
In this article, we will show how to source data from Azure SQL Database to use in a Machine Learning workflow.
Introduction
Azure offers a variety of data repositories for operational as well as analytical purposes. One of the most popular and highly adopted database services is Azure SQL Database, which is typically used to host transactional data in Online Transaction Processing (OLTP) systems. A typical data pipeline involves ingesting data into different types of data repositories. Data from different repositories may be optionally enriched or standardized using approaches like Master Data Management (MDM). Data is generally moved using Extract Transform Load (ETL) or Extract Load Transform (ELT) mechanisms. Once the data is in a proper state, it may be stored in a data warehouse in a structured format or in a data lake which is a mix of structured, semi-structured, and unstructured formats. SQL Database is one of those versatile data repositories that can store different types of data, which makes it an ideal candidate for being used as a data warehouse or data mart too. Once data is in operational and analytical repositories, this data is used for various types of analytics, prediction, forecasting, and other types of data intelligence.
Machine learning is one of the most popular means of extracting intelligence out of data. Azure offers Azure ML service which is one of the mainstream services for authoring machine learning workflows. Like other data processing systems, Azure Machine Learning service requires and supports sourcing data from different types of data repositories including Azure SQL Database. Sourcing data is usually the first step while authoring Azure Machine Learning workflows. Let’s go ahead and see how you can source data from SQL Database to use in an Azure Machine Learning workflow.
Pre-Requisites
It is assumed that one has enough access to Azure Machine Learning service as well as Azure SQL Database. Our intention is to source data from SQL Database, for which we need an instance of the database with some sample data in it. An easy way to create sample data in SQL Database is by using the built-in sample data option which creating an instance, which will pre-populate the instance with sample data. It is assumed the one has this instance with sample data in place.
Azure Machine Learning service is administered using Azure ML Studio which can be accessed after creating Azure ML Workspace. Those who are new to Azure ML Studio can refer to this article, Introduction to Azure Machine Learning using Azure ML Studio, to get started with it and create an Azure ML Workspace. It’s assumed this workspace is in place and one has the required access to it.
Datasets and Data stores in Azure Machine Learning
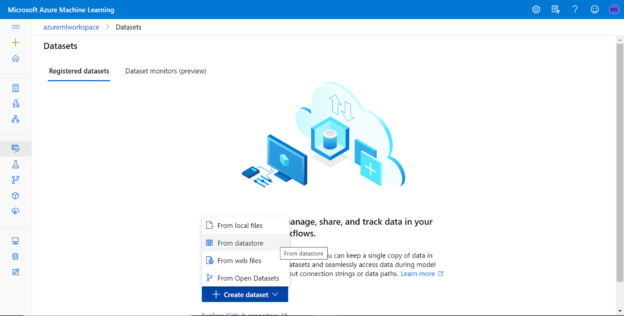
Navigate to the Azure ML Workspace instance, and open Azure ML Studio. There are different options to author and execute machine learning models like using notebooks, designers, experiments etc. All these mechanisms share a common way to source data, by the means of datastores and datasets. The first step to set up is creating a new data store which is Azure SQL Database in our case. Click on the Datastores icon on the left pane as shown below. Click on the New datastore button, which would pop-up a new screen as shown below.

Provide basic details and select the datastore type as Azure SQL Database shown above. Configure the authentication type and provide credentials to validate the data source and create an instance of a new data store. This will complete the creation of a data store. Now that we have the data store in place, we need to create a new dataset. A datastore is a registered data repository that may contain an entire data warehouse or transactional database. A dataset is a scope of data that is to be selected from the datastore. Navigate to the home icon, and click on the new button, which will provide an option to create a new dataset as shown below.

Click on the datastore option and it would open a wizard to create the new datastore as shown below. Provide a new name for the datastore and select the type as tabular. The two supported options are tabular and file bases. As our data source is Azure SQL Database, the Tabular option is relevant for us.

Select the datastore that we created earlier in this step. If we would have started the creation of a dataset from the datastore instance, then it would have been pre-selected. Click on the select datastore button and click on the Next button.

In this step, we can provide the query that forms the scope of the data that we intend to use in the Machine Learning workflow. Provide the desired query as shown below and click on the Next button. We also have the option to skip the data validation, although it’s recommended to validate it as we can uncover any connectivity issues before creating the datastore.

In this step, we can preview the data and configure any data related settings as shown below.

In this step, we can configure any schema-related settings like changing the datatype, removing any undesired field etc. as shown below.

In the next step, we finally need to confirm the details and create the new dataset. This concludes the creation of the dataset. Now we are ready to consume this dataset, which is part of a data store that may be a data warehouse or a transactional database. Once the dataset is created, we can navigate to the designer and open any workflow. In the left pane, under the dataset tab, we should be able to find the newly created dataset. Drag and drop the dataset on the layout, right-click the same to view the options that would enable us to visualize the data in the workflow as shown below.

In this way, we can source the data from Azure SQL Database in Azure Machine Learning workflows.
Conclusion
We started with an assumed setup of Azure SQL Database and Azure Machine Learning workspace. We registered the database by creating a datastore. Using the same, we created a scope in the datastore in the form of a dataset, which becomes available for use within Azure Machine Learning workflows.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023