

Introduction
For a recent Tsql development project involving text document records, the customer wanted a product that would show the latest and most recent earlier version of specific document text stored in a SQL Server 2014 database. One result set row had to hold all relevant information for each document: both document versions as described above, and relevant metadata. This essentially required fine-grained row pivots. This article will describe the engineering behind the solution, and compare that solution with the SQL Server PIVOT operator.
The Sample Database
This article will use a sample database named DOCUMENT_VERSIONING, built-in SQL Server 2014 Standard Edition on a Windows 10 PC. The database has one table named DOCUMENTS, as shown here:
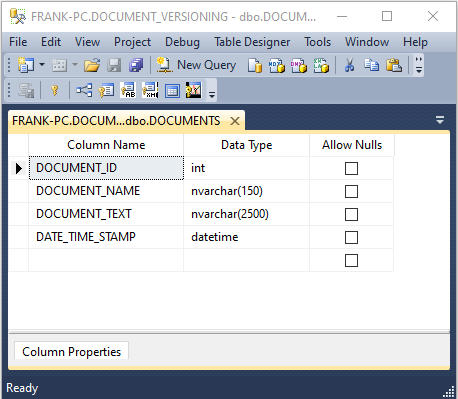
Otherwise, the database has no user-defined functions or stored procedures, triggers, etc. To build the DOCUMENT_VERSIONING database and its data with the script shown next, first create the directory C:\DOCUMENT_VERSIONING. This directory will host the component .LDF and .MDF database files that the database creation script will build. To build the database itself, connect to the master database in Management Studio, and run this Tsql script in a SQL Server Management Studio query analyzer window:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
USE [master] GO IF EXISTS (SELECT name FROM sys.databases WHERE name = 'DOCUMENT_VERSIONING') -- DROP ANY EXISTING CONNECTIONS TO DOCUMENT_VERSIONING ALTER DATABASE DOCUMENT_VERSIONING SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE DOCUMENT_VERSIONING GO /****** Object: Database [DOCUMENT_VERSIONING] Script Date: 10/19/2021 5:32:15 PM ******/ CREATE DATABASE [DOCUMENT_VERSIONING] CONTAINMENT = NONE ON PRIMARY ( NAME = N'DOCUMENT_VERSIONING', FILENAME = N'C:\DOCUMENT_VERSIONING\DOCUMENT_VERSIONING.mdf' , SIZE = 4096KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'DOCUMENT_VERSIONING_log', FILENAME = N'C:\DOCUMENT_VERSIONING\DOCUMENT_VERSIONING_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO USE DOCUMENT_VERSIONING; CREATE TABLE [dbo].[DOCUMENTS]( [DOCUMENT_ID] [int] NOT NULL, [DOCUMENT_NAME] [nvarchar](150) NOT NULL, [DOCUMENT_TEXT] [nvarchar](2500) NOT NULL, [DATE_TIME_STAMP] [datetime] NOT NULL ) ON [PRIMARY] GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (1, N'DOCUMENT_1', N'OLD TEXT', CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (4, N'DOCUMENT_4', N'NEW TEXT', CAST(N'2017-02-01 11:28:52.320' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (4, N'DOCUMENT_4', N'OLD TEXT', CAST(N'2017-02-01 02:28:52.320' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (1, N'DOCUMENT_1', N'OLD TEXT', CAST(N'2019-03-27 00:18:20.000' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (1, N'DOCUMENT_1', N'NEW TEXT', CAST(N'2020-04-27 00:18:23.090' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (1, N'DOCUMENT_1', N'TEXT', CAST(N'2014-04-27 00:08:08.190' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (2, N'DOCUMENT_2', N'NEW TEXT', CAST(N'2008-04-27 03:12:02.450' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (3, N'DOCUMENT_3', N'NEW TEXT', CAST(N'2016-12-01 17:22:59.123' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (3, N'DOCUMENT_3', N'UNENCRYPTED TEXT', CAST(N'2000-04-01 00:22:59.123' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (3, N'DOCUMENT_3', N'RE-ENCRYPTED TEXT', CAST(N'2000-04-01 00:22:59.123' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (3, N'DOCUMENT_3', N'OLD TEXT', CAST(N'2012-10-17 14:28:52.320' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (5, N'DOCUMENT_5', N'NEW TEXT', CAST(N'2018-07-18 12:09:19.320' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (5, N'DOCUMENT_5', N'OLD TEXT', CAST(N'2018-07-18 12:09:19.320' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (5, N'DOCUMENT_5', N'NEW TEST TEXT', CAST(N'2018-07-12 17:22:29.557' AS DateTime)) GO INSERT [dbo].[DOCUMENTS] ([DOCUMENT_ID], [DOCUMENT_NAME], [DOCUMENT_TEXT], [DATE_TIME_STAMP]) VALUES (5, N'DOCUMENT_5', N'EDGE TEST TEXT', CAST(N'2018-02-02 11:39:45.220' AS DateTime)) GO USE [master] GO |
This script will run successfully, but it could return this error message when run for the first time:
Msg 3701, Level 11, State 1, Line 9
Cannot drop the database ‘DOCUMENT_VERSIONING’, because it does not exist or you do not have permission.
