
In this article, we will learn how we can load data into Azure SQL Database from Azure Databricks using Scala and Python notebooks.
With unprecedented volumes of data being generated, captured, and shared by organizations, fast processing of this data to gain meaningful insights has become a dominant concern for businesses. One of the popular frameworks that offer fast processing and analysis of big data workloads is Apache Spark.
Azure Databricks is the implementation of Apache Spark analytics on Microsoft Azure, and it integrates well with several Azure services like Azure Blob Storage, Azure Synapse Analytics, and Azure SQL Database, etc. Spinning up clusters in fully managed Apache Spark environment with benefits of Azure Cloud platform could have never been easier. In case you are new to Databricks, you can benefit and understand its basics from this tutorial here.
Data processing is one vital step in the overall data life cycle. Once this data is processed with the help of fast processing clusters, it needs to be stored in storage repositories for it to be easily accessed and analyzed for a variety of future purposes like reporting.
In this article, we will load the processed data into the SQL Database on Azure from Azure Databricks. Databricks in Azure supports APIs for several languages like Scala, Python, R, and SQL. As Apache Spark is written in Scala, this language choice for programming is the fastest one to use.
Let’s go ahead and demonstrate the data load into SQL Database using both Scala and Python notebooks from Databricks on Azure.
Preparations before demo
Before we start with our exercise, we will need to have the following prerequisites:
- You need to have an active Azure Subscription. If you don’t have it, you can create it here
- Azure Databricks – You need to set up both Databricks service and cluster in Azure, you can go over the steps in this article, A beginner’s guide to Azure Databricks to create these for you. As shown in this article, we have created a Databricks service named “azdatabricks” and Databricks cluster named “azdatabrickscluster”
- Azure SQL Database – Creating a SQL Database on Azure is a straight-forward process. I have put out screenshots below to throw a quick idea on how to create a SQL Database on Azure
On the Azure portal, you can either directly click on Create a resource button or SQL databases on the left vertical menu bar to land on the Create SQL Database screen.

Provide details like Database name, its configuration, and create or select the Server name. Click on the Review + create button to create this SQL database on Azure.

Check out this official documentation by Microsoft, Create an Azure SQL Database, where the process to create a SQL database is described in great detail.
Uploading a CSV file on Azure Databricks Cluster
We will be loading a CSV file (semi-structured data) in the Azure SQL Database from Databricks. For the same reason, let’s quickly upload a CSV file on the Databricks portal. You can download it from here. Click on the Data icon on the left vertical menu bar and select the Add Data button.

Browse and choose the file that you want to upload on Azure Databricks.

Once uploaded, you can see the file “1000 Sales Records.csv” being uploaded on the Azure Databricks service. Take a note of the path name of the file: /FileStore/tables/1000_Sales_Records-d540d.csv. We will use this path in notebooks to read data.

Load data into Azure SQL Database from Azure Databricks using Scala
Hit on the Create button and select Notebook on the Workspace icon to create a Notebook.

Type in a Name for the notebook and select Scala as the language. The Cluster name is self-populated as there was just one cluster created, in case you have more clusters, you can always select from the drop-down list of your clusters. Finally, click Create to create a Scala notebook.

We will start by typing in the code, as shown in the following screenshot. Let’s break this chunk of code in small parts and try to understand.

In the below code, we will first create the JDBC URL, which contains information like SQL Server, SQL Database name on Azure, along with other details like Port number, user, and password.
|
1 |
val url = "jdbc:sqlserver://azsqlshackserver.database.windows.net:1433;database=azsqlshackdb;user=gauri;password=*******" |
Next, we will create a Properties() to link the parameters.
|
1 2 3 4 |
import java.util.Properties val myproperties = new Properties() myproperties.put("user", "gauri") myproperties.put("password", "******") |
The following code helps to check the connectivity to the SQL Server Database.
|
1 2 |
val driverClass = "com.microsoft.sqlserver.jdbc.SQLServerDriver" myproperties.setProperty("Driver", driverClass) |
Lastly, we will read the CSV file into mydf data frame. With header = true option, the columns in the first row in the CSV file will be treated as the data frame’s columns names. Using inferSchema = true, we are telling Spark to automatically infer the schema of each column.
|
1 2 3 4 |
val mydf = spark.read.format("csv") .option("header","true") .option("inferSchema", "true") .load("/FileStore/tables/1000_Sales_Records-d540d.csv") |
We will use the display() function to show records of the mydf data frame.
|
1 |
display(mydf) |

