
Background
Running totals have long been the core of most financial systems, be statements or even balance calculations at a given point in time. Now it’s not the hardest thing to do in SQL Server but it is definitely not the fastest thing in the world either as each record has to be evaluated separately. Prior to SQL Server 2012, you have to manually define the window/subset in which you want to calculate you running total, normally we would define a row number with a window on a specific order or a customer depending on the requirements at hand.
Discussion
I was tasked with rewriting a piece of old C# code that we have in our system in SQL as it was no longer performing optimally. The data requirements grew too fast for the system to be able to keep up. The piece of code was responsible for generating transactional statements that would go out to customers every night on request. One of the requirements, in the statement, was to build a running total in the statement to make it easier for customers to reconcile their transactions in question at any given time. So I started looking at my options and found there are a couple of ways for us to create running totals in SQL Server, so I started testing all the methods I can think off and find online. With performance in mind, I tried to make sure I got the best/fastest solution to my problem. I know from previous experiences that using windowed functions to help with these calculations is usually the fastest, but I had 2 big issues as the first part of the statement would run on SQL Server 2008R2 and the second objective I had in mind is to run this of our APS (You can read more on what an APS is and how it works here).
Considerations
Prior to SQL Server 2012 running totals a not a pretty thing to do in SQL, it is not hard but slow. Always test everything a DEV or UAT if you are lucky enough to have proper testing environments.
Prerequisites
- SQL Server 2008+ or SQL Server 2012+ (If you want to use the windowed method)
- AdventureWorks Sample Database (If you want to follow the examples in the article)
Objective
We will be using the AdventureWorks sample database to go through a few methods of creating running totals in SQL Server and by doing this looking at what the best option for our environment would be.
Solution
My first thought was to us a subquery to create my running total as this would make sense to calculate the value of the running total at execution time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--SubQuery SELECT SalesOrderID , SalesOrderDetailID , LineTotal , ( SELECT SUM(y.LineTotal) FROM Sales.SalesOrderDetail y WHERE y.SalesOrderID = x.SalesOrderID AND y.SalesOrderDetailID <= x.SalesOrderDetailID ) AS RunningTotal FROM Sales.SalesOrderDetail x ORDER BY 1 ,2 ,3; |
Now as we can see from the above screenshot of the result set this work perfectly, but I cannot just look at one option as I need to make sure it is as optimised as possible to ensure business continuity. So what if we did a self-join and join the table to itself with an offset and then used this as a way to get a running total working and would this be faster as I can control the indexing better to ensure the performance is better than the subquery method.
So let’s see how to this will work and will it be more effective.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--Self Join SELECT x.SalesOrderID , x.SalesOrderDetailID , x.LineTotal , SUM(y.LineTotal) AS RunningTotal FROM Sales.SalesOrderDetail x JOIN Sales.SalesOrderDetail y ON y.SalesOrderID = x.SalesOrderID AND y.SalesOrderDetailID <= x.SalesOrderDetailID GROUP BY x.SalesOrderID , x.SalesOrderDetailID , x.LineTotal ORDER BY 1, 2, 3; |
And what do you know, it works and the results set is the exact same as we would have hoped. The big question now is, is it really better than the subquery method? So let’s pull out the execution plan and compare the two together.