Ignore that error.
The Table Data
This screenshot shows the sample data we’ll use:
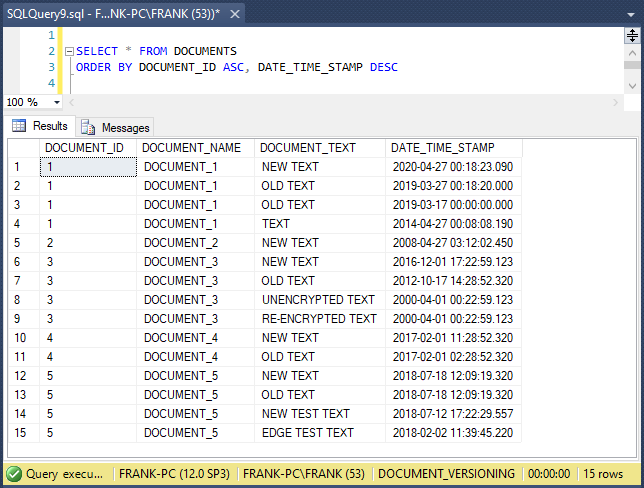
Except for DOCUMENT_ID = 2, each document has multiple versions. This query sorted the documents by DOCUMENT_ID ascending, and then DATE_TIME_STAMP descending.
The Solution
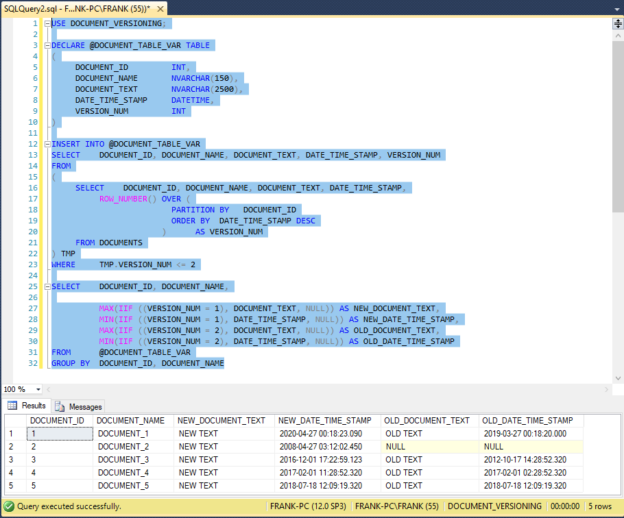
We’ll solve the problem with this code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
USE DOCUMENT_VERSIONING; DECLARE @DOCUMENT_TABLE_VAR TABLE ( DOCUMENT_ID INT, DOCUMENT_NAME NVARCHAR(150), DOCUMENT_TEXT NVARCHAR(2500), DATE_TIME_STAMP DATETIME, VERSION_NUM INT ) INSERT INTO @DOCUMENT_TABLE_VAR SELECT DOCUMENT_ID, DOCUMENT_NAME, DOCUMENT_TEXT, DATE_TIME_STAMP, VERSION_NUM FROM ( SELECT DOCUMENT_ID, DOCUMENT_NAME, DOCUMENT_TEXT, DATE_TIME_STAMP, ROW_NUMBER() OVER ( PARTITION BY DOCUMENT_ID ORDER BY DATE_TIME_STAMP DESC ) AS VERSION_NUM FROM DOCUMENTS ) TMP WHERE TMP.VERSION_NUM <= 2 SELECT DOCUMENT_ID, DOCUMENT_NAME, MAX(IIF ((VERSION_NUM = 1), DOCUMENT_TEXT, NULL)) AS NEW_DOCUMENT_TEXT, MIN(IIF ((VERSION_NUM = 1), DATE_TIME_STAMP, NULL)) AS NEW_DATE_TIME_STAMP, MAX(IIF ((VERSION_NUM = 2), DOCUMENT_TEXT, NULL)) AS OLD_DOCUMENT_TEXT, MIN(IIF ((VERSION_NUM = 2), DATE_TIME_STAMP, NULL)) AS OLD_DATE_TIME_STAMP FROM @DOCUMENT_TABLE_VAR GROUP BY DOCUMENT_ID, DOCUMENT_NAME |
This screenshot shows the code in a SQL Server query analyzer window:
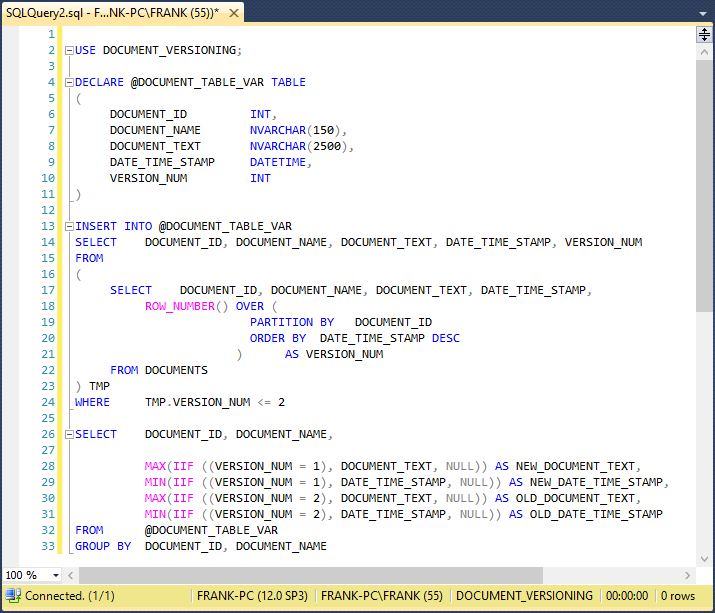
We’ll examine the code line by line.
The Line 2 USE statement points the query analyzer window to the DOCUMENT_VERSIONING database hosting the DOCUMENTS table. The code will use the table variable @DOCUMENT_TABLE_VAR, declared between lines 4 through 11, as a “scratchpad” for its operations. The Tsql code will generate and store the document version numbers in the VERSION_NUM column, defined in line 10. For the rows “owned” by each separate DOCUMENT_ID, the document version numbers will map to those rows, ordered by DATE_TIME_STAMP descending. The newest row for a document will have a VERSION_NUM value of 1. The next newest row will have a VERSION_NUM value of 2, etc.
