
The need to search through database schema for specific words or phrases is commonplace for any DBA. The ability to do so quickly, accurately, and completely is critical when developing new features, modifying existing code, or cleaning up the vestiges from an application’s ancient history.
After introducing how to effectively search catalog views in the previous article, here we will brings everything together, merging the many scripts that we previous wrote into a single search tool. While the resulting TSQL is big, it is ultimately the sum of the many building blocks we have already tested successfully. The final script can be copied and used on any server where you’re looking for specific metadata.
Review of Purpose
Before diving further into this search script, it’s worthwhile to take a moment and review why we are doing this, and some of the common use cases for it. Searching SQL Server is very common, and doesn’t just accompany the needs of a curious DBA. The most frequent scenarios where a script like this has been valuable to me include:
- A software release is altering database schema and I want to verify that no related objects also need to be changed.
- Code reviewing release scripts that involve the altering or removal of existing schema.
- Database or object migrations, in which all referencing schema must be updated with the new location.
- Verifying that an object is unused and can be dropped.
- A major application upgrade is revamping a significant portion of code, requiring extensive database research.
- …and of course, the needs of a curious DBA 🙂
There are many other reasons why we would want to search SQL Server for schema or objects, so feel free to add yours to the list!
Bringing it All Together
We’ve explored a wide variety of system views and metadata sources in order to build methods of searching a majority of objects within SQL Server. Running each of those queries one-at-a-time is inconvenient, and our stated goal was to build a single script that would do everything for us. Once complete, we can save this super-script as a SQL file or as a snippet within Management Studio for quick retrieval in the future.
How do we combine so many different data sets into one, and how do we structure our search script to do everything we want it to? It’s helpful when building something big to sketch out our design plan so that we have some direction when we begin to pour forth pages of TSQL. Here is my vision for our search solution:
- Define our search string and save it to a parameter for reuse in the future. Define parameters that will control how and what we search for.
- Create a temporary table to store all of our collected data as we start to return a variety of result sets.
- Create a list of databases that we want to search. By default, I’ll search all databases (system and user).
- Collect all server-level objects and insert them into the temp table.
- Iterate through all databases listed above and return result sets from each for all database-level objects into our temp table.
- Return the final data set, including metadata from both server and database objects.
Since our result sets vary greatly depending on the type of metadata being collected, our temp table will have some extra columns that may or may not be used for each object type. I find this preferable to returning twenty different data sets as the single unified table of results is easier to copy, export, or otherwise manipulate once its returned.
Let’s get started! Our first steps are to define any variables we are going to use throughout the search, create a configuration section, and create our temp table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SET NOCOUNT ON; ---------------------------------------------------------------------------------------------------------------------------------------- --------------------------------------------Configure Search Here----------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------------------- DECLARE @search_string NVARCHAR(MAX) = 'Department'; DECLARE @search_SSRS BIT = 1; DECLARE @search_SSIS_MSDB BIT = 1; DECLARE @search_SSIS_disk BIT = 0; DECLARE @pkg_directory NVARCHAR(MAX) = 'C:\SSIS_Packages'; ---------------------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------------------- SET @search_string = '%' + @search_string + '%'; DECLARE @sql_command NVARCHAR(MAX); DECLARE @database_name NVARCHAR(MAX); DECLARE @database TABLE (database_name NVARCHAR(MAX), is_online BIT); IF EXISTS (SELECT * FROM tempdb.sys.tables WHERE name = '#object_data') BEGIN DROP TABLE #object_data; END CREATE TABLE #object_data ( server_name NVARCHAR(MAX) NULL, database_name NVARCHAR(MAX) NULL, schema_name NVARCHAR(MAX) NULL, table_name SYSNAME NULL, column_name SYSNAME NULL, objectname SYSNAME NULL, step_name NVARCHAR(MAX) NULL, object_description NVARCHAR(MAX) NULL, object_definition NVARCHAR(MAX) NULL, key_column_list NVARCHAR(MAX) NULL, include_column_list NVARCHAR(MAX) NULL, xml_content XML NULL, text_content NVARCHAR(MAX) NULL, enabled BIT NULL, status NVARCHAR(MAX) NULL, object_type NVARCHAR(50) NULL); INSERT INTO @database (database_name, is_online) SELECT databases.name, CASE WHEN databases.state = 0 THEN 1 ELSE 0 END AS is_online FROM sys.databases; |
We set the transaction isolation level to READ UNCOMMITTED for this proc. While it is unlikely to cause any unwanted contention, there is the chance it could interfere with any other procs out there that happen to be accessing any of these system vies. In the configuration section, we define @search_string, which is the text we will be searching our server for, as well as bits that control whether or not we want to search SSIS or SSRS. In we are searching SSIS packages on disk (@search_SSIS_disk = 1), then be sure to also populate @pkg_directory with a valid folder on disk. Note that wildcards are added to the beginning and end of the search criteria we enter. This ensures that we search for all objects containing the text, and not just those beginning in, or equal to that text. Since the metadata tables we are searching are relatively small, the cost of doing this is acceptable for the functionality we gain.