By looking only at the relative to batch percentages we can immediately see that the subquery method used 54% of the batch resources and the self-join only 46%. So now let’s see if we can improve on this even further.
I was thinking of how I could use the recursive nature of a CTE to create a running total. So the below code will be using a recursive CTE to add the “LineTotal” to itself the whole time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
WITH CTE AS ( SELECT SalesOrderID , SalesOrderDetailID , LineTotal , RunningTotal = LineTotal FROM Sales.SalesOrderDetail WHERE SalesOrderDetailID IN ( SELECT MIN(SalesOrderDetailID) FROM Sales.SalesOrderDetail GROUP BY SalesOrderID ) UNION ALL SELECT y.SalesOrderID , y.SalesOrderDetailID , y.LineTotal , RunningTotal = x.RunningTotal + y.LineTotal FROM CTE x JOIN Sales.SalesOrderDetail y ON y.SalesOrderID = x.SalesOrderID AND y.SalesOrderDetailID = x.SalesOrderDetailID + 1 ) SELECT * FROM CTE ORDER BY 1 , 2 , 3 OPTION ( MAXRECURSION 10000 ); |
And again we get the same results, but only this time if we have a look at the execution plan for all three of the methods we have tested we see something very interesting.
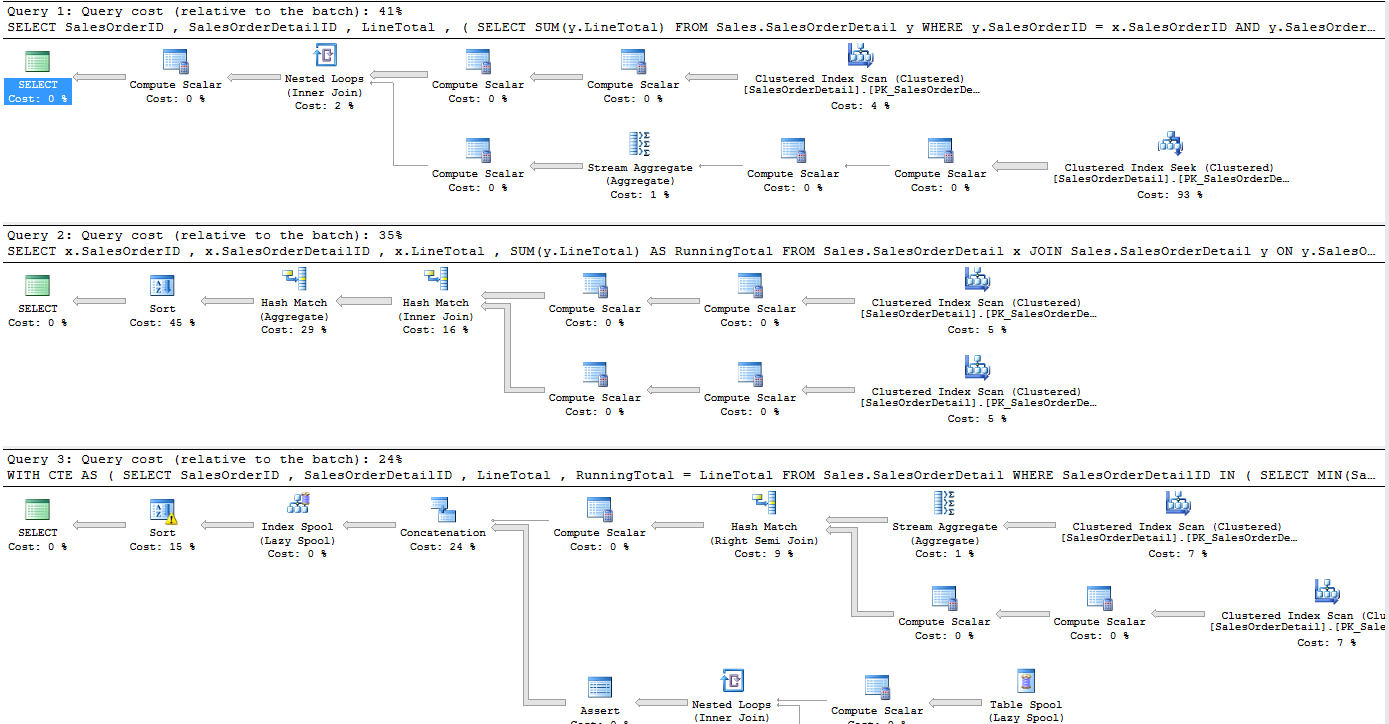
Now we can see that the recursive CTE is way faster than the other two methods so clearly we have a winner. Or do we? Firstly to allow the CTE to be used in this way we have to increase the MAXRECURSION option for this query, and the max we are allowed to set it to is 32767. In my use case, I would not ever come close to this number ever as no statement ever have this many records in, but if you are running this on big data sets you would not be able to go with this method. And secondly, when I tested it on our APS, it yells at me for even thinking I can do a recursive CTE on it. So then in my production environment on SQL Server 2008R2 I can use this method, but in our data warehousing environment, I need to use one of the other two methods.
Now if you are lucky enough to run SQL Server 2012+ (as most of us should be doing), Microsoft improved on the Windowed functions and thus we have a far superior method that we can use. Using windowed functions in this is faster and easier to read when you have to hand down your code to someone else to support or change.
|
1 2 3 4 5 6 7 8 9 10 11 |
--SQL2012+ SELECT SalesOrderID , SalesOrderDetailID , LineTotal , SUM(LineTotal) OVER ( PARTITION BY SalesOrderID ORDER BY SalesOrderDetailID ) AS RunningTotal FROM Sales.SalesOrderDetail ORDER BY 1 , 2 , 3; |
If we have a look at the execution plan now, only comparing the recursive CTE to the Windowed function method, we can clearly see that the recursive CTE is no match for the Windowed function.

Looking at the relative to batch again we can see that the recursive CTE now use 91% compared to the windowed function method of 9%.
Final thoughts
If you know your data and the requirement well, I would use the recursive CTE method in environments pre-SQL Server 2012 and the Windowed functions in SQL Server 2012 and later. I also think that a CLR might be useful in this scenario, but my C# skills is a bit rusty at the moment. Maybe with the help of the community, I can test this idea.
References

Jean-Pierre speaks at the Johannesburg SQL User Group, trying to give back to the SQL community as much as possible. He loves to tinker with SQL Server and see how he can approach a problem with a different angle.
View all posts by Jean-Pierre Voogt
- Running with running totals in SQL Server - July 29, 2016
- The new SQL Server 2016 sample database - July 22, 2016
- Storing Twitter feeds with Microsoft Flow in Azure SQL Database - June 29, 2016