The INSERT statement from lines 13 to 24 inserts the DOCUMENTS table rows into the @DOCUMENT_TABLE_VAR table variable. Within the statement, the SELECT statement between lines 17 and 22 returns all columns from the DOCUMENTS table. In addition, it builds values for the VERSION_NUM column. The ROW_NUMBER statement between lines 18 and 21 builds the values in the table variable VERSION_NUMBER column. In line 19, the Tsql PARTITION BY clause builds partitions, or “row windows”, in the data pulled from the source DOCUMENTS table. This line defines a partition as all rows with the same DOCUMENT_ID column value. In those partitions, the line 20 ORDER BY clause sorts the rows by DATE_TIME_STAMP descending. This will place the newest version row of each document at the top of each partition, the next newest version row just below, etc. Line 21 names the ROW_NUMBER values column as VERSION_NUMBER. Line 22 specifies the DOCUMENTS table as the data source. This screenshot shows the result set of this SELECT query:
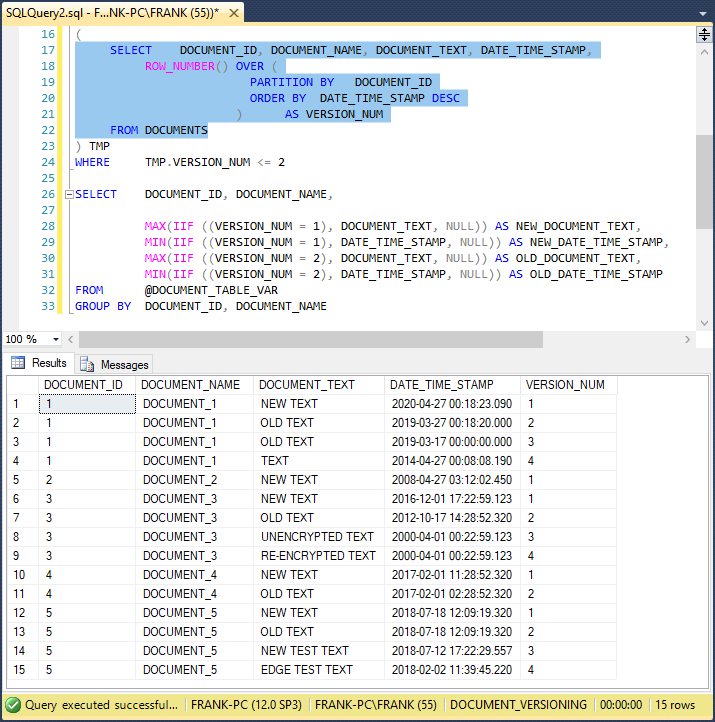
Note that it matches the original DOCUMENTS table data, with an additional VERSION_NUM column. The result set shown here sorted the version rows by DATE_TIME_STAMP descending in each row window, and the VERSION_NUM column has the expected values. Back in the code, line 23 essentially wraps the query from lines 17 to 22 in a table alias named “TMP.” Line 24 filters this query, to exclude rows with VERSION_NUM values that exceed 3. This approach will keep only the rows with VERSION_NUM values of 1 (the newest versions) and 2 (the next newest). It might seem logical to place the line 24 WHERE clause directly in the line 17 query. However, that approach won’t work, because a SQL Server Tsql query “sees” the SELECT clause after the WHERE clause. As a result, the WHERE clause would never see the VERSION_NUMBER column in the SELECT clause, and the query would crash. If we place the WHERE clause outside this query, we’ll solve the problem. See this earlier article to learn more.
The Tsql query on lines 26 to 33 returns the finished result set. The FROM clause on line 32 defines the @DOCUMENT_TABLE_VAR table variable as the query source table. In line 26, the SELECT clause lists columns directly from the source table. Lines 28 to 31 rely on the VERSION_NUM values to place the DOCUMENT_TEXT and DATE_TIME_STAMP row values into four new columns in the final query result set.
|
1 2 3 4 5 6 7 8 9 10 |
VERSION_NUM = 1 -- LATEST VERSION VERSION_NUM = 2 -- NEXT LATEST VERSION NEW_DOCUMENT_TEXT NEW_DATE_TIME_STAMP OLD_DOCUMENT_TEXT OLD_DATE_TIME_STAMP |
We’ll examine line 28 from the “inside out” to understand the engineering. Line 28 builds values for the NEW_DOCUMENT_TEXT column with this code:
|
1 2 3 |
MAX(IIF ((VERSION_NUM = 1), DOCUMENT_TEXT, NULL)) AS NEW_DOCUMENT_TEXT |
For each result set row, the inner below the TSQL IIF function returns the DOCUMENT_TEXT value if VERSION_NUM equals 1.
