
Description
SQL Identity columns provide a convenient way to auto-number an ID column within a table without the need to manage the sequence. This convenience can save immense amounts of time, but also presents a single challenge: What happens when an identity column runs out of space within the data type chosen?
In this article, we will answer this question, as well as explore a variety of ways to detect this problem before it arises and solve it without causing disruption to important tables.
Introduction
SQL Identity columns are often used as a way to auto-number some data element when we have no need to assign any specific values to it. Either the values are arbitrary, the column is a surrogate key, or we wish to generate numbers for use in other processes downstream.
For most applications, identity columns are set-it-and-forget-it. For an integer, which can contain 2,147,483,647 positive values, it’s easy to assume that a number so large is out-of-reach for a fledgling table. As time goes on, though, and applications grow larger, two billion can quickly seem like a much smaller number. It’s important to understand our data usage, predict identity consumption over time, and proactively manage data type changes before an emergency arises.
What happens when a SQL Identity Column is exhausted
When a SQL identity column reaches its limit, all insert operations will fail. We can test this easily by creating a table with an identity column, reseeding it to its limit, and then trying to insert a new row. Here’s a table with only 2 columns, an identity that is set to a seed near its maximum value and a string:
|
1 2 3 4 |
CREATE TABLE dbo.Identity_Test ( My_Identity INT NOT NULL IDENTITY(2147483646,1) CONSTRAINT PK_Identity_Test PRIMARY KEY CLUSTERED, My_Dinosaur VARCHAR(25) NOT NULL ); |
With the table created, we can begin inserting some data:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Euoplocephalus'); INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Triceratops'); |
After these inserts, we can view the data in our table:
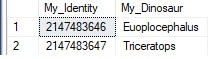
Note that the identity value for our Triceratops is at the highest allowed by an integer data type. Now, let’s insert one more row:
|
1 2 3 4 |
INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Micropachycephalosaurus'); |
The result of this SQL INSERT statement is the following error:

SQL Server provides no built-in warning. When we exceed the bounds of a data type, we receive the same error that would be returned if we tried to store a higher number in the INTEGER. Until an action is taken on our part to resolve the limit we have hit, inserts will continue to fail. All other operations on this table will execute normally, including DELETE, UPDATE, and SELECT.
The remainder of this article will deal with detecting a data type that is getting full with enough time so that we can take an action that does not need to be based on panic 🙂
How to determine remaining space in a SQL Identity Column
SQL Server provides two tools that allow us to accurately and quickly research identity column usage:
- System views
- IDENT_CURRENT
System views provide us with information about tables, schemas, columns, and other objects in SQL Server. We can use these to generate lists of different types of objects that can then be used for reporting or further research. For our work here, we will use system views to collect a list of all identity columns in a given database. Once we have this list, we can begin researching each column and understanding how far along we are within each column’s data type. The following views will be used in our work:
- sys.tables: A view with a row per user table in a given database.
- sys.columns: Returns a row for each column in any view or table.
- sys.types: Contains a row for each data type in defined in a given database. This includes both user and system data types.
- sys.schemas: Returns a row for each schema defined within a database.
By joining these views together, we can create a query that will provide details about each SQL identity column within a database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT DB_NAME() AS database_name, schemas.name AS schema_name, tables.name AS table_name, columns.name AS column_name, types.name AS type_name FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON types.user_type_id = columns.user_type_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE columns.is_identity = 1; |
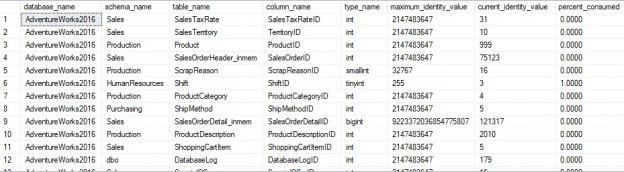
When run in the WideWorldImporters Microsoft demo database, we get the following result set:

This database contains three SQL identity columns, including the one we created earlier in this article. Our system views return the schema, table, and column name, as well as the data type. Filtering on columns.is_identity = 1, we can limit our result set from all columns to only those that are defined with the IDENTITY attribute.
The next tool at our disposal is the built-in function IDENT_CURRENT, which returns the last identity value that was allocated for a given identity column. This function accepts a table name (including the schema name) and returns the last SQL identity value used:
|
1 |
SELECT IDENT_CURRENT('Warehouse.VehicleTemperatures') AS current_identity_value; |
This query returns the following results:
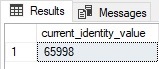
Since that column is a BIGINT, we have a long way to go before we exhaust the ~9.2 quintillion values available to it.
