

In this article, we are going to make a SQL practice exercise that will help to prepare for the final round of technical interviews of the SQL jobs.
Introduction
Technical interviews are an indispensable part of the recruiting process for employers. Employers want to assess the technical knowledge and ability of the candidate for the role so they can decide whether the candidate is a good fit for the role. Commonly technical interviews that may we encounter include various questions and aims to understand our coding capability and skills. Substantially, preparing for a technical interview requires some effort because we need to review the major topics, and look at the common questions that may ask in the interview that will help us feel more comfortable in the technical interviews.
In terms of SQL-related jobs (Database Architect, Database Administrator, Business Intelligence Developer, SQL Developer, etc.) making a SQL practice exercise will help to feel more comfortable in the interviews to answer the question. In the next steps of this article, we will take a look at some questions that may ask in the interview and help to practice for the interview.
Pre-requisites
In some SQL practice examples of this article, we will use the Adventureworks2019 sample database, and also we will use the Enlarging the AdventureWorks script.
How to write efficient SQL Queries?
This question commonly is asked in SQL-related jobs technical interviews and the main idea behind this question is to understand our SQL coding capability and knowledge of the SQL practice. We can answer this question as follows :
- We should not use an asterisk (*) sign in the select SQL queries thus we can decrease the I/O usