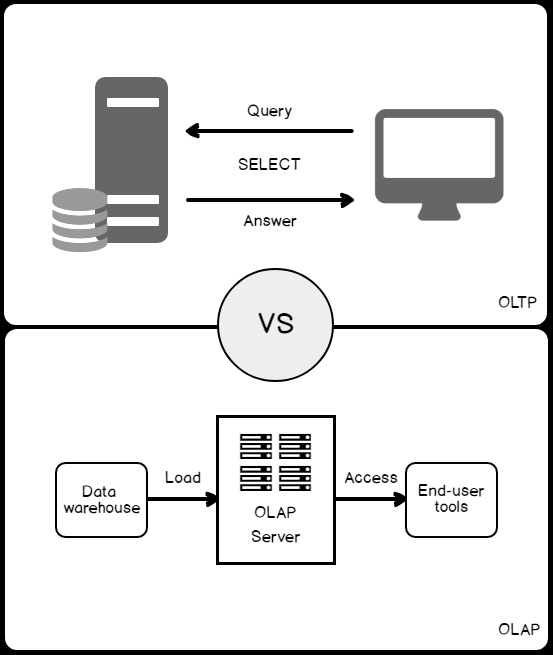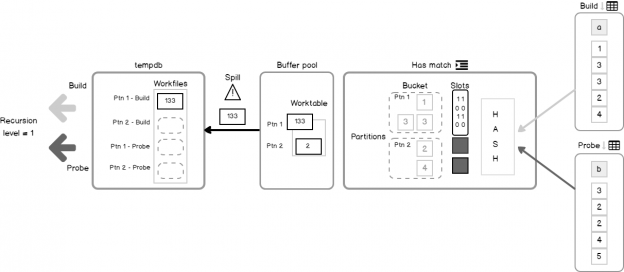
Some time ago, on the 24HOP Russia I was talking about the Query Processor internals and joins. Despite I had three hours, I felt the lack of time, and something left behind, because it is a huge topic, if you try to cover it in different aspects in details. With the few next articles, I’ll try to describe some interesting parts of my talk in more details. I will start with Hash Join execution internals.
The Hash Match algorithm is one of the three available algorithms for joining two tables together. However, it is not only about joining. You may observe a complete list of the logical operations that Hash Match supports in the documentation:
Read more »