This is a good start, but we do not want to run a separate query on every single table. While the schema name is optional, if we do not include it, then it will default to the dbo schema, which will not work for any tables that are not in the default dbo schema. For tables in other schemas, we will need to write dynamic SQL to insert both the schema and table name into the IDENT_CURRENT function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
USE WideWorldImporters; GO CREATE TABLE #identity_columns ( [database_name] SYSNAME NOT NULL, [schema_name] SYSNAME NOT NULL, table_name SYSNAME NOT NULL, column_name SYSNAME NOT NULL, [type_name] SYSNAME NOT NULL, maximum_identity_value BIGINT NOT NULL, current_identity_value BIGINT NULL, percent_consumed DECIMAL(25,4) NULL ); DECLARE @Table_Name NVARCHAR(MAX); DECLARE @Schema_Name NVARCHAR(MAX) DECLARE @Sql_Command NVARCHAR(MAX) = ''; SELECT @Sql_Command = @Sql_Command + ' INSERT INTO #identity_columns ([database_name], [schema_name], table_name, column_name, [type_name], maximum_identity_value, current_identity_value) SELECT DB_NAME() AS database_name, ''' + schemas.name + ''' AS schema_name, ''' + tables.name + ''' AS table_name, ''' + columns.name + ''' AS column_name, ''' + types.name + ''' AS type_name, CASE WHEN ''' + types.name + ''' = ''TINYINT'' THEN CAST(255 AS BIGINT) WHEN ''' + types.name + ''' = ''SMALLINT'' THEN CAST(32767 AS BIGINT) WHEN ''' + types.name + ''' = ''INT'' THEN CAST(2147483647 AS BIGINT) WHEN ''' + types.name + ''' = ''BIGINT'' THEN CAST(9223372036854775807 AS BIGINT) WHEN ''' + types.name + ''' IN (''DECIMAL'', ''NUMERIC'') THEN CAST(REPLICATE(9, (' + CAST(columns.precision AS VARCHAR(MAX)) + ' - ' + CAST(columns.scale AS VARCHAR(MAX)) + ')) AS BIGINT) ELSE -1 END AS maximum_identity_value, IDENT_CURRENT(''[' + schemas.name + '].[' + tables.name + ']'') AS current_identity_value; ' FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON types.user_type_id = columns.user_type_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE columns.is_identity = 1; EXEC sp_executesql @Sql_Command; UPDATE #identity_columns SET percent_consumed = CAST(CAST(current_identity_value AS DECIMAL(25,4)) / CAST(maximum_identity_value AS DECIMAL(25,4)) AS DECIMAL(25,2)) * 100; SELECT * FROM #identity_columns; |
This script adds additional elements to our previous query, including:
- The size of a column. For TINYINT, SMALLINT, INT, and BIGINT, this is a fixed value. For DECIMAL and NUMERIC, it is based on the definition of the column and how much space is allocated to the non-decimal component of the data type.
- The current SQL identity value, which is the number returned by IDENT_CURRENT.
- The percent of the column consumed, as determined by dividing the current identity value by the maximum value and multiplying by 100.
When run on WideWorldImporters, we get the following output:

These results provide us with everything we need to understand how much of an identity columns data space has been consumed. We can see that the first two columns are safe for now, as they have an immense amount of identity values to churn through before being in danger of running out. Our test table, on the other hand, is at 100% capacity. As we recall from the demo earlier, this column has no space left and INSERT operations against it will fail due to this limit.
If we run the query above against AdventureWorks2016, we can see a larger result set:
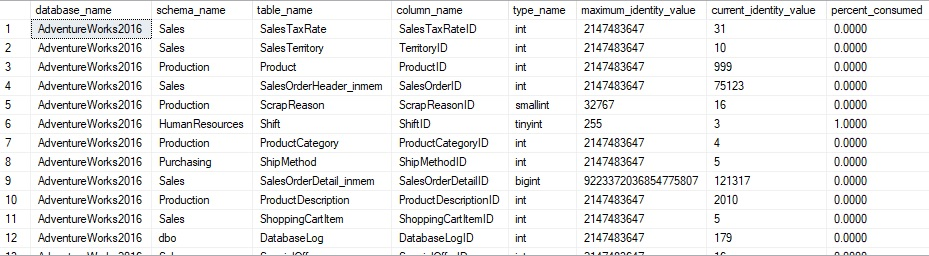
We can see here that nearly all columns are under 1% used, with the exception of the TINYINT identity on HumanResources.Shift.
Links are provided at the end of this article to where you can download Microsoft’s various demo databases, which are used throughout this article.