Our #object_data temp table has columns for everything we could possibly return. This means that for any given search, some columns will be NULL. This is by design, and reduces the confusion that may arise by trying to reuse columns for data that doesn’t quite match their names or definitions. Feel free to modify this table or how the result sets are stored if your environment is better served by a different column list/order/definition.
Lastly, we populate the @database table, which will be used later on when we iterate through each database on the server to collect database metadata.
With the housekeeping out of the way, we can move on to collecting server-level metadata using some of the queries we defined previously. Each search task is broken into a separate insert into #object_data, and only populating whatever columns are needed by it. The following TSQL will insert into our temp table all of the metadata about jobs, databases, logins, linked servers, server triggers, SSRS, and SSIS. As per the control bits we created at the start of this proc, SSRS and SSIS will only be searched if they are set to 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 |
-- Jobs INSERT INTO #object_data (server_name, objectname, object_description, enabled, object_type) SELECT sysservers.srvname AS server_name, sysjobs.name AS objectname, sysjobs.description AS object_description, sysjobs.enabled, 'SQL Agent Job' AS object_type FROM msdb.dbo.sysjobs INNER JOIN master.dbo.sysservers ON srvid = originating_server_id WHERE sysjobs.name LIKE @search_string OR sysjobs.description LIKE @search_string; -- Job Steps INSERT INTO #object_data (server_name, objectname, step_name, object_description, object_definition, enabled, object_type) SELECT s.srvname AS server_name, sysjobs.name AS objectname, sysjobsteps.step_name, sysjobs.description AS object_description, sysjobsteps.command AS object_definition, sysjobs.enabled, 'SQL Agent Job Step' FROM msdb.dbo.sysjobs INNER JOIN msdb.dbo.sysjobsteps ON sysjobsteps.job_id = sysjobs.job_id INNER JOIN master.dbo.sysservers s ON s.srvid = sysjobs.originating_server_id WHERE sysjobsteps.command LIKE @search_string OR sysjobsteps.step_name LIKE @search_string; -- Databases INSERT INTO #object_data ( objectname, object_type) SELECT databases.name AS objectname, 'Database' AS object_type FROM sys.databases WHERE databases.name LIKE @search_string; -- Logins INSERT INTO #object_data (objectname, object_type) SELECT syslogins.name AS objectname, 'Server Login' AS object_type FROM sys.syslogins WHERE syslogins.name LIKE @search_string; -- Linked Servers INSERT INTO #object_data (objectname, object_definition, object_type) SELECT servers.name AS objectname, servers.data_source AS object_definition, 'Linked Server' AS object_type FROM sys.servers WHERE servers.name LIKE @search_string OR servers.data_source LIKE @search_string; -- Server Triggers INSERT INTO #object_data (objectname, object_description, object_definition, object_type) SELECT server_triggers.name AS objectname, parent_class_desc AS object_description, server_sql_modules.definition AS object_definition, 'Server Trigger' AS object_type FROM sys.server_triggers INNER JOIN sys.server_sql_modules ON server_triggers.object_id = server_sql_modules.object_id WHERE server_triggers.name LIKE @search_string OR server_sql_modules.definition LIKE @search_string; -- Reporting Services IF EXISTS (SELECT * FROM sys.databases WHERE databases.name = 'ReportServer') AND @search_SSRS = 1 BEGIN INSERT INTO #object_data (objectname, object_definition, xml_content, text_content, object_type) SELECT Catalog.Name AS objectname, Catalog.Path AS object_definition, CONVERT(XML, CONVERT(VARBINARY(MAX), Catalog.content)) AS xml_content, CONVERT(NVARCHAR(MAX), CONVERT(XML, CONVERT(VARBINARY(MAX), Catalog.content))) AS text_content, CASE Catalog.Type WHEN 1 THEN 'SSRS Folder' WHEN 2 THEN 'SSRS Report' WHEN 3 THEN 'SSRS