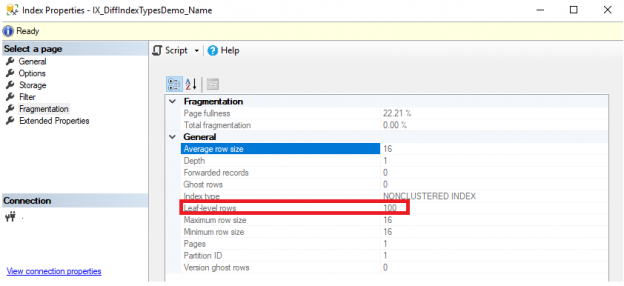
Introduction
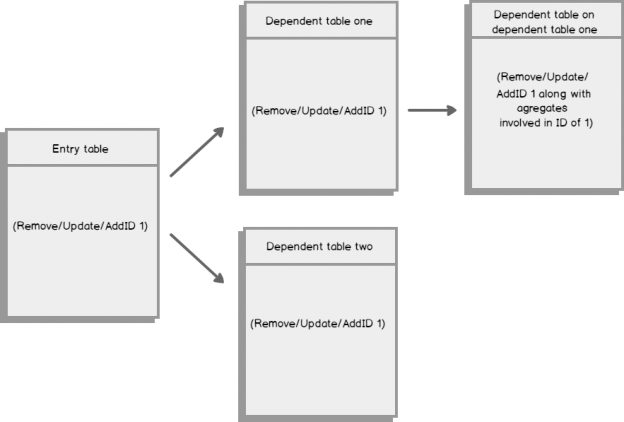
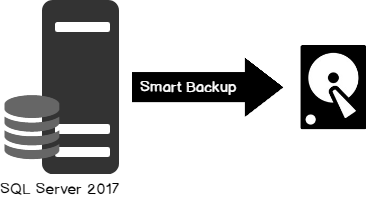
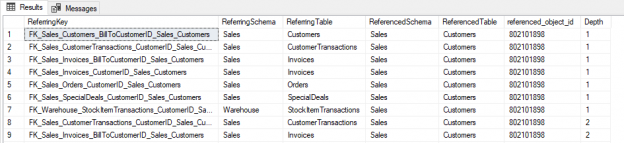
Foreign key constraints are a powerful mechanism for preserving referential integrity in a database. They can also represent a challenge when doing bulk table loads, since you need to find a “base” table to start with – that is, a table that has no foreign key constraints defined. Let’s label tables like this as level 0, or ground level if you like. Once that is loaded, you can begin to load other tables that have foreign key references to the base table. We can label those tables level 1, and so on. If you start with table data that already has referentially integrity and load tables by their level numbers — level 0, level 1, level 2 and so on – the load should proceed without problems. Let’s look at a simple example:
Read more »