
Description
SQL Server 2016 includes a variety of query optimizer enhancements. Some of these have existed since the first previews while others were added later. This is an opportunity to discuss, test out, and validate the behavior and benefits of these changes!
The Details
What follows is a feature-by-feature walkthrough, with some demos, explanations, and the implications of each change based on my testing and analysis. Some of these changes are very straightforward and do not require any real testing, but discussion is still worth the time and effort 🙂
Compatibility Level Guarantee
Any database may have its compatibility mode set to a previous (supported) version of SQL Server. This allows some level of backward compatibility between a newer version of SQL Server and an older one. By doing so, we can facilitate a smoother upgrade between versions, knowing that we are not immediately cutting the cord on all discontinued or altered features. Despite being in a compatibility mode, you can still take advantage of new SQL Server features, so long as they do not directly conflict with a feature of the older compatibility level you are using.
We can validate the current compatibility mode for any (or all) databases on a server via the sys.databases system view:
|
1 2 3 4 5 6 |
SELECT databases.name, databases.compatibility_level FROM sys.databases; |
The results are a list of databases and their associated compatibility mode. This is a nice quick way to verify if any databases have an old compatibility level, or are not at a desired version:
|
1 2 3 4 5 6 7 |
SELECT databases.name, databases.compatibility_level FROM sys.databases WHERE databases.compatibility_level <= 100 |
Running this on my local machine returns a single database that is running under SQL Server 2008R2 compatibility mode:

Compatibility mode may be updated using an ALTER DATABASE command, such as this:
|
1 2 3 4 |
ALTER DATABASE AdventureWorks2014 SET COMPATIBILITY_LEVEL = 130; |
This TSQL will adjust AdventureWorks2014 to use SQL Server 2016 compatibility.
Prior to SQL Server 2016, running a database in a previous version’s compatibility mode had no guarantees with regards to the behavior of the query optimizer and the executions plans it generated. Starting in SQL Server 2016, Microsoft guarantees that new query optimizer improvements will only be available in compatibility level 130. If you are running a database on a SQL Server 2016 server, but it is in an earlier compatibility mode, then no new optimizer features will be applied when queries are executed in your database.
This means that if you upgrade a server from SQL Server 2014 to 2016 and leave a database in compatibility level 120, then query plans will remain the same as they were on the old version. New optimizer features will only become available when the database is altered to utilize compatibility level 130.
Changes in Compatibility Level 130
What changes when you move to compatibility level 130? Here’s a brief list with a bit of detail:
MD2, MD4, MD5, SHA, and SHA1 hash algorithms are no longer supported. Use SHA2_256 or SHA2_512 instead.
A given table can now have 10,000 foreign keys or referential constraints. The limit used to be 253. That is a LOT of foreign keys!
Statistics sampling is now multi-threaded. All previous versions were single-threaded.
Trace flag 2371 is on by default, whereas in all previous versions it was off. This trace flag changes how automatically updating statistics determine when to update and how to update. Without it enabled, statistics would update when 20% of a table changed. For smaller tables, this is generally acceptable. For larger tables, it become untenable. The trace flag makes it so that statistics are auto-updated for a smaller % of change, starting at about 25k rows, which is ideal for very large tables. In SQL Server 2016, in addition to the trace flag being on, improvements have been made to which rows are sampled (leaning towards newer data). Lastly, auto-updating statistics will no longer block queries while running.
Batch mode is used by the optimizer for more operations in SQL Server 2016 than it was previously. This mode allows batches of rows to be operated on by a CPU, rather than one at a time. This greatly improves performance on large data sets, and can be very helpful in warehousing or other environments with massive amounts of data. Prior to SQL Server 2016, batch mode could be used with columnstore indexes, but its use was limited. In the new version, batch mode can be used for:
Sorts using columnstore indexes
Window function aggregation
Multiple distinct operators on columnstore indexes
Queries with serial plans, or those under maximum degree of parallelism = 1.
Cardinality estimation is improved, beyond those enhancements found in SQL Server 2014.
Queries on In-Memory OLTP tables can utilize parallel execution plans.
INSERT INTO…SELECT queries can be multi-threaded or benefit from a parallel execution plans.
These changes are almost exclusively enhancements—each improving how execution plans or statistics are managed or adding parallelism into plans that previously could not benefit from it. If you’re using old has algorithms that are discontinued in SQL Server 2016, be sure to transition to newer ones that are supported prior to upgrading your compatibility level.
Referential Integrity Operator
Foreign keys provide referential integrity between tables, ensuring that write operations on either do not render the related columns orphaned. Whenever a foreign key column is written, a check must occur of the referenced table to ensure the write operation doesn’t violate the foreign key definition.
