

SQL Server 2008 introduces a new column attribute that is used to reduce the storage consumed by NULL values in the database tables. This feature is known as Sparse Columns. Sparse Columns work effectively in the case of the columns with high proportion of NULL values, as SQL Server will not consume any space storing the NULL values at all, which helps in optimizing the SQL storage usage.
A trade-off when using the Sparse Columns is the additional 4 bytes space required to store the non-NULL values in the Sparse Columns. So, it is recommended not to use the Sparse Columns unless the column has a high percentage of NULL values in it, in order to gain the storage saving benefits of the Sparse Column feature.
When you store a NULL value in a fixed-length column such as a column with INT data type, the NULL value will consume the whole column length. But if you store that NULL value in a variable-length column such as a column with VARCHAR data type, it will consume only two bytes from the column’s length. Using Sparse Columns, NULL value will not consume any space regardless of using fixed-length or variable-length columns. But as mentioned previously, the trade-off here is the additional 4 bytes when storing non-NULL values in the Sparse Column. For example, a column with BIGINT datatype consumes 8 bytes when storing actual or NULL values in it. Defining that BIGINT column as Sparse Column, it will consume 0 bytes storing NULL values, but 12 bytes storing non-NULL values in it.
The reason why NULL values in the Sparse Columns consume 0 bytes and the non-NULL values consumes extra 4 bytes is that the Sparse Column values will not be stored with the normal columns, instead it is stored in a special structure at the end of each row, with 2 bytes to store the non-NULL values IDs and 2 bytes to store the non-NULL values offsets. This complex structure results in extra overhead too to retrieve the non-NULL values from the Sparse Columns.
Enjoying the storage optimization benefits of the Sparse Columns depends on the datatype of that Sparse Column. For example, the NULL values percentage of a column with BIGINT or DATETIME datatypes should not be less than 52% of the overall column values to take benefits of the Sparse Columns space saving, and should not be less than 64% for the INT datatype. On the other hand, 98% NULL values from a column with BIT datatype will allow you to take benefits of the Sparse Column storage optimization.
Sparse Columns can be defined easily by adding the SPARSE keyword beside the column’s definition. The NULL keyword in the Sparse Column definition is optional, as the Sparse Column must allow NULL values. As a result, Sparse Columns can’t be configured as Primary Key, IDENTITY or ROWGUIDCOL columns. You should take into consideration when you define a Sparse Column that you can’t assign the default value for the Sparse Column. Also, Computed columns can’t be defined as Sparse Columns. The text, ntext, image, vbinary(max) , geometry, geography, timestamp and user-defined datatypes can’t be used for the Sparse Columns. Sparse columns don’t support also data compression.
Let’s have a small demo to understand the Sparse Columns feature practically. We will start with creating two new tables in our SQLShackDemo test database with the same schema, except that the Emp_Last_Name , Emp_Address, and Emp_Email columns on the SPARSEDemo_WithSparse table are defined with the SPARSE attribute as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
USE SQLShackDemo GO CREATE TABLE SPARSEDemo_WithSparse ( ID int IDENTITY (1,1), Emp_First_Name VARCHAR(50) NULL, Emp_Last_Name VARCHAR(50) SPARSE, TS DateTime NULL, Emp_Address VARCHAR(100) SPARSE, Emp_Email VARCHAR(100) SPARSE, )ON [PRIMARY] GO CREATE TABLE SPARSEDemo_WithoutSparse ( ID int IDENTITY (1,1), Emp_First_Name VARCHAR(50) NULL, Emp_Last_Name VARCHAR(50) NULL, TS DateTime NULL , Emp_Address VARCHAR(100) NULL, Emp_Email VARCHAR(100) NULL, )ON [PRIMARY] GO |
You can also define a column with SPARSE property using the SQL Server Management Studio tool. Right-click on the target table and select the Design option, then select the column you need to define as Sparse Column and change the Is Sparse property from the Column Properties page to Yes as in the below figure:
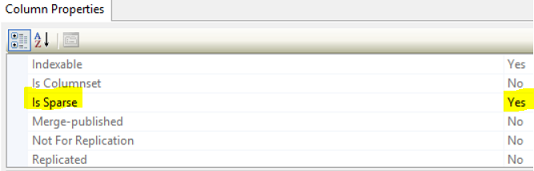
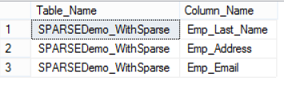
The Is_Sparse property can be checked by querying the sys.objects and sys.columns system tables with the columns with is_sparse property value equal 1 as in the below query:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE SQLShackDemo GO SELECT OBJ.name Table_Name, COL.name Column_Name FROM sys.columns COL JOIN sys.objects OBJ ON OBJ.OBJECT_ID = COL.OBJECT_ID WHERE is_sparse = 1 GO |
The output in our case will be like:
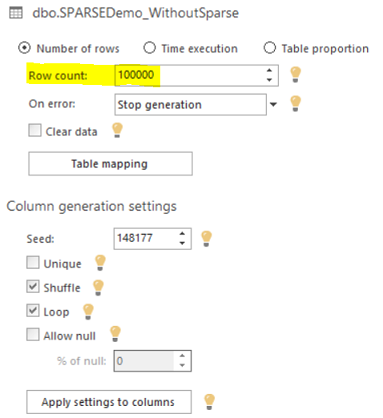
The two tables are created now. We will use the ApexSQL Generate tool to fill the SPARSEDemo_WithoutSparse table with 100,000 records after connecting to the local SQL Server instance as follows:
In order to have fair comparison between the table with Sparse Columns and the one without, we will fill the same data from the SPARSEDemo_WithoutSparse table to the SPARSEDemo_WithSparse one:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[SPARSEDemo_WithSparse] ([Emp_First_Name] ,[Emp_Last_Name] ,[TS] ,[Emp_Address] ,[Emp_Email]) SELECT [Emp_First_Name] ,[Emp_Last_Name] ,[TS] ,[Emp_Address] ,[Emp_Email] from SPARSEDemo_WithoutSparse GO |
Using the sp_spaceused system object to check the storage properties for the two tables:
|
1 2 3 4 5 6 |
sp_spaceused 'SPARSEDemo_WithoutSparse' GO sp_spaceused 'SPARSEDemo_WithSparse' GO |
The result will be like:

The previous shocking numbers meet what we mentioned previously, that the non-NULL values on the Sparse Columns will consume extra 4 bytes for each value, resulting more space consumption.
Let’s update the Emp_Last_Name , Emp_Address and Emp_Email columns to have a high percentage of NULL values on both tables with and without Sparse properties:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE SQLShackDemo GO Update SPARSEDemo_WithSparse set Emp_Last_Name = NULL WHERE ID >20000 and ID <80000 GO Update SPARSEDemo_WithSparse set Emp_Address = NULL WHERE ID >60000 and ID <80000 GO Update SPARSEDemo_WithSparse set Emp_Email = NULL WHERE ID >20000 and ID <100000 GO Update SPARSEDemo_WithoutSparse set Emp_Last_Name = NULL WHERE ID >20000 and ID <80000 GO Update SPARSEDemo_WithoutSparse set Emp_Address = NULL WHERE ID >60000 and ID <80000 GO Update SPARSEDemo_WithoutSparse set Emp_Email = NULL WHERE ID >20000 and ID <100000 GO |
After changing the values, we will check the NULL values percentage in each column. Remembering that the NULL values percentage in the Sparse Columns decide if we will take benefits of the space saving advantage of the Sparse Column or not, taking into consideration that this percentage for the VARCHAR data type is 60%:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT COUNT (ID) NumOfNullLastName, cast(COUNT (ID) as float)/100000 NullPercentage FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] WHERE Emp_Last_Name is NULL GO SELECT COUNT (ID) NumOfNullAddress,cast(COUNT (ID) as float)/100000 NullPercentage FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] WHERE Emp_Address is NULL GO SELECT COUNT (ID) NumOfNullEmail,cast(COUNT (ID) as float)/100000 NullPercentage FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] WHERE Emp_Email is NULL |
The percentage will be similar to:
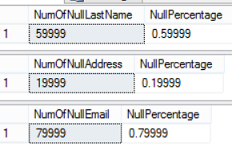
As you can see from the previous result, we will take benefits of defining the Emp_Last_Name and Emp_Email columns as Sparse Columns, as the Null Values percentage is over or equal to 60%. Defining the Emp_Address column as Sparse Column is not the correct decision here.
If you run the previous sp_spaceused statements again to check the space usage after the update, you will see no space consumption change on the table with no Sparse Columns, but you will notice a big difference in the case of the table with Sparse Columns due to high percentage of NULL values:
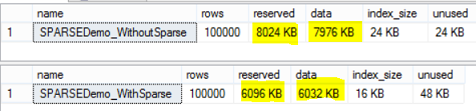
If we change the Sparse Column property of the Emp_Address column in the previous example, and check the space consumption after the change, the numbers will show us that having this column as Sparse Column is worse than having it a normal one as below:
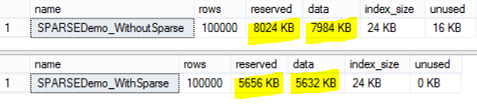
Again, if we try to change all the Emp_Last_Name , Emp_Address and Emp_Em columns values to NULL:
|
1 2 3 4 5 6 |
update SPARSEDemo_WithSparse set Emp_Last_Name = NULL , Emp_Address=NULL , Emp_Email=NULL GO update SPARSEDemo_WithoutSparse set Emp_Last_Name = NULL , Emp_Address=NULL , Emp_Email=NULL GO |
And check the space consumption using the sp_spaceused system object, we will see that the space consumption of the first table without the Sparse Columns will not be affected, and the space consumption of the second one with Sparse Columns changed clearly as follows:

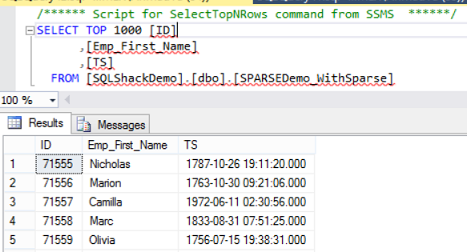
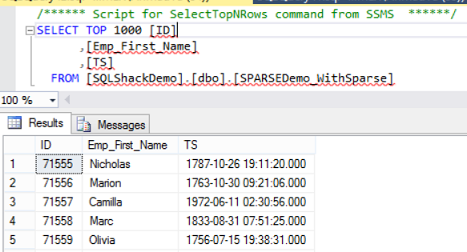
When trying to Select Top 1000 Rows from the database table with Sparse Columns, SQL Server will retrieve only the non-Sparse columns:
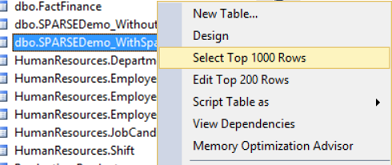
The result will exclude the Emp_Last_Name , Emp_Address and Emp_Email columns as below:
As retrieving the non-Null values from the Sparse columns will slow down the query. If we try to run the previous SELECT statement retrieved from the SSMS that excludes the Sparse Columns and the SELECT * statement after turning the STATISTICS TIME ON:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SET STATISTICS TIME ON SELECT [ID] ,[Emp_First_Name] ,[TS] FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] GO SELECT * FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] SET STATISTICS TIME OFF |
You will notice clearly the performance overhead that is resulted from reading the Sparse Columns with non-NULL values as below:

