
Introduction
Database deployments are critical tasks that can affect negative in on performance in production. In this article we’ll describe some performance related best practices for database deployments.
In this article, I’ll cover several aspects of Microsoft SQL Server databases deployment process including :
- Database deployment prerequisites
- Database Schema design assessments
- Database stress tests
- Application stress tests
- Database index analysis
Prerequisites
The first thing we should do is to collect some fundamental information about this new database to be familiar with the business logic of it, usage, capacity plan, etc. The following are some examples
- Is there any field(s) in this database that contains(s) XML or Binary information? IF << YES >> we need a bit more clarity about the usage type of those data entities,
- Are they used as transactional or lookup data entities?
- If transactional, are there any reports to be generated from XML
- What is the maximum expected number of records for further one year?
- Are there any special configuration(s) that should be considered during the deployment such as:
- DTC (Distributed Transaction Coordinator)
- Service Broker
- CLR and assembly, if so what type of assembly, external access, unsafe, safe are supported by GAC (Global assembly cache) or it might need any other external Common Language Runtime modules or PowerShell files?
- RCSI (Read Committed Snapshot Isolation level)
- Encryption and if so what kind of encryption algorithms used
- What is the key provisioning used there, I mean what DMK, Certificate, asymmetric key, etc. ?
- Elevated privileges for application service account?
- Certain data engineering solution like data archiving, data migration, data cleansing jobs?
- Special scheduled jobs to send reports or do some DML operations?
- SSRS (SQL Server Reporting service) Reports? if so please mentioned their URLs and grant content manager privileges for us
- Any existing OLAP cubes or BI solution?
- Linked server or distributed queries
- Replication or transaction log shipping with other Databases on other servers?
- Any direct access from outside by any other users or systems?
- What the AD (Active Directory user) that will be Application services account?
- What the application server (Name/IP)? To open the SQL port with it
These provide a good set of example checks to help conclude the Database size, usage, requirements, configuration etc
Analysis
Before we start we should do a pre-deployment analysis of potential performance issues including:
- Database Schema Design review
- Stored procedures Stress tests
- Application Stress tests
- Index analysis
Database schema design review
The following are some example
- What are the fields and objects we should check?
- What is the performance risks that we should keep in mind while designing the database deployment process, for example:
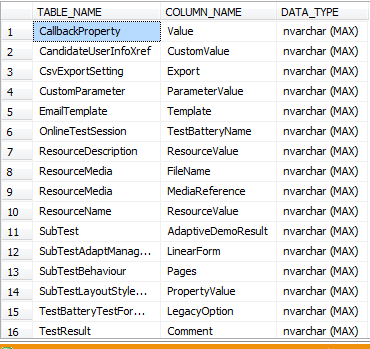
- Columns data types should be appropriate for the usage of this column. Therefore Nvarchar (MAX) or Varchar (MAX) are generally inappropriate because we can’t include them by any index because the index has size limitation 900 bytes and these columns store more than 8000 bytes.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT TABLE_NAME, COLUMN_NAME , DATA_TYPE + ' (MAX)' AS DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS INFO INNER JOIN Sys.Tables T ON Info.TABLE_NAME = T.name WHERE Info.CHARACTER_MAXIMUM_LENGTH = '-1' AND DATA_TYPE NOT IN ( 'text', 'Image', 'Ntext', 'FILESTREAM', 'Xml', 'varbinary' ) ORDER BY TABLE_NAME |