Resource' WHEN 4 THEN 'SSRS Linked Report' WHEN 5 THEN 'SSRS Data Source' WHEN 6 THEN 'SSRS Report Model' WHEN 7 THEN 'SSRS Report Part' WHEN 8 THEN 'SSRS Shared Dataset' ELSE 'SSRS Unknown' END AS object_type FROM reportserver.dbo.Catalog LEFT JOIN ReportServer.dbo.Subscriptions ON Subscriptions.Report_OID = Catalog.ItemID WHERE Catalog.Path LIKE @search_string OR Catalog.Name LIKE @search_string OR CONVERT(NVARCHAR(MAX), CONVERT(XML, CONVERT(VARBINARY(MAX), Catalog.content))) LIKE @search_string OR Subscriptions.DataSettings LIKE @search_string OR Subscriptions.ExtensionSettings LIKE @search_string OR Subscriptions.Description LIKE @search_string; INSERT INTO #object_data (object_description, object_definition, text_content, status, object_type) SELECT Subscriptions.Description AS object_description, Subscriptions.ExtensionSettings AS object_definition, Subscriptions.DeliveryExtension AS text_content, Subscriptions.LastStatus AS status, 'SSRS Subscription' AS object_type FROM ReportServer.dbo.Subscriptions WHERE Subscriptions.ExtensionSettings LIKE @search_string OR Subscriptions.Description LIKE @search_string OR Subscriptions.DataSettings LIKE @search_string; END IF @search_SSIS_MSDB = 1 BEGIN WITH CTE_SSIS AS ( SELECT pf.foldername + '\'+ p.name AS full_path, CONVERT(XML,CONVERT(VARBINARY(MAX),packagedata)) AS package_details_XML, CONVERT(NVARCHAR(max), CONVERT(XML,CONVERT(VARBINARY(MAX),packagedata))) AS package_details_text, 'SSIS Package (MSDB)' AS object_type FROM msdb.dbo.sysssispackages p INNER JOIN msdb.dbo.sysssispackagefolders pf ON p.folderid = pf.folderid) INSERT INTO #object_data (object_description, xml_content, text_content, object_type) SELECT full_path AS object_description, package_details_XML AS xml_content, package_details_text AS text_content, object_type FROM CTE_SSIS WHERE CTE_SSIS.package_details_text LIKE @search_string OR CTE_SSIS.full_path LIKE @search_string; END IF @search_SSIS_disk = 1 BEGIN CREATE TABLE ##ssis_data ( full_path NVARCHAR(MAX), package_details_XML XML, package_details_text NVARCHAR(MAX) ); DECLARE @ssis_package_name NVARCHAR(MAX); SELECT @sql_command = 'dir "' + @pkg_directory + '" /A-D /B /S '; INSERT INTO ##ssis_data (full_path) EXEC Xp_cmdshell @sql_command; DECLARE SSIS_CURSOR CURSOR FOR SELECT full_path FROM ##ssis_data; OPEN SSIS_CURSOR; FETCH NEXT FROM SSIS_CURSOR INTO @ssis_package_name; WHILE @@FETCH_STATUS = 0 BEGIN SELECT @sql_command = 'WITH CTE_SSIS_PACKAGES AS ( SELECT ''' + @ssis_package_name + ''' AS full_path, CONVERT(XML, SSIS_PACKAGE.bulkcolumn) AS package_details_XML FROM OPENROWSET(BULK ''' + @ssis_package_name + ''', single_blob) AS SSIS_PACKAGE) UPDATE SSIS_DATA SET package_details_XML = CTE_SSIS_PACKAGES.package_details_XML FROM CTE_SSIS_PACKAGES INNER JOIN ##ssis_data SSIS_DATA ON CTE_SSIS_PACKAGES.full_path = SSIS_DATA.full_path;' FROM ##ssis_data; EXEC (@sql_command); FETCH NEXT FROM SSIS_CURSOR INTO @ssis_package_name; END CLOSE SSIS_CURSOR; DEALLOCATE SSIS_CURSOR; UPDATE SSIS_DATA SET package_details_text = CONVERT(NVARCHAR(MAX), SSIS_DATA.package_details_XML) FROM ##ssis_data SSIS_DATA; INSERT INTO #object_data (object_description, xml_content, text_content, object_type) SELECT full_path AS object_description, package_details_XML AS xml_content, package_details_text AS text_content, 'SSIS Package (File System)' AS object_type FROM ##ssis_data SSIS_DATA WHERE SSIS_DATA.package_details_text LIKE @search_string OR SSIS_DATA.full_path LIKE @search_string; DROP TABLE ##ssis_data; END |
The queries used throughout this TSQL are very similar, if not identical to the ones we created previously. Our only significant changes are to insert all results into our temp table, and to search using @search_string, rather than any hard-coded criteria. When this TSQL is complete, we’ll have all server metadata in our temp table, ready to be returned later on when we have collected the rest of our search results.