Resolving SQL Identity Fullness
Now that we have the ability to quickly research identity column utilization, we can take the TSQL presented above and move it into a stored procedure that gets executed via a job or some other process semi-regularly. We can then choose some threshold that we need to act on. For example, we may decide that any identity column that is over 85% consumed will be the target of DBA actions in order to prevent it from exhausting the range of its data type.
Once we have identified a table that needs to be acted upon, we have a variety of choices in how to solve the problem. Determining the best option for resolving an identity column’s fullness will be require us to consider the table, its usage, contention, and resources available. Here are some ways that we can solve our problem:
Alter an identity column in-place
The simplest way to increase the range of a SQL identity column is to alter it to a larger data type. For example, we can change a SMALLINT into an INT, or an INT into a BIGINT. This option requires very little TSQL, but will lock the table while it is executing. In addition, quite a bit of log space can be used to complete the operation.
Pros
- Simple TSQL, minimal effort to implement. Application may need to be updated to address the new data type, but no significant code changes should be required.
- No need to rename objects or start a new table for our data.
- The risk of overflowing data decreases drastically after this change.
Cons
- Will lock the table while executing. For a large table, this can take a long time and prevent applications and processes from using the table.
- Can cause significant log growth if the table is large.
-
Any objects that depend on the column, such as primary keys, foreign keys, and indexes will need to be dropped prior to the operation, and re-added afterwards. This may result in reduced performance until the index is recreated.
Altering a column in place is good for a smaller table or in scenarios where an application outage is tolerable. Consider that every row in the table needs to be updated as additional space needs to be allocated to the column in each row. For a table with a billion rows with an integer identity column, altering to a BIGINT will require approximately 4 billion additional bytes. That’s about 4GB of data that needs to be written to the table, at minimum. In practice, the space used will likely be much higher as the data will not all be compactly squeezed into consecutive, full pages. Instead, there will be page splits and the index (or heap) will temporarily take up more space, until index maintenance is performed.
To test a column alter on our table from earlier, we can implement it as follows:
|
1 2 3 |
ALTER TABLE dbo.Identity_Test ALTER COLUMN My_Identity BIGINT NOT NULL; |
Executing this results in an error message:

Ah, we need to drop our clustered primary key on this column before we can alter its data type:
|
1 2 3 4 5 |
ALTER TABLE dbo.Identity_Test DROP CONSTRAINT PK_Identity_Test; ALTER TABLE dbo.Identity_Test ALTER COLUMN My_Identity BIGINT NOT NULL; |
This succeeds, and we can view the new data type in the table:

Now, we can add back the clustered primary key that originally was defined on the column:
|
1 2 3 |
ALTER TABLE dbo.Identity_Test ADD CONSTRAINT PK_Identity_Test PRIMARY KEY CLUSTERED (My_Identity); |
And, we’re done! Of course, this table only had a handful of rows, so we expected this to be a quick and painless operation.
Reseed the SQL Identity Column
An additional option to resolve an identity column that is running out of space is to reseed to column to a very low number and allow it to begin growing naturally again. This option requires no application-facing schema changes, but it will force the reuse of old IDs, which may not be an acceptable option. In addition, if the column is truly growing fast, this may only serve as a temporary solution. If the identity column fills up again soon, then we’ll be forced to revisit this problem again (and again).
Pros
- No application-facing schema changes.
- Will not block applications.
- Will not cause any significant log growth.
- Will not take long to execute.
Cons
- Reuses old SQL identity values, which may be unacceptable for tables in which the ID values are important and must be unique all-time.
- If table is very fast-growing, it will only be a temporary solution that we will need to visit again soon.
- Need to confirm existing column values to ensure that we will not duplicate a value in the near future.
This solution truly feels like we are kicking the can down the road a bit, and in many scenarios that will be the case. For a table in which the ID values are disposable and the data short-lived, though, this can be a quick and easy way to resolve the problem without having to resort to lengthening the column.
Let’s demonstrate how to reseed an identity column to a new value:
|
1 |
DBCC CHECKIDENT ('Dbo.Identity_Test', RESEED, -2147483648); |
Executing this is quick and painless, and there’s no need to drop dependencies, since the schema itself isn’t changing. Now if we insert a row, we’ll note that it now has an ID that’s a very, very negative number:
|
1 2 3 4 5 |
INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Pterodactyl'); SELECT * FROM dbo.Identity_Test; |
The results of the SELECT are as follows:
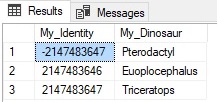
Note that the Pterodactyl has the most negative value allowed by an integer data type. We’re now all set until we’ve exhausted about 4.2 billion integers!