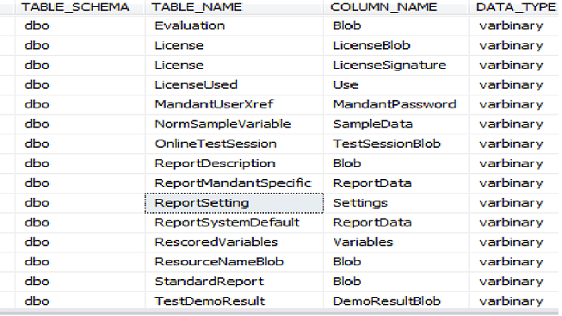
- BOLB and XML Columns: Check the columns with data types Text, Image, Next, FILESTREAM, XML, varbinary} as ideally, we ought to avoid these, unless absolutely needed
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH schema_design AS ( SELECT info.TABLE_CATALOG , --SCHEMA_NAME(schema_id) AS [SCHEMA_Name], info.TABLE_SCHEMA as TABLE_SCHEMA, --'['+SCHEMA_NAME(schema_id)+'].['+T.name+']' as TABLE_NAME, Info.TABLE_NAME, info.COLUMN_NAME, INfo.DATA_TYPE, Info.COLLATION_NAME, INfo.CHARACTER_MAXIMUM_LENGTH, INfo.CHARACTER_OCTET_LENGTH, C.is_computed, C.is_filestream ,C.is_identity, COLUMNPROPERTY(object_id(TABLE_NAME), COLUMN_NAME, 'IsIdentity')AS IsIdentity, COLUMNPROPERTY(object_id(TABLE_NAME), COLUMN_NAME, 'IsPrimaryKey')AS IsPrimaryKey from Sys.Columns as C inner join INFORMATION_SCHEMA.COLUMNS info on info.TABLE_NAME = OBJECT_NAME(C.Object_Id) and Info.COLUMN_NAME = C.name --Select Distinct Info.Table_Name,Info.TABLE_CATALOG from INFORMATION_SCHEMA.COLUMNS info Inner Join Sys.Tables T On Info.TABLE_NAME = T.name ) SELECT * FROM schema_design WHERE DATA_TYPE IN ('text' , 'Image','Ntext','FILESTREAM','Xml','varbinary','sql_variant') ORDER BY TABLE_NAME |
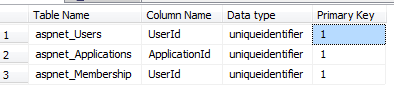
Uniqueidentifier Columns AS primary key: is not preferred for many reasons
- GUID is 16 byte but the INT columns is 4 byte so the GUID will be required to have more read and write logical reads apart from the storage requirements which GUIDs require more.
- If we use the GUID as clustered index for every insert we should change the layout of the data as it is not like the Identity INT columns
For better results, consider using integer identity columns. Or at least newsequentialid() instead of a Primary Key on GUID
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
WITH CTE AS ( SELECT S.name AS [Table Name] , c.name 'Column Name' , t.name 'Data type' , ISNULL(i.is_primary_key, 0) 'Primary Key' FROM sys.columns c INNER JOIN sys.types t ON c.user_type_id = t.user_type_id INNER JOIN sys.tables S ON S.object_id = c.object_id LEFT OUTER JOIN sys.index_columns ic ON ic.object_id = c.object_id AND ic.column_id = c.column_id LEFT OUTER JOIN sys.indexes i ON ic.object_id = i.object_id AND ic.index_id = i.index_id ) SELECT * FROM CTE WHERE [Data type] = 'uniqueidentifier' AND CTE.[Primary Key] = 1; |
- Columns size : the columns should be created with most suitable size to be able to cover it by the index model,
An index key length is 900 byte. If we assume we have column NVARCHAR (500) the actual size is 1000 byte and if we created any index with key columns size > 900 bytes it would impact on the OLTP transaction, and it will show for us the below warning:
The maximum key length is 900 bytes. The index has a maximum length of 1200 bytes. For some combination of large values, the insert/update operation will fail
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT TABLE_NAME , COLUMN_NAME , DATA_TYPE , CHARACTER_MAXIMUM_LENGTH , CHARACTER_OCTET_LENGTH FROM INFORMATION_SCHEMA.COLUMNS INFO INNER JOIN Sys.tables T ON INFO.TABLE_NAME = T.Name WHERE Info.CHARACTER_MAXIMUM_LENGTH > '256' AND Data_type NOT IN ( 'text', 'Image', 'Ntext', 'FILESTREAM', 'Xml', 'varbinary' ) ORDER BY CHARACTER_MAXIMUM_LENGTH DESC |
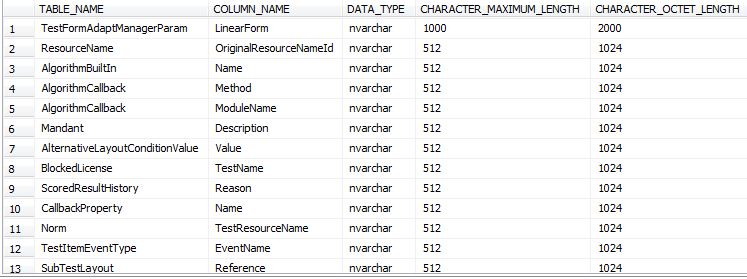
- Heap Tables: This means the tables without primary key or clustered indexes, and these kinds of tables should be not accepted because they will generate extremely poor SQL Server Execution Plans for queries trying to get the data from the application.
Attached is a Stored Procedure “Check_Heap_Tables” and this SQL Server Stored Procedure will generate a T-SQL script for each Database and Table which is Heap Table and it will print out the required clustered index to be created for highlighted tables.
|
1 2 3 4 5 |
Use MSDatabase Go Exec dbo.[Check_Heap_Tables] |
Stored procedures stress test
In this second phase our main focus in the most used stored procedures that we should execute it on 200 concurrent user minimum and 1000 concurrent user maximum for the purpose of stress testing the Application Level Stored Procedures for performance testing.
We can do this process by utilizing any stress tool, but we should fill the tables by at least 1 million of rows. In our case we’ll use ApexSQL Generate to help us highlight any potential issues via the query execution plan
Although there are multiple ways to tune-up TSQL some examples given below:
- Use table hint {MAXDOP, FAST, Keep FixdPlan, Set Nocount on, With Nolock , Index forceseek ..Etc}
- Create sufficient indexes to reduce the IO and CPU
- Use dynamic queries
Application stress test
Most recently, many applications use Entity Framework at the application layer to access the database. This Framework does not allow the queries to be written directly; instead it generates queries on its own as required by the application and business logic based on the underlying tables. So, the database does not have the business logic inside the SQL Server.
For optimizing and stress testing the code we need to capture the business logic code by running stress test scenarios for like 200~300 concurrent users. And ultimately able to capture poorly written or worst performing TSQL.
Eventually, the goal here is to get the bad TSQL in hand and optimize it and give it back to the application team so that they can integrate it and merge inside the application for optimizing the business by converting the queries into SQL Server Custom Written Stored Procedures.
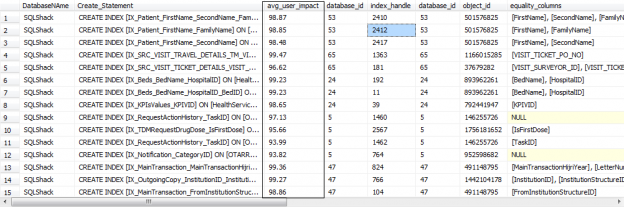
Index Analysis
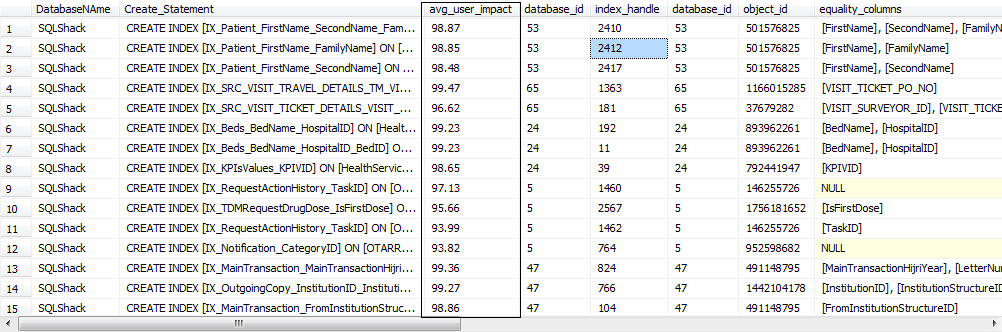
After all of the stress testing performed on the database for potential problematic Stored Procedures and T-SQL queries, SQL Server engine will save the required missing indexes in the system tables which we can now query.