Our next step is to iterate through each database on our server and check for database metadata matching our search criteria. This is a bit trickier as we cannot utilize the USE operator without also using dynamic SQL. In order to query each database with all of the various searches we defined earlier, we will need to declare a dynamic SQL statement for each database, execute it, and make sure the results of each iteration of the loop end up in our temporary table.
As is the case when converting standard TSQL to dynamic SQL, we will need to replace all single apostrophes with a pair of apostrophes. In an effort to keep this as simple as possible, I have left all TSQL searches from above exactly as they were. The only changes are the aforementioned additional apostrophes, as well as the use of INSERT statements to collect our data for easy retrieval later on. The following is the result of this work:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 |
-- Iterate through databases to retrieve database object metadata DECLARE DBCURSOR CURSOR FOR SELECT database_name FROM @database WHERE is_online = 1; OPEN DBCURSOR; FETCH NEXT FROM DBCURSOR INTO @database_name; WHILE @@FETCH_STATUS = 0 BEGIN SELECT @sql_command = ' USE [' + @database_name + ']; -- Tables INSERT INTO #object_data (database_name, schema_name, table_name, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, tables.name AS table_name, ''Table'' AS object_type FROM sys.tables INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE tables.name LIKE ''' + @search_string + '''; -- Columns INSERT INTO #object_data (database_name, schema_name, table_name, column_name, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, tables.name AS table_name, columns.name AS column_name, ''Column'' AS object_type FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE columns.name LIKE ''' + @search_string + '''; -- Schemas INSERT INTO #object_data (database_name, schema_name, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, ''Schema'' AS object_type FROM sys.schemas WHERE schemas.name LIKE ''' + @search_string + '''; -- Synonyms INSERT INTO #object_data (database_name, objectname, object_definition, object_type) SELECT db_name() AS database_name, synonyms.name AS objectname, synonyms.base_object_name AS object_definition, ''Synonym'' AS object_type FROM sys.synonyms WHERE synonyms.name LIKE ''' + @search_string + ''' OR synonyms.base_object_name LIKE ''' + @search_string + '''; -- Indexes INSERT INTO #object_data (database_name, table_name, objectname, object_type) SELECT db_name() AS database_name, tables.name AS table_name, indexes.name AS objectname, ''Index'' AS object_type FROM sys.indexes INNER JOIN sys.tables ON tables.object_id = indexes.object_id WHERE indexes.name LIKE ''' + @search_string + '''; -- Index Columns WITH CTE_INDEX_COLUMNS AS ( SELECT db_name() AS database_name, TABLE_DATA.name AS table_name, INDEX_DATA.name AS index_name, STUFF(( SELECT '', '' + columns.name FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 0 ORDER BY index_columns.key_ordinal FOR XML PATH('''')), 1, 2, '''') AS key_column_list, STUFF(( SELECT '', '' + columns.name FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 1 ORDER BY index_columns.key_ordinal FOR XML PATH('''')), 1, 2, '''') AS include_column_list, ''Index Column'' AS object_type FROM sys.indexes INDEX_DATA INNER JOIN sys.tables TABLE_DATA ON TABLE_DATA.object_id = INDEX_DATA.object_id) INSERT INTO #object_data (database_name, table_name, objectname, key_column_list, include_column_list, object_type) SELECT database_name, table_name, index_name, key_column_list, ISNULL(include_column_list, '''') AS include_column_list, object_type FROM CTE_INDEX_COLUMNS WHERE CTE_INDEX_COLUMNS.key_column_list LIKE ''' + @search_string + ''' OR CTE_INDEX_COLUMNS.include_column_list LIKE ''' + @search_string + '''; -- Service Broker Queues INSERT INTO #object_data (database_name, objectname, object_type) SELECT db_name() AS database_name, name AS objectname, ''Queue'' AS object_type FROM sys.service_queues WHERE service_queues.name LIKE ''' + @search_string + '''; -- Foreign Keys INSERT INTO #object_data (database_name, schema_name, table_name, objectname, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, objects.name AS table_name, foreign_keys.name AS objectname, ''Foreign Key'' AS object_type FROM sys.foreign_keys INNER JOIN sys.schemas ON foreign_keys.schema_id = schemas.schema_id INNER JOIN sys.objects ON objects.object_id = foreign_keys.parent_object_id WHERE foreign_keys.name LIKE ''' + @search_string + '''; -- Foreign Key Columns WITH CTE_FOREIGN_KEY_COLUMNS AS ( SELECT parent_schema.name AS parent_schema, parent_table.name AS parent_table, referenced_schema.name AS referenced_schema, referenced_table.name AS referenced_table, foreign_keys.name AS foreign_key_name, STUFF(( SELECT '', '' + referencing_column.name FROM sys.foreign_key_columns INNER JOIN sys.objects ON objects.object_id = foreign_key_columns.constraint_object_id INNER JOIN sys.tables parent_table ON foreign_key_columns.parent_object_id = parent_table.object_id INNER JOIN sys.schemas parent_schema ON parent_schema.schema_id = parent_table.schema_id INNER JOIN sys.columns referencing_column ON foreign_key_columns.parent_object_id = referencing_column.object_id AND foreign_key_columns.parent_column_id = referencing_column.column_id INNER JOIN sys.columns referenced_column ON foreign_key_columns.referenced_object_id = referenced_column.object_id AND foreign_key_columns.referenced_column_id = referenced_column.column_id INNER JOIN sys.tables referenced_table ON referenced_table.object_id = foreign_key_columns.referenced_object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id WHERE objects.object_id = foreign_keys.object_id ORDER BY foreign_key_columns.constraint_column_id ASC FOR XML PATH('''')), 1, 2, '''') AS foreign_key_column_list, STUFF(( SELECT '', '' + referenced_column.name FROM sys.foreign_key_columns INNER JOIN sys.objects ON objects.object_id = foreign_key_columns.constraint_object_id INNER JOIN sys.tables parent_table ON foreign_key_columns.parent_object_id = parent_table.object_id INNER JOIN sys.schemas parent_schema ON parent_schema.schema_id = parent_table.schema_id INNER JOIN sys.columns referencing_column ON foreign_key_columns.parent_object_id = referencing_column.object_id AND foreign_key_columns.parent_column_id = referencing_column.column_id INNER JOIN sys.columns referenced_column ON foreign_key_columns.referenced_object_id = referenced_column.object_id AND foreign_key_columns.referenced_column_id = referenced_column.column_id INNER JOIN sys.tables referenced_table ON referenced_table.object_id = foreign_key_columns.referenced_object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id WHERE objects.object_id = foreign_keys.object_id ORDER BY foreign_key_columns.constraint_column_id ASC FOR XML PATH('''')), 1, 2, '''') AS referenced_column_list, ''Foreign Key Column'' AS object_type FROM sys.foreign_keys INNER JOIN sys.tables parent_table ON foreign_keys.parent_object_id = parent_table.object_id INNER JOIN sys.schemas parent_schema ON parent_schema.schema_id = parent_table.schema_id INNER JOIN sys.tables referenced_table ON referenced_table.object_id = foreign_keys.referenced_object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id) INSERT INTO #object_data (database_name, schema_name, table_name, objectname, key_column_list, object_type) SELECT db_name() AS database_name, parent_schema + '' --> '' + referenced_schema, parent_table + '' --> '' + referenced_table, foreign_key_name AS objectname, foreign_key_column_list + '' --> '' + referenced_column_list AS key_column_list, object_type FROM CTE_FOREIGN_KEY_COLUMNS WHERE CTE_FOREIGN_KEY_COLUMNS.foreign_key_column_list LIKE ''' + @search_string + ''' OR CTE_FOREIGN_KEY_COLUMNS.referenced_column_list