|
1 2 3 |
IIF ((VERSION_NUM = 1), DOCUMENT_TEXT, NULL) |
For all other VERSION_NUM values, this IIF returns NULL. Line 28 passes this value to the MAX aggregate function. TThe TSQL MAX function takes only one parameter, either a column name or in this case, a string value. For a column name, the MAX function returns the highest value in that column, or each group of rows defined in the query GROUP BY clause. Now, when the MAX function receives a string value parameter, it will return that string, as seen in this screenshot:
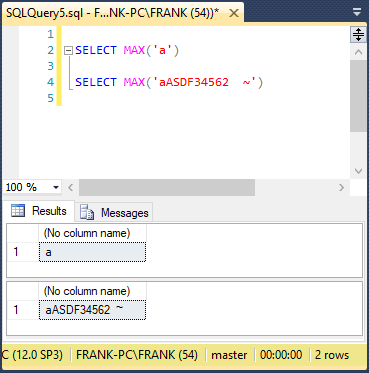
Microsoft documentation explains that the MAX function ignores NULL values. Based on all this, line 28 returns NULL if VERSION_NUM does not equal 1, and returns DOCUMENT_TEXT for that row if VERSION_NUM equals 1. Finally, line 28 will alias the column name as ‘NEW_DOCUMENT_TEXT.’ Line 30 operates the same way, for the ‘OLD_DOCUMENT_TEXT’ column. Lines 29 and 31 show that the MIN function works like the MAX function. The Tsql MIN and MAX aggregate functions expect the GROUP BY clause at line 33.
The second screenshot above showed the raw DOCUMENTS table data. For comparison with the query result set, this screenshot again shows the DOCUMENTS table data:
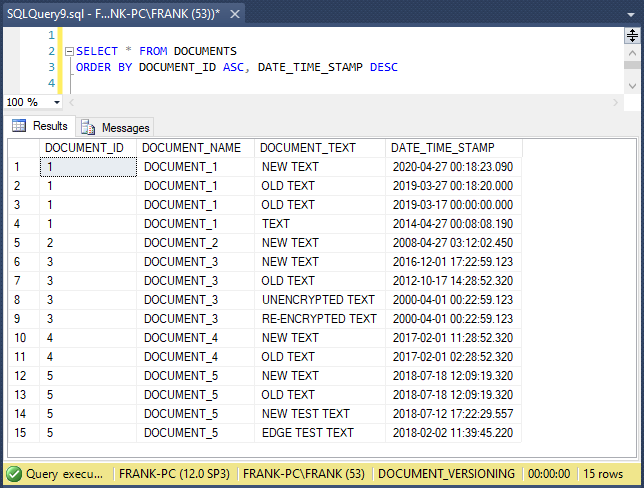
This screenshot shows the result set when we run the entire code sample:
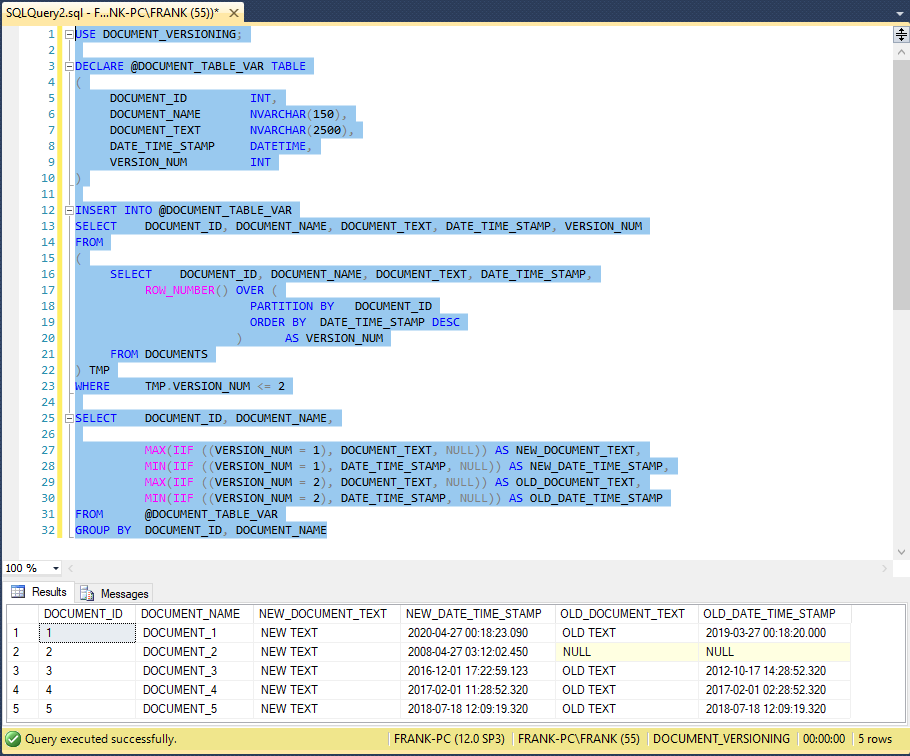
The DOCUMENT_1, DOCUMENT_3, and DOCUMENT_4 rows match our expectations. The DOCUMENT_2 row looks good, because the DOCUMENTS table had only one row for DOCUMENT_2. At line 29, the IIF function returned NULL.