Transforming the data
Now, let’s try to do some quick data munging on the dataset, we will transform the column SalesChannel -> SalesPlatform using withColumnRenamed() function.
|
1 2 |
val transformedmydf = mydf.withColumnRenamed("SalesChannel", "SalesPlatform") display(transformedmydf) |

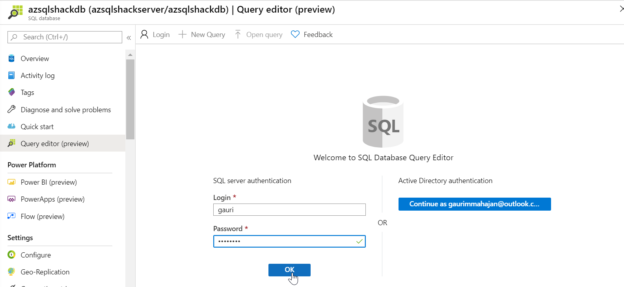
Before we load the transformed data into the Azure SQL Database, let’s quickly take a peek at the database on the Azure portal. For this go to the portal, and select the SQL database, click on the Query editor (preview),

And provide your Login and Password to query the SQL database on Azure. Click OK.

The below screenshot shows that currently, there are no tables, no data in this database.

Loading the processed data into Azure SQL Database using Scala
On the Azure Databricks portal, execute the below code. This will load the CSV file into a table named SalesTotalProfit in the SQL Database on Azure.
|
1 |
Transformedmydf.write.jdbc(url,"SalesTotalProfit",myproperties) |

Head back to the Azure portal, refresh the window and execute the below query to select records from the SalesTotalProfit table.
|
1 |
SELECT * FROM [dbo].[SalesTotalProfit] |

The data is loaded into the table, SalesTotalProfit in the database, azsqlshackdb on Azure. And you can perform any operations on the data, as you would do in any regular database.
|
1 2 3 4 |
UPDATE [dbo].[SalesTotalProfit] SET ItemType = ‘Clothing’ WHERE ItemType = ‘Clothes’ SELECT * FROM [dbo].[SalesTotalProfit] |

The following code reads data from the SalesTotalProfit table in the Databricks. Here, we are processing and aggregating the data per Region and displaying the results.
|
1 2 |
val azsqldbtable = spark.read.jdbc(url, "SalesTotalProfit", myproperties) display(azsqldbtable.select("Region", "TotalProfit").groupBy("Region").avg("TotalProfit") |

Load data into Azure SQL Database from Azure Databricks using Python
Let’s create a new notebook for Python demonstration. Just select Python as the language choice when you are creating this notebook. We will name this book as loadintoazsqldb.
The following code sets various parameters like Server name, database name, user, and password.
|
1 2 3 4 5 6 |
jdbcHostname = "azsqlshackserver.database.windows.net" jdbcPort = "1433" jdbcDatabase = "azsqlshackdb" properties = { "user" : "gauri", "password" : "******" } |

The below code creates a JDBC URL. We will use sqlContext() to read the csv file and mydf data frame is created as shown in the screenshot below.
|
1 2 |
url = "jdbc:sqlserver://{0}:{1};database={2}".format(jdbcHostname,jdbcPort,jdbcDatabase) mydf = sqlContext.read.csv("/FileStore/tables/1000_Sales_Records-d540d.csv",header=True) |

We will import the pandas library and using the DataFrameWriter function; we will load CSV data into a new dataframe named myfinaldf. And finally, write this data frame into the table TotalProfit for the given properties. In case, this table exists, we can overwrite it using the mode as overwrite.
|
1 2 3 4 |
from pyspark.sql import * import pandas as pd myfinaldf = DataFrameWriter(mydf) myfinaldf.jdbc(url=url, table= "TotalProfit", mode ="overwrite", properties = properties) |

Go to Azure Portal, navigate to the SQL database, and open Query Editor. Open the Tables folder to see the CSV data successfully loaded into the table TotalProfit in the Azure SQL database, azsqlshackdb.

Conclusion
Azure Databricks, a fast and collaborative Apache Spark-based analytics service, integrates seamlessly with a number of Azure Services, including Azure SQL Database. In this article, we demonstrated step-by-step processes to populate SQL Database from Databricks using both Scala and Python notebooks.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023