); |
The result is given in the picture below:

I would like to point out a few things here:
- We’ve joined our two tables using the INNER JOIN and foreign key as condition (INNER JOIN country ON city.country_id = country.id)
- We have a condition in the WHERE part of the query, telling us to return only rows where the id of the country is 1, 4 or 5. Please notice how the IN keyword is being used – similar to set theory
- We’ve listed only attributes we want to display in the result
- Two times, we’ve used alias names (city.id AS city_id & country.id AS country_id). Since primary key columns in both tables are named id, we should name them differently in the result returned. While we know which columns the query used, for someone who hasn’t written this query or can’t see its’ structure (for any reason), this is very important
Conclusion
In today’s article, we’ve explained basics related to the SELECT statement. In the next article, we’ll write some more complex statements and use other keywords like GROUP BY, HAVING and ORDER BY. So, stay tuned!
Table of contents
See more
Seamlessly integrate a powerful, SQL formatter into SSMS and/or Visual Studio with ApexSQL Refactor. ApexSQL Refactor is a SQL query formatter but it can also obfuscate SQL, refactor objects, safely rename objects and more – with nearly 200 customizable options


His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020