SQL Server Filtered Non-Clustered Indexes can be used with the Sparse Columns in order to enhance the queries performance in addition to the space saving gain from the Sparse Columns. With the Sparse Column, the filtered index will be smaller and faster than the normal non-clustered index, as it will store only the data that meets the criteria specified in the WHERE clause of the index definition. You can easily exclude the NULL values in the filtered index to make the index smaller and more efficient.
We will first define the ID column in our sparse demo table as Primary Key:
|
1 2 3 4 5 6 |
ALTER TABLE [dbo].[SPARSEDemo_WithSparse] ADD CONSTRAINT [PK_SPARSEDemo_WithSparse] PRIMARY KEY CLUSTERED ( [ID] ASC ) |
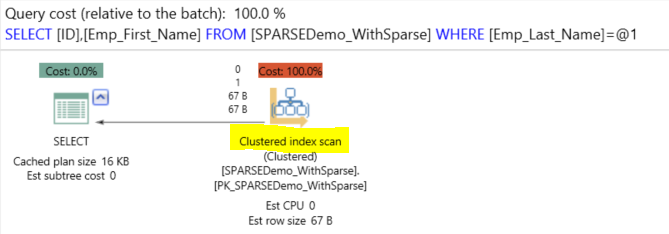
If we try to run the below simple SELECT statement from the SPARSEDemo_WithSparse table and check the query execution plan and time and IO statistics:
|
1 2 3 4 5 |
USE SQLShackDemo GO SELECT ID, Emp_First_Name FROM SPARSEDemo_WithSparse where [Emp_Last_Name] = 'Jenkins' |
The result will show us that SQL Server scans all records in the clustered index to retrieve the data, performs 759 logical reads, consumes 16 ms from the CPU time and takes 52 ms to finish:
Let’s create a non-clustered filtered index on the Emp_Last_Name column INCLUDE the Emp_First_name column, excluding the Emp_Last_Name NULL values from the index in order to be small one:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_SPARSEDemo_WithSparse_Emp_Last_Name] ON [dbo].[SPARSEDemo_WithSparse] ( [Emp_Last_Name] ASC ) INCLUDE ( [Emp_First_Name]) WHERE ([Emp_Last_Name] IS NOT NULL) GO |
If we try to run the previous SELECT statement after creating the index, an index seek will be used on the table to retrieve the data, performing only 5 logical reads, consuming 0 ms from the CPU time and taking 41 ms to finish. With clear variation from the statistics without using that filtered index:

SQL Server provides you with a way to combine all the Sparse Columns in your table and return it in an untyped XML representation, this new feature is called the Column Set. The Column Set concept is similar to the computed column concept, where SQL Server will gather all Sparse Columns in your table into a new column that is not physically stored in the table, with the ability to retrieve and update it directly from that new column. And you still able to access these Sparse Columns individually by providing the column name. This feature is useful when you have a large number of Sparse Columns in your table, which allows you to operate on these set of columns in one shot, as working on it individually is very difficult.
Column Set can be defined by adding the COLUMN_SET FOR ALL_SPARSE_COLUMNS keywords when creating or altering your table. The Column Set can be specified in the definition of the table that contains Sparse Columns which will appear directly, or to a table without any Sparse Column, where it will appear once you add these Sparse Columns. Take into consideration that you can define only one Column Set per each table, and once this Column Set is created, it can’t be changed unless you drop the Sparse Columns and Column Set or the table and create it again. The Column Set can’t be used in Replication, Distributed Queries, and CDC features. Also, you can’t index the Column Set.
The Column Set can’t be added to a table that contains Sparse Columns. If we try to add a new Column Set to our Sparse demo table using the below ALTER TABLE statement:
|
1 2 3 4 |
ALTER TABLE SPARSEDemo_WithSparse ADD EmployeeSet XML COLUMN_SET FOR ALL_SPARSE_COLUMNS |
SQL Server will not allow us to create that Column Set on that table that already contains Sparse Columns:

To create the Column Set successfully, we will drop the table and create it again after taking the backup from the existing data to a temp table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [SQLShackDemo] GO DROP TABLE SPARSEDemo_WithSparse GO CREATE TABLE [dbo].[SPARSEDemo_WithSparse]( [ID] [int] IDENTITY(1,1) NOT NULL, [Emp_First_Name] [varchar](50) NULL, [Emp_Last_Name] [varchar](50) SPARSE NULL, [TS] [datetime] NULL, [Emp_Address] [varchar](100) SPARSE NULL, [Emp_Email] [varchar](100) SPARSE NULL, [EmployeeSet] XML COLUMN_SET FOR ALL_SPARSE_COLUMNS ) ON [PRIMARY] GO |
Assume that we filled the table again from the temp backup, if we try to SELECT data from that table, the result will contain additional column in XML format that contains all Sparse Columns values as follows:
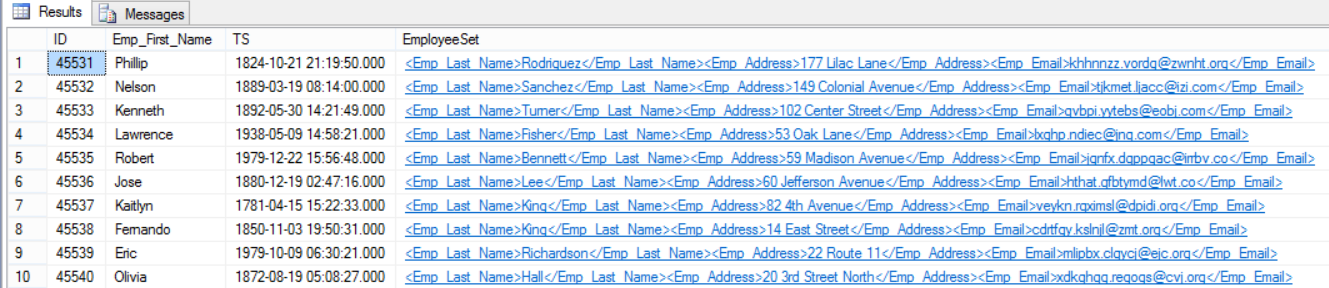
You can also check the Column Set value in more readable format by clicking on the XML blue value which will be displayed in separate window as the below:

To see how we can take benefits from the Column Set, we will change the Emp_Last_Name and the Emp_Email of an employee with ID 45531 from the ColumnSet XML column in one shot and check if this change will be replicated to the source Sparse Columns. Let’s first check the values before the update:
|
1 2 3 |
SELECT * FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] where ID = 45531 |
The result will be similar to:

Now we will perform the update by adding the “phill” to the last name and the last part of the email using the below update statement:
|
1 2 3 4 5 |
UPDATE [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] SET EmployeeSet ='<Emp_Last_Name>RodriguezPhill</Emp_Last_Name><Emp_Address>177 Lilac Lane</Emp_Address><Emp_Email>khhnnzz.Phill@zwnht.org</Emp_Email>' WHERE ID =45531 |
If we retrieve that employee’s information after the update, in addition to the Emp_Last_Name and Emp_Email columns individually:
|
1 2 3 4 |
SELECT [ID],[Emp_First_Name],[Emp_Last_Name],[Emp_Email] ,[EmployeeSet] FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] where ID = 45531 |
The result will show you that, the single update statement we performed to that employee Column Set column is reflected on the Sparse Columns as follows:

The Column Set overrides the maximum number of Sparse Columns per each table, which is 1024 columns for each table. The Column Set can contain up to 30,000 Sparse Columns in your table. However, no more than 1024 columns can be returned in the result set at the same time and in the XML Column Set result.
Conclusion:
Sparse Column is a very efficient feature that can be used to store NULL values in a database table with a high NULL values percentage. Combining it with the filtered indexes will result in a performance enhancement to your queries and smaller non-clustered indexes. Together with the Column Set, Sparse Columns can be retrieved and modified in one shot, displayed in XML format and extends the number of columns per table limitation. Be careful when you use these features; as it is a double-edged sword; if you test it well and make sure that it will suit your case, you will get the best performance, otherwise it may cause performance degradation and consume your storage.
Useful Links:
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021