

In this article, we’ll discuss data type VARCHAR and query performance issues associated with utilizing the lower level VARCHAR data type. CHAR, VARCHAR and NVARCHAR are data types that support storing information in text format in a SQL Server database. These data types allow a wide assortment of character sets in the defined field or column in the database table.
The fundamental idea of NVARCHAR
NCHAR, NVARCHAR or NTEXT are similar to CHAR, VARCHAR OR TEXT, where the N prefix represents the International Language Character Set. The N-prefixed data types indicate that the resulting string could be comprised of a Unicode character set with variable length where each character occupies 2 bytes. Without the N prefix, the string could be converted to the default charset of the database but could result in certain special characters not being recognized as part of the International Language Character Set.
Today’s development platforms or their operating systems support the Unicode character set. Therefore, In SQL Server, you should utilize NVARCHAR rather than VARCHAR. If you do use VARCHAR when Unicode support is present, then an encoding inconsistency will arise while communicating with the database. This inconsistency causes query performance issues that eventually generate errors like blocking or a deadlock in SQL Server.
How can you recover from this query performance issue? Indexes can fail when an incorrect data type has been used within a column. In SQL Server, if an indexed VARCHAR column is presented with a Unicode N string, SQL Server won’t be able to make use of the index. A similar query performance issue occurs when an indexed column containing INTEGER data is presented with VARCHAR type data. We will talk about more examples below.
Imagine, that a SalesOrderHeader table has an AccountNumber column with VARCHAR data type and the total number of rows is 31,465. What will occur if we use prefix N before a string in a WHERE condition? Here, we will investigate a couple of query performance parameters on query execution, for example, logical reads, index utilization, execution time, etc.
VARCHAR column with N” prefix
|
1 2 3 4 5 |
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM SalesOrderHeader WHERE AccountNumber = N'10-4030-021815' |
Table ‘SalesOrderHeader’. Scan count 1, logical reads 114, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 16 ms.
The query results show the logical reads count is 114 and the scan count is 1 for the above statement. We have an index on the column where we have a filter applied, so we can check the index usage reading as shown below:

Here, the index is being scanned and the complete table is scanned to fetch the single row from the table. We can check the Actual Number of Rows (1) and Number of Rows Read (31465) parameters in the execution plan. We can see that we have an index on the column with the where clause, but that index isn’t being used. What is the reason for this?
One more parameter (CONVERT_IMPLICIT) is visible in the execution plan. CONVERT_IMPLICIT is a function that converts a column to the referenced data type in the function. In this way, in Predicate, we can see that the column is converted to NVARCHAR before comparing it with the input value. Also, this explains the index not being used for this query because the index will not get seek when a column used with any function in Where clause.
VARCHAR column without N” prefix
|
1 2 3 4 5 |
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM SalesOrderHeader WHERE AccountNumber = '10-4030-021815' |
SQL Server parse and compile time: CPU time = 12 ms, elapsed time = 12 ms. (1 row affected) Table ‘SalesOrderHeader’. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
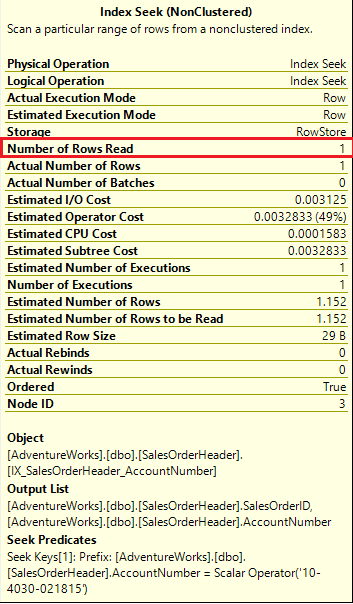
In this query, the only difference from the previous one is that we have removed N from the Where clause, and the read count is just 5. In the execution plan shown below, we can see that the index over the column is getting a seek. The Actual Number of Rows, Estimated Number of Rows, Estimated Number of Rows to be Read and Number of Rows Read is 1 are visible in the execution plan. So, it makes sense not to use N with the VARCHAR data type:

The above result-set and clarifications are for SELECT statements only;
Session: 1
Here, we are starting a transaction and deleting one row on the SalesOrderHeader table with a filter on the AccountNumber column. As shown in the above statement, the SELECT query is scanning the full table when we used N prefix with the VARCHAR type column:
|
1 2 3 |
BEGIN TRAN DELETE FROM SalesOrderHeader WHERE AccountNumber = N'10-4030-021815' --COMMIT |
We didn’t commit this transaction to check some query performance issues.
Session: 2
Here, we are starting another transaction in SQL Server and deleting one row other than the row from session one. At the point when we start the execution of a statement, execution isn’t getting finished:
|
1 2 3 4 |
BEGIN TRAN DELETE FROM SalesOrderHeader WHERE AccountNumber = '10-4030-017122' |

Let’s monitor the SQL session stats with the help of DMVs:
|
1 2 3 |
SELECT sys.fn_PhysLocFormatter(%%physloc%%), * FROM SalesOrderHeader WHERE AccountNumber IN ('10-4030-017122', '10-4030-021815') |
We can see that session two exists with session_id: 68 in SQL Server and it is getting blocked by session_id: 67, which is session one.
The session with the id: 67 won’t be visible in sys.dm_exec_requests DMV, because execution is finished, however not committed or rolled back. We can use the DBCC command to identify the statement which is making trouble:
|
1 |
DBCC INPUTBUFFER (67) |

So, we are deleting the row from the table, we have an index on the column and we are using the same column in the WHERE clause in a T-SQL statement. However, it set an exclusive lock on the table until COMMIT or ROLLBACK. In the subsequent session, we don’t use prefix ‘N’ in the WHERE clause, yet the first T-SQL statement has produced blocking and not ready to release the sessions in a blocking chain.
Conclusion
Data types can vary between various database systems; each database has somewhat different data types and VARCHAR doesn’t mean the same thing across databases. SQL Server has VARCHAR and NVARCHAR, but mixed data types can cause query performance issues that are difficult to troubleshoot and investigate. The takeaway message is not to use prefix N with the VARCHAR data type in SQL Server to avoid query performance issues.
See more
Check out SpotLight, a free, cloud based SQL Server monitoring tool to easily detect, monitor, and solve SQL Server performance problems on any device


View all posts by Jignesh Raiyani
- Page Life Expectancy (PLE) in SQL Server - July 17, 2020
- How to automate Table Partitioning in SQL Server - July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 - July 6, 2020