In previous versions of SQL Server, this meant that scans or seeks would be performed against the parent table in order to validate a write operation, prior to it being committed. The specific operations required to validate the foreign key would be explicitly shown in the execution plan, for all referenced tables. In SQL Server 2016, the Foreign Key References Check is introduced to handle all referential integrity checks in a single step. Microsoft’s documentation indicates that this change will greatly simplify execution plans and reduce compilation time for the execution plan.
What does this mean for any existing keys and the queries that write to related columns? Let’s take a few minutes to run some tests and find out exactly how this new operator performs and compares to what we experienced in previous versions.
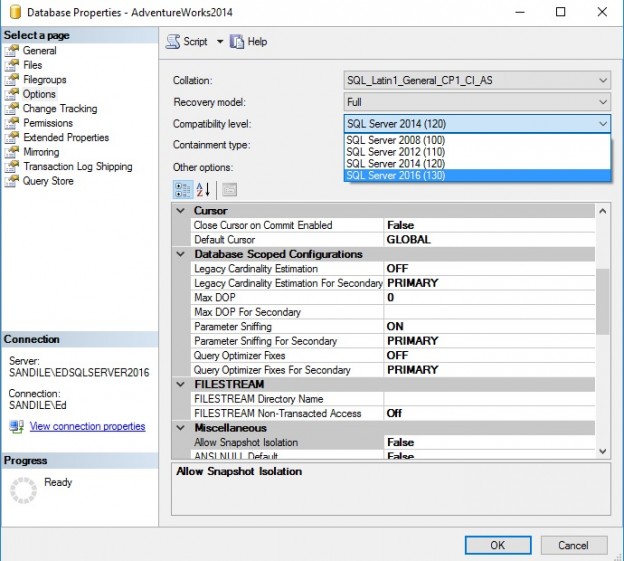
We’ll start with some simple updates on Production.Product (in AdventureWorks) under compatability mode 120, which indicates that we will use the optimizer rules taken from SQL Server 2014:
|
1 2 3 4 5 6 7 8 9 10 11 |
UPDATE Production.Product SET WeightUnitMeasureCode = 'LB', SizeUnitMeasureCode = 'LB' WHERE Product.ProductID = 919; UPDATE Production.Product SET WeightUnitMeasureCode = 'G', SizeUnitMeasureCode = 'CM ' WHERE Product.ProductID = 919 |
These updates each are affecting two foreign-keyed columns, both of which link back to Production.UnitMeasure. As a result, when we update them, it is necessary to validate referential integrity for each value added here:
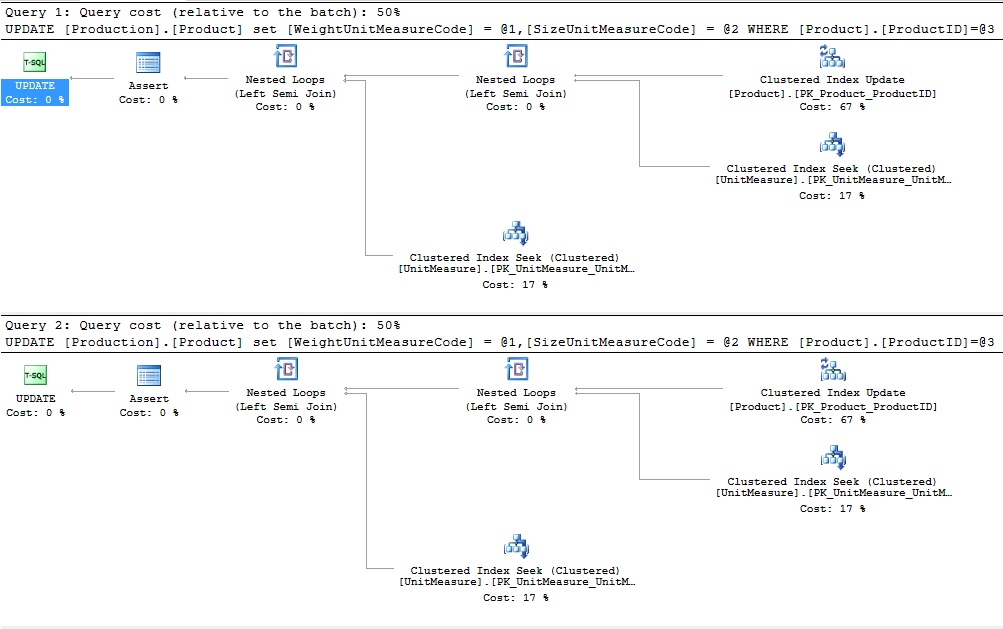
These plans each show that each individual update is check for a valid value in the parent table. Note that in the first update statement, we use the same value twice. Common sense would tell us that it should only be necessary to validate this once, but the optimizer will check Production.UnitMeasure twice anyway. These checks take the firm of the two clustered index seeks seen in each of the above execution plans.