|
1 2 3 |
MAX(IIF ((VERSION_NUM = 2), DOCUMENT_TEXT, NULL)) AS OLD_DOCUMENT_TEXT |
The TSQL MAX function ignored that NULL value, and passed it along to the result set, which we see in the OLD_DOCUMENT_TEXT column for result set row 2. In line 30, the MIN function operated the same way. The DOCUMENT_5 row involved an edge case, because the two newest DOCUMENT_5 rows have the same 2018-07-18 12:09:19.320 DATE_TIME_STAMP values. As a result, the ORDER BY clause in line 19 might not behave predictably. It can randomly sort rows based on matching values.
How about the Pivot Operator?
The solution described above pivoted the DOCUMENTS table data in a customized way. Maybe the SQL Server PIVOT operator could also solve this problem. Using the DOCUMENTS table data, this code uses the PIVOT operator to pivot the DOCUMENT_TEXT column as a partial solution:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
DECLARE @DOCUMENT_TABLE_VAR TABLE ( DOCUMENT_ID INT, DOCUMENT_NAME NVARCHAR(150), DOCUMENT_TEXT NVARCHAR(2500), DATE_TIME_STAMP DATETIME, VERSION_NUM INT ) INSERT INTO @DOCUMENT_TABLE_VAR SELECT DOCUMENT_ID, DOCUMENT_NAME, DOCUMENT_TEXT, DATE_TIME_STAMP, VERSION_NUM FROM ( SELECT DOCUMENT_ID, DOCUMENT_NAME, DOCUMENT_TEXT, DATE_TIME_STAMP, ROW_NUMBER() OVER ( PARTITION BY DOCUMENT_ID ORDER BY DATE_TIME_STAMP DESC ) AS VERSION_NUM FROM DOCUMENTS ) TMP WHERE TMP.VERSION_NUM <= 2 SELECT DOCUMENT_ID, DOCUMENT_NAME, [1] AS 'NEW_DOCUMENT_TEXT', [2] AS 'OLD_DOCUMENT_TEXT' FROM @DOCUMENT_TABLE_VAR PIVOT ( MAX(DOCUMENT_TEXT) FOR VERSION_NUM IN ([2], [1]) ) AS PivotTable ORDER BY DOCUMENT_ID ASC |
This screenshot shows the code in a query analyzer window:
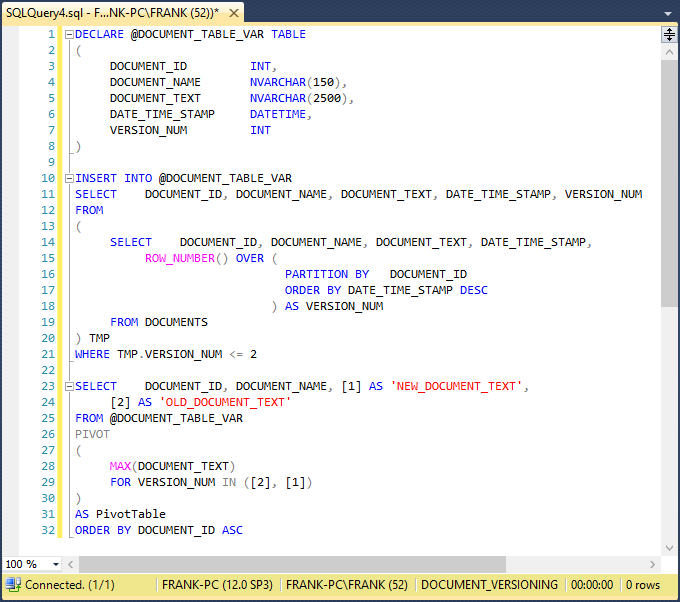