LIKE ''' + @search_string + '''; -- Default Constraints INSERT INTO #object_data (database_name, schema_name, table_name, column_name, objectname, object_definition, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, objects.name AS table_name, columns.name AS column_name, default_constraints.name AS objectname, default_constraints.definition AS object_definition, ''Default Constraint'' AS object_type FROM sys.default_constraints INNER JOIN sys.objects ON objects.object_id = default_constraints.parent_object_id INNER JOIN sys.schemas ON objects.schema_id = schemas.schema_id INNER JOIN sys.columns ON columns.object_id = objects.object_id AND columns.column_id = default_constraints.parent_column_id WHERE default_constraints.name LIKE ''' + @search_string + ''' OR default_constraints.definition LIKE ''' + @search_string + '''; -- Check Constraints INSERT INTO #object_data (database_name, schema_name, table_name, objectname, object_definition, object_type) SELECT db_name() AS database_name, schemas.name AS schema_name, objects.name AS table_name, check_constraints.name AS objectname, check_constraints.definition AS object_definition, ''Check Constraint'' AS object_type FROM sys.check_constraints INNER JOIN sys.objects ON objects.object_id = check_constraints.parent_object_id INNER JOIN sys.schemas ON objects.schema_id = schemas.schema_id WHERE check_constraints.name LIKE ''' + @search_string + ''' OR check_constraints.definition LIKE ''' + @search_string + '''; -- Database DDL Triggers INSERT INTO #object_data (database_name, objectname, object_description, object_definition, object_type) SELECT db_name() AS database_name, triggers.name AS objectname, triggers.parent_class_desc AS object_description, sql_modules.definition AS object_definition, ''Database DDL Trigger'' AS object_type FROM sys.triggers INNER JOIN sys.sql_modules ON triggers.object_id = sys.sql_modules.object_id WHERE parent_class_desc = ''DATABASE'' AND (triggers.name LIKE ''' + @search_string + ''' OR sql_modules.definition LIKE ''' + @search_string + '''); -- P (stored proc), RF (replication-filter-procedure), V (view), TR (DML trigger), FN (scalar function), IF (inline table-valued function), TF (SQL table-valued function), and R (rule) INSERT INTO #object_data (database_name, schema_name, table_name, objectname, object_definition, object_type) SELECT db_name() AS database_name, parent_schema.name AS schema_name, parent_object.name AS table_name, child_object.name AS objectname, sql_modules.definition AS object_definition, CASE child_object.type WHEN ''P'' THEN ''Stored Procedure'' WHEN ''RF'' THEN ''Replication Filter Procedure'' WHEN ''V'' THEN ''View'' WHEN ''TR'' THEN ''DML Trigger'' WHEN ''FN'' THEN ''Scalar Function'' WHEN ''IF'' THEN ''Inline Table Valued Function'' WHEN ''TF'' THEN ''SQL Table Valued Function'' WHEN ''R'' THEN ''Rule'' END AS object_type FROM sys.sql_modules INNER JOIN sys.objects child_object ON sql_modules.object_id = child_object.object_id LEFT JOIN sys.objects parent_object ON parent_object.object_id = child_object.parent_object_id LEFT JOIN sys.schemas parent_schema ON parent_object.schema_id = parent_schema.schema_id WHERE child_object.name LIKE ''' + @search_string + ''' OR sql_modules.definition LIKE ''' + @search_string + ''''; EXEC sp_executesql @sql_command; FETCH NEXT FROM DBCURSOR INTO @database_name; END CLOSE DBCURSOR; DEALLOCATE DBCURSOR; |
This is a big chunk of TSQL, but despite looking complex is only the sum of all of the database-specific TSQL we have already written, tested, and reviewed. When this section of our script is complete, #object_data will contain all server metadata as well as all database metadata for all databases on our server. This loop may take a little while to run if you are on a server with a large volume of databases or some very sizeable ones, but it will complete and return the results we are looking for, even if it takes a few minutes.