With SQL Server 2016, we are promised a new operator that will make checks such as these more efficient and better documented. The latter is a useful point, as in large queries, it might not be immediately obvious which operators refer to a referential integrity check and not the active query itself.
Let’s update our compatibility mode to 130, which will allow the use of the new optimizer enhancements:
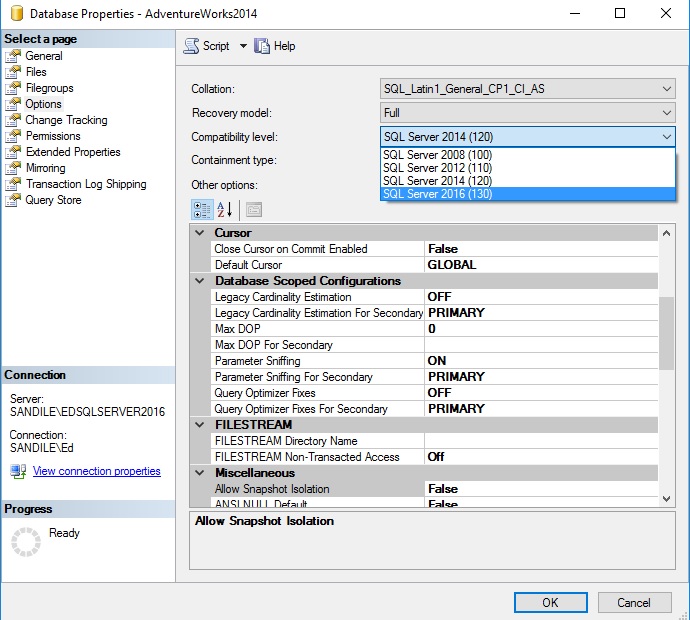
Now that we can make use of the new operator, let’s test it with one of our updates from above:
|
1 2 3 4 5 6 |
UPDATE Production.Product SET WeightUnitMeasureCode = 'LB', SizeUnitMeasureCode = 'LB' WHERE Product.ProductID = 919; |
The resulting execution plan is the same as earlier:
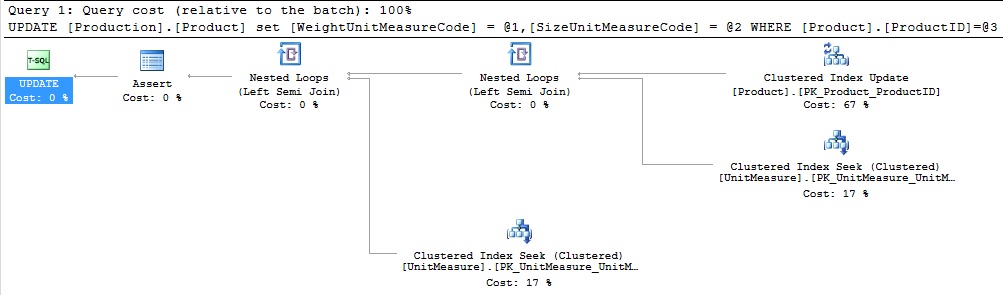
Well, that was uneventful. We hoped for a new, shiny plan operator and instead got exactly the same results as before. Let’s try a few other queries and see what changes we can uncover:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
INSERT INTO Production.Product ( Name ,ProductNumber ,MakeFlag ,FinishedGoodsFlag ,Color ,SafetyStockLevel ,ReorderPoint ,StandardCost ,ListPrice ,Size ,SizeUnitMeasureCode ,WeightUnitMeasureCode ,Weight ,DaysToManufacture ,ProductLine ,Class ,Style ,ProductSubcategoryID ,ProductModelID ,SellStartDate ,SellEndDate ,DiscontinuedDate ,rowguid ,ModifiedDate ) SELECT 'Wing Nut', 'WN-1234', 1, 0, 'Silver', 1000, 500, 1.00, 1.50, NULL, 'G', 'CM', NULL, 0, NULL, NULL, NULL, NULL, NULL, CAST(CURRENT_TIMESTAMP AS DATE), NULL, NULL, NEWID(), CURRENT_TIMESTAMP; DELETE FROM Production.Product WHERE Name = 'Wing Nut'; INSERT INTO production.UnitMeasure (UnitMeasureCode, Name, ModifiedDate) SELECT 'WOW', 'The wow factor!', CURRENT_TIMESTAMP; DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'WOW'; |
If updates don’t seem to get what we want, we should also try out some inserts and deletes. Running the above queries will add a row to Production.Product and Production.UnitMeasure, respectively, and then delete those rows. The resulting execution plans for the above queries are as follows:
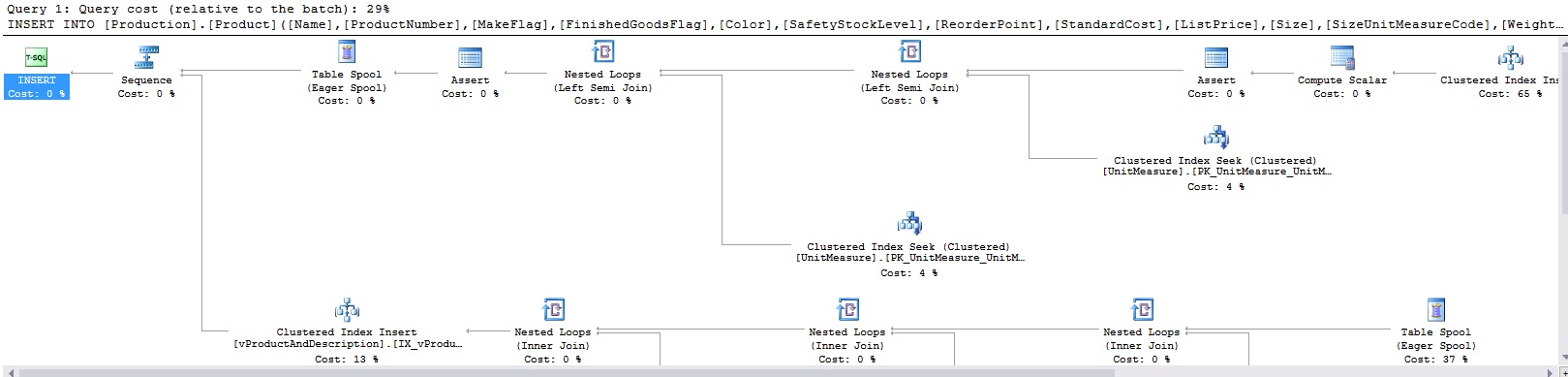

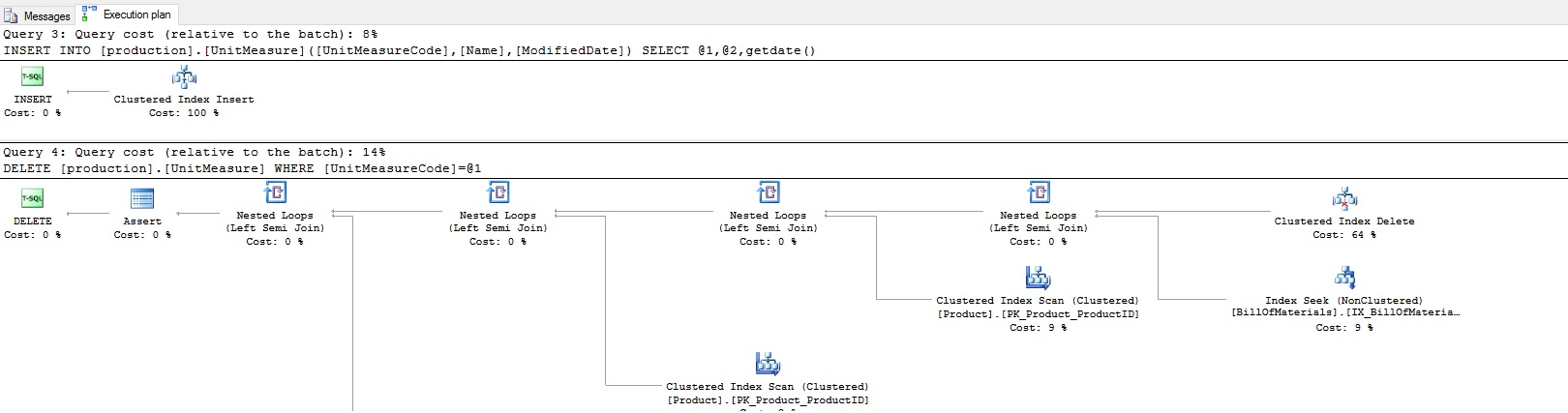
I didn’t bother to fit the entire plans into single images. It’s clear from the number of tables being queries above that we are not getting a clear foreign key operator, and are instead getting the same plans we’ve always gotten previously. What do we expect to see here? The following image is from an MSDN blog post:
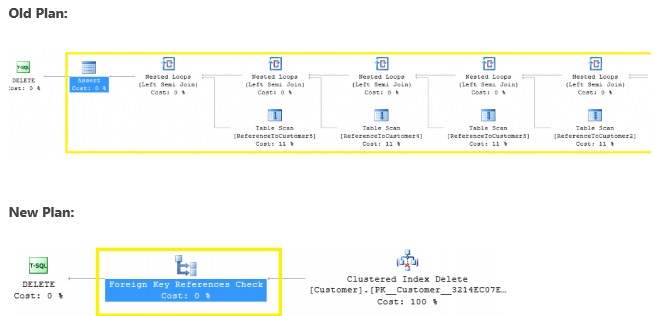
This shows clearly that the long string of referential integrity check scans/seek are replaced with a single simplified operator that presumably outperforms the previous methodology. The following TSQL is what they used to test this new operator:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE Customer(Id INT PRIMARY KEY, CustomerName NVARCHAR(128)); CREATE TABLE ReferenceToCustomer1(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); CREATE TABLE ReferenceToCustomer2(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); CREATE TABLE ReferenceToCustomer3(CustomerId INT FOREIGN KEY REFERENCES Customer(Id)); DELETE Customer WHERE Id = 1; |
The resulting execution plan I receive is the same as the old plan shown above. Since it is unclear why I am unable to get the desired results, I’ve left a note on the article to get more info on why this isn’t working. If there is some feature or setting I am missing, or if this operator is not yet available for the current RTM release, then it’ll be good to have that information to work with.
If an update on the new operator is received, either via the MSDN post or some other channel, I’ll update this article with the details.
The MSDN article referenced above can be found here
I had some high hopes for this change, being that the current execution plans used to enforce referential integrity tend to be rather unintelligent. To be sure, though, I installed a separate SQL Server 2016 instance on another computer, and ran the same queries from above. Results were the same in that I was unable to make use of the new plan operator. It’s possible this feature will become available in a future revision of SQL Server 2016, so I’ll keep an eye out, and if this feature becomes usable, I’ll be sure to document and test the heck out of it 🙂
Query Optimizer Hotfix/Service Pack Changes
In previous versions of SQL Server, when a hotfix or cumulative update was released, any query optimizer improvements bestowed by that update would not immediately go into effect. Instead, it was necessary to turn on trace flag 4199, which would then enable any new optimizer features originating from any installed updates to SQL Server.