The PIVOT operator from lines 26 to 31 pivots the original DOCUMENT_TEXT column into different columns. It builds a column named ‘1’ for the latest DOCUMENT_TEXT versions, and ‘2’ for the next-latest DOCUMENT_TEXT versions. The Tsql MAX function at line 28 serves as the aggregate function that the PIVOT operator expects. MAX works the same way here as it did in the earlier solution, except that it won’t need a GROUP BY clause. In line 29, the FOR clause tells the PIVOT operator the VERSION_NUM values to use for the pivot columns it generates. The ORDER BY clause on line 32 sorts the result set. The SELECT clause on lines 23 and 24 builds the result set column list, changing the original ‘[1]’ and ‘[2]’ column names to more descriptive names. This screenshot shows the result set:
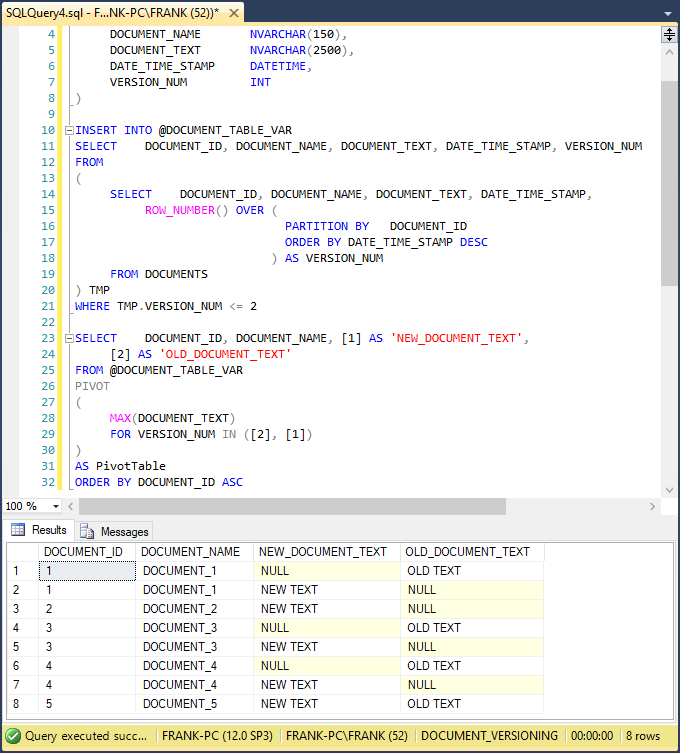
This query pivoted the DOCUMENT_TEXT values into the NEW_DOCUMENT_TEXT and OLD_DOCUMENT_TEXT columns. Unfortunately, it did not “merge” the rows. The result set we want would likely need a separate result set involving a DATE_TIME_STAMP column pivot, which would have the same problem. Then, we’d have to somehow combine both pivoted, merged result sets into one result set. The whole thing would become really complex. The actual solution shown earlier clearly becomes the better way to go.
Conclusion
For SQL Server data versioning, we need a flexible, effective technique that covers the gaps that the PIVOT operator can’t handle. As we saw, the Tsql MAX and MIN aggregate functions, combined with IIF, will solve the problem with fine-grained control.
See more
Seamlessly integrate a powerful, SQL formatter into SSMS and/or Visual Studio with ApexSQL Refactor. ApexSQL Refactor is a SQL query formatter but it can also obfuscate SQL, refactor objects, safely rename objects and more – with nearly 200 customizable options


See more about Frank at LinkedIn.
Remove the non-standard characters from this address: fb} <s.author@gmail.com to reach him by email.
- Lever the TSQL MAX/MIN/IIF functions for Pinpoint Row Pivots - May 16, 2022
- Use Kusto Query Language to solve a data problem - July 5, 2021
- Azure Data Explorer and the Kusto Query Language - June 21, 2021