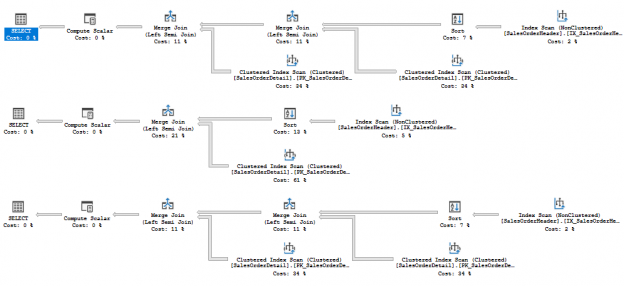
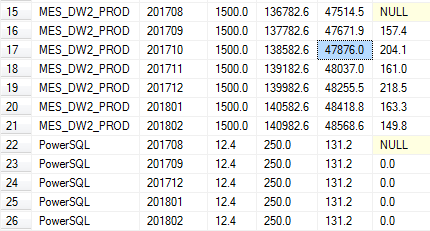
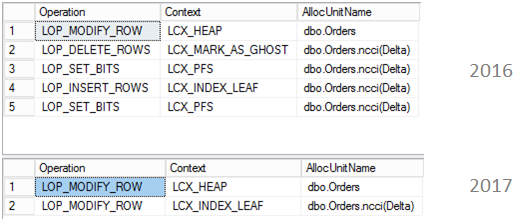
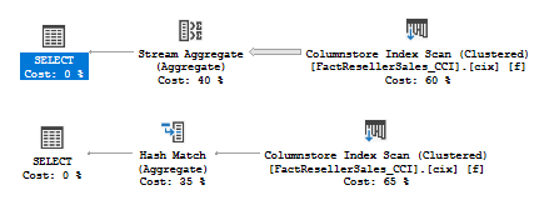
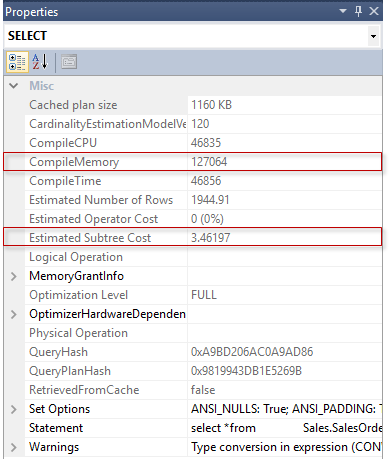
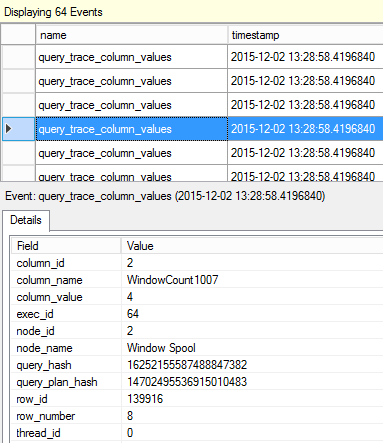
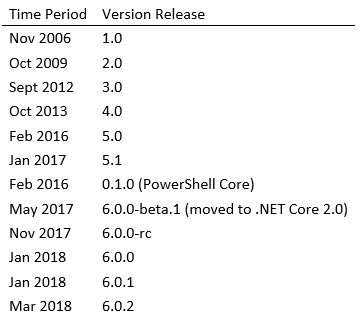
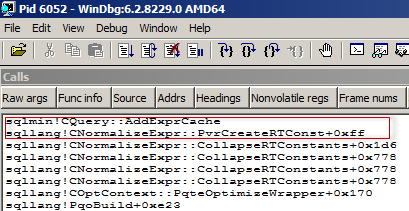
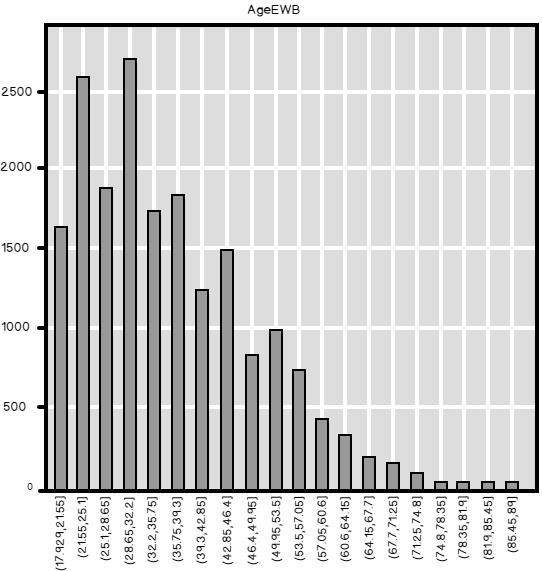
Description
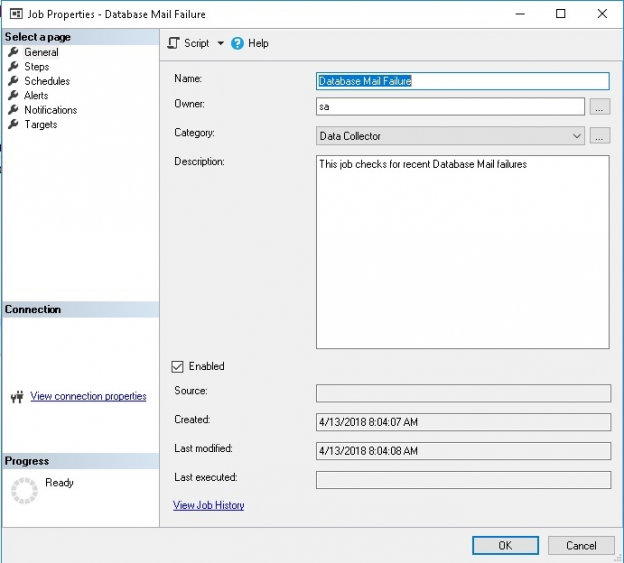
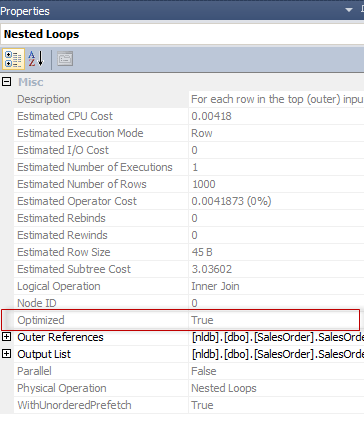
Database Mail is a convenient and easy way to send alerts, reports, or data from SQL Server. Failures are not obvious to the us though, and developing a process to monitor these failures alongside other failures will save immense headaches if anything ever goes wrong.
Database Mail: a (very) brief overview
Database Mail is a component of SQL Server that is available in every edition, except for Express. This feature is designed to be as simple as possible to enable, configure, and use.
Database Mail relies on SMTP to send emails via a specified email server to any number of recipients. When configuring, you provide a mail server, credentials (if needed), and then the service is ready to use. We’ll be focusing here on failure reporting and not configuration. If you need help setting up or configuring this feature, check out some of the references at the end of this article.
Read more »