If you choose to reseed the column on a semi-regular basis, be sure to validate that ID values will never, ever be reused. What happens if we reuse an identity value? We can test that here:
|
1 |
DBCC CHECKIDENT ('Dbo.Identity_Test', RESEED, 2147483646); |
Now we can try once again to add another dinosaur to our table:
|
1 2 3 4 |
INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Micropachycephalosaurus'); |
The result is an error:

Note that once again, the error did not mention that a SQL identity column crashed into itself or even that the identity itself was to blame. It simply tried to insert a value that was already there and threw a primary key violation as a result. Because of this—be careful when reseeding identity columns and ensure that numbers cannot be accidentally reused. Also, keep in mind that you may reseed an INT or BIGINT to a negative value as we did earlier in order to increase the range of numbers that can be used before the column’s data type is exhausted.
Create a New Table
A more complex, but good solution for the scenario in which you have far more data is to create a new table with a correctly sized identity column, slowly sync the data up, and then switch over to use it at a future time. This allows us to stage our data and prepare the new column at our leisure without causing any significant blocking or application outage while we are updating our schema.
Pros
- We avoid identity value reuse or the churn of altering a column in-place.
- The new column can be backfilled slowly, preventing the need for a long outage while the new data is populated.
- Scales, even for very large tables.
Cons
- The small outage should still be planned while the tables are swapped.
- More complex solution than previous solutions.
- Trigger (or some maintenance logic) is required on source table to keep both in sync.
There are a number of ways of accomplishing this, each with varying degrees of rigidness in the release process. The method demonstrated here will ensure that all data is copied to a new table and kept in sync until we are ready to swap. If your needs are less stringent, feel free to simplify the process to reduce complexity and/or work. Here is the starting point for our efforts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
CREATE TABLE dbo.Identity_Test_BIGINT ( My_Identity BIGINT NOT NULL IDENTITY(1,1) CONSTRAINT PK_My_Identity_BIGINT PRIMARY KEY CLUSTERED, My_Dinosaur VARCHAR(25) NOT NULL ); GO CREATE TRIGGER TR_Identity_Test_Bigint_Upgrade ON dbo.Identity_Test AFTER INSERT, UPDATE, DELETE AS BEGIN SET NOCOUNT ON; -- INSERTS ONLY SET IDENTITY_INSERT dbo.Identity_Test_BIGINT ON; INSERT INTO dbo.Identity_Test_BIGINT (My_Identity, My_Dinosaur) SELECT Inserted.My_Identity, Inserted.My_Dinosaur FROM Inserted LEFT JOIN Deleted ON Deleted.My_Identity = Inserted.My_Identity WHERE Deleted.My_Identity IS NULL; SET IDENTITY_INSERT dbo.Identity_Test_BIGINT OFF; -- DELETES ONLY DELETE Identity_Test_BIGINT FROM dbo.Identity_Test_BIGINT WHERE Identity_Test_BIGINT.My_Identity IN ( SELECT Deleted.My_Identity FROM Deleted LEFT JOIN Inserted ON Deleted.My_Identity = Inserted.My_Identity WHERE Inserted.My_Identity IS NULL); -- UPDATES ONLY UPDATE Identity_Test_BIGINT SET My_Dinosaur = Inserted.My_Dinosaur FROM Inserted INNER JOIN Deleted ON Deleted.My_Identity = Inserted.My_Identity INNER JOIN dbo.Identity_Test_BIGINT ON Identity_Test_BIGINT.My_Identity = Inserted.My_Identity WHERE Inserted.My_Dinosaur <> Deleted.My_Dinosaur; -- UPDATES WHERE THE ROW HAS YET TO EXIST IN THE NEW TABLE SET IDENTITY_INSERT dbo.Identity_Test_BIGINT ON; INSERT INTO dbo.Identity_Test_BIGINT (My_Identity, My_Dinosaur) SELECT Inserted.My_Identity, Inserted.My_Dinosaur FROM Inserted INNER JOIN Deleted ON Deleted.My_Identity = Inserted.My_Identity WHERE Inserted.My_Identity NOT IN (SELECT Identity_Test_BIGINT.My_Identity FROM dbo.Identity_Test_BIGINT); SET IDENTITY_INSERT dbo.Identity_Test_BIGINT OFF; END |
This script creates a new table called Identity_Test_BIGINT and adds a trigger onto Identity_Test that will mirror all operations onto the new table: INSERT, UPDATE, and DELETE. In addition, if an update occurs on a row that is not in the new table, we’ll also catch that and copy it over. Here are some demos of the operations and results:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO dbo.Identity_Test (My_Dinosaur) VALUES ('Troodon'); SELECT * FROM dbo.Identity_Test; SELECT * FROM dbo.Identity_Test_BIGINT; |
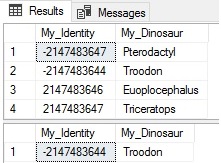
We can see that the new row was correctly inserted into the new table.