This off-by-default methodology worked, but was a bit obfuscated and not clear to administrators that this was the intended behavior that they should work with. Often, patches would be installed, the trace flag not turned on, and thus no optimizer changes were realized until a major upgrade occurred. This is typically acceptable as we shouldn’t change optimizer behavior unless a problem exists that needs resolution, or if we upgrading to a new major version.
Starting with SQL Server 2016, all query optimizer improvements will be linked directly to compatibility level. If a database is upgraded to compatibility level 130, then all previous optimizations will be implemented. A database that is not in compatibility mode 130 will not receive optimizer enhancements from SQL Server 2016. Trace flag 4199 will be reserved for turning on any optimizer changes introduced in subsequent patches while still running the current version of SQL Server. If you were to upgrade to some future version of SQL Server, perhaps SQL Server 2018, then switching to the hypothetical 140 compatibility level would retroactively enable all optimizer enhancements introduced via hotfixes and service packs to SQL Server 2016.
Specific trace flags used to be used prior to trace flag 4199 for enabling query optimizer enhancements via an individual hotfix. This functionality was intended for scenarios where a distinct bug is in need of patching, and the enhancement needed as part of the fix. A variety of trace flags from 4101 – 4135 (non-inclusive) handled these specific hotfixes, which were no longer utilized after trace flag 4199 was created.
Conclusion
Each version of SQL Server comes with its share of query optimizer changes. Some are paired with new features, while others are intended to improve existing functionality. At least one of the new features, the foreign key referential integrity operator, isn’t available yet, but hopefully will make its appearance in a soon-to-be released revision.
The compatibility mode guarantee provides significantly more control over how new features affect the optimizer and ensures that upgrade processes can be better designed. The guaranteed knowledge of how features will behave provides a level of confidence that was not as easily available in previous versions of SQL Server.
Keep an eye out for more! It is not unheard of for Microsoft to release or document additional improvements in later service packs. These can be innocuous bug fixes or possibly cool new DMVs, optimizer enhancements, or feature additions!

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019