After analyzing the Missing Indexes from the System Stored Procedures, we can start to create the appropriate missing indexes on the tables. This process should be done only by experienced DatabaseAs and in collaboration with the Development team to enhance the performance of the poorly performing quires and Stored Procedures.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
SELECT B.name AS DatabaseNAme,D.database_id,D.* , s.avg_total_user_cost , s.avg_user_impact , s.last_user_seek , s.last_user_scan , s.unique_compiles , 'CREATE INDEX [IX_' + OBJECT_NAME(d.object_id, d.database_id) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(d.equality_columns, ''), ', ', '_'), '[', ''), ']', '') + CASE WHEN d.equality_columns IS NOT NULL AND d.inequality_columns IS NOT NULL THEN '_' ELSE '' END + REPLACE(REPLACE(REPLACE(ISNULL(d.inequality_columns, ''), ', ', '_'), '[', ''), ']', '') + ']' + ' ON ' + d.statement + ' (' + ISNULL(d.equality_columns, '') + CASE WHEN d.equality_columns IS NOT NULL AND d.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(d.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + d.included_columns + ')', '') + ' WITH(FILLFACTOR = 80 , DATA_COMPRESSION = PAGE) ' + CHAR(10) + CHAR(13) + 'PRINT ''Index ' + CONVERT(VARCHAR(10), ROW_NUMBER() OVER ( ORDER BY avg_user_impact DESC )) + ' [IX_' + OBJECT_NAME(d.object_id, d.database_id) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(d.equality_columns, ''), ', ', '_'), '[', ''), ']', '') + CASE WHEN d.equality_columns IS NOT NULL AND d.inequality_columns IS NOT NULL THEN '_' ELSE '' END + REPLACE(REPLACE(REPLACE(ISNULL(d.inequality_columns, ''), ', ', '_'), '[', ''), ']', '') + '] ' + ' created '' + CONVERT(VARCHAR(103),GETDATE())' + CHAR(10) + CHAR(13) + ' Go' + CHAR(10) + CHAR(13) AS Create_Statement FROM sys.dm_db_missing_index_group_stats s , sys.dm_db_missing_index_groups g , sys.dm_db_missing_index_details d INNER JOIN Sys.databases AS B ON d.database_id = B.database_id WHERE s.group_handle = g.index_group_handle AND d.index_handle = g.index_handle AND s.avg_user_impact >= 90 AND D.database_id > 4 AND B.NAME <> 'distribution' ORDER BY name,avg_user_impact DESC go |
Conclusion
Be aware that your production environment is a restricted area and never deploy anything without a clear and well documented assessment process, to ensure the best performance of your production database.
References
- Warning the Maximum Key Length is 900 bytes
- Improving Uniqueidentifier Performance
- GUID vs INT Debate
- How It Works: Gotcha: *VARCHAR(MAX) caused my queries to be slower

Currently, he is working as a Senior consultant production DBA and Development DBA in many projects in multiple government sectors. He is a Top SQL Server blogger in the Middle East, founder of the community mostafaelmasry.com, and is the second Arabic author on Microsoft MSDN in SQL Server.
Based on his current position, he solved fairly interesting problems on fairly large databases and highly sensitive performance cases.
View all posts by Mustafa EL-Masry
- Concept and basics of DBCC Commands in SQL Server - March 31, 2017
- Hybrid Cloud and Hekaton Features in SQL Server 2014 - February 28, 2017
- How to analyze Storage Subsystem Performance in SQL Server - February 23, 2017