|
1 2 3 |
UPDATE dbo.Identity_Test SET My_Dinosaur = 'Parasaurolophus' WHERE My_Dinosaur = 'Troodon'; |
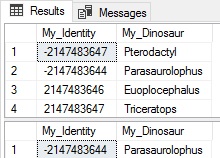
The update was also correctly applied to both the exsiting table, as well as the new one.
|
1 2 3 |
DELETE FROM dbo.Identity_Test WHERE My_Dinosaur = 'Parasaurolophus'; |
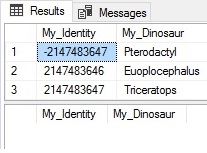
Similarly, the delete operation removes the row from both tables. Lastly, what happens if we update a row in SQL Identity table Identity_Test that does not exist in our new table?
|
1 2 3 |
UPDATE dbo.Identity_Test SET My_Dinosaur = 'Parasaurolophus' WHERE My_Dinosaur = 'Pterodactyl'; |
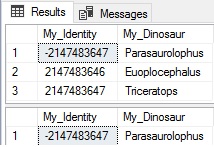
The last section of the trigger ensured that the update resulted in an insertion into the new table. At this point, we can backfill our data using whatever method we’d like. The following will batch IDs into groups of 2000, allowing for a safe and slow backfill that should have minimal impact on production operations. The batch sizes can be increased, but use caution to ensure that no negative impact results from writing too much data at once.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
WHILE @@ROWCOUNT > 0 BEGIN SET IDENTITY_INSERT dbo.Identity_Test_BIGINT ON; INSERT INTO dbo.Identity_Test_BIGINT (My_Identity, My_Dinosaur) SELECT TOP 2000 Identity_Test.My_Identity, Identity_Test.My_Dinosaur FROM dbo.Identity_Test WHERE Identity_Test.My_Identity NOT IN (SELECT Identity_Test_BIGINT.My_Identity FROM dbo.Identity_Test_BIGINT) SET IDENTITY_INSERT dbo.Identity_Test_BIGINT OFF; END |
This runs quickly enough on our test data, and we can now confirm that both tables are synced up:
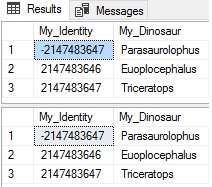
Once the tables are identical, the last step is a one-time release to swap our tables:
|
1 2 3 4 5 |
EXEC sp_rename @objname = 'dbo.Identity_Test', @newname = 'Identity_Test_OLD'; EXEC sp_rename @objname = 'dbo.PK_Identity_Test', @newname = 'PK_Identity_Test_OLD', @objtype = 'OBJECT'; EXEC sp_rename @objname = 'dbo.Identity_Test_BIGINT', @newname = 'Identity_Test'; EXEC sp_rename @objname = 'dbo.PK_My_Identity_BIGINT', @newname = 'PK_Identity_Test', @objtype = 'OBJECT'; DROP TRIGGER TR_Identity_Test_Bigint_Upgrade; |
Because this is a DDL operation in which no data is being modified, it will execute very quickly. The now-old objects are renamed and the new table is given the original table name of Identity_Test. The old table can be dropped at a later date, whenever is convenient or when the release is deemed a success.
As a result, the timing of this release can be made to occur in an extremely short window. Realistically, a very short outage for the database would be the safe way to deploy, but even without an outage, the interruption would be extremely brief. An application with only modest resilience would likely see little in the way of interruption.
This process can easily be tweaked, as needed, in order to accommodate tables of different sizes or complexities, but the general approach applies regardless.
Conclusion
SQL Identity columns are useful ways to generate sequential values with minimal effort or intervention. Checking periodically to ensure that identities have sufficient room to grow can help avert disaster and allow the problem to be solved preemptively without the need for last-minute panic.
Once identified, increasing the size of an identity column isn’t difficult, and we can choose from a variety of solutions based on the size, usage, and availability required of the table. Like many maintenance tasks, being able to perform this work on our terms saves immense time, effort, and stress. This not only makes us happier, but frees up more time so we can work on more important tasks!
References
- Microsoft’s IDENTITY column reference
- Data type details, including size and available number space
- WideWorldImporters Demo Databases
- AdventureWorks Demo Databases

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019