The only task that is left is to return our data from the temp table for our viewing pleasure and then drop the temp table. This is the easy part:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT object_type, server_name, database_name, schema_name, table_name, column_name, objectname, step_name, object_description, object_definition, key_column_list, include_column_list, xml_content, text_content, enabled BIT, status, object_type FROM #object_data; DROP TABLE #object_data; GO |
This script was divided into four parts in order to explain each section, how it works, and why it is written the way it is. Combine all of them and we can run it in its entirety and review the results. To test it, I will search for the word “Department”, and instruct the script to search for SSRS reports, as well as SSIS packages located in MSDB (as shown in the first section of this script, many pages ago). Here are the results that are returned on my local server:
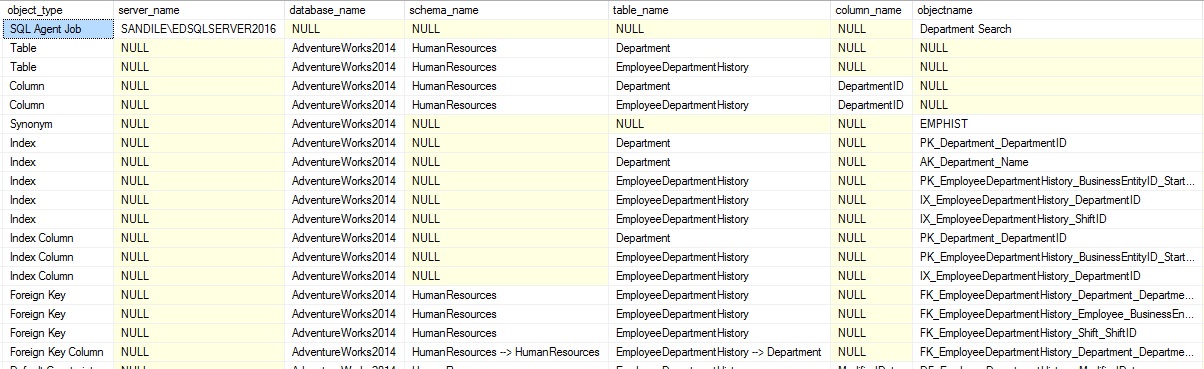
A total of 68 objects were returned, of which a segment can be seen here. I’ve also left off the latter segment of columns, in order to preserve space. This search returned a wide variety of objects: an agent job, tables, columns, a synonym, indexes, index columns, foreign keys, foreign key columns, default constraints, check constraints, and views. It took a total of seven seconds to run on my local server, which is quite good given that my storage is a set of slow SATA spinning disk drives on a USB NAS.
Results can be filtered down by searching using more specific keywords. Some of the most common searches I have performed are for linked servers, stored procedures, functions, or tables, in an effort to determine their usage. If you are unlucky and are trying to figure out if a stored procedure called “proc” is in use, or a table called “t”, then you’ll have more results to scan through in order to find relevant results, if a search like this is even worth it. Hopefully that conundrum won’t befall you often.
Customization
There’s a wide variety of other metadata available about each of the objects discussed in this article that could be included in a schema search. Feel free to take this code and modify it to include whatever additional metadata is required to make your search experience complete. Documentation on each of the views used in this article is available on MSDN and provides more than enough details to make the customization process easy.
I personally like getting all of my search results back in a single result set for convenience, but if you’d prefer to separate them into multiple batches, there is no harm in doing so. This could allow you to collect more metadata for specific object types, if they held particular interest for you.
In addition, there are many objects not searched here, most of which pertain to unique SQL Server features. This may include replication, resource governor, in-memory OLTP, partitioning, and more. If you use these features and want to include them in a universal search proc, adding them is quite easy! Mirror the structure created in this article and add metadata for additional objects into the temp table as additional steps.
If you’d like an exact search instead of the wildcard search, feel free to comment out the addition of the %’s to either end of the search criteria or add a flag for that option so that you can determine at runtime if it’s desired or not. Lastly, the contents of this script can be stuffed into a stored procedure for easy use later, with the configuration section becoming a set of proc parameters. Whether used as a snippet, stored procedure, or ad-hoc script is up to you and whatever is easiest in your environment.
Conclusion
The ability to quickly and easily search SQL Server for object metadata is a common need, and one that can be frustrating to manage manually. The various scripts provided in the earlier half of this article provide simple ways to search for a variety of metadata and can be exceptionally useful when a specific need arises. Many system views are introduced that can be used for schema searches such as this, or for gathering more detailed data on a particular type of object.
In the second part of this article, we put everything together into a single script that can be run in order to return information on many different objects in SQL Server. Feel free to take this script, modify it, and use it to fulfill your own search needs. Tools such as this are time-savers and reduce the amount of busy-work that we are forced to endure on a regular basis. Enjoy!!!
Also, a special thanks goes out to Nick Salvi, a coworker with extensive SSIS/SSRS experience who provided the TSQL that was the basis for searching those parts of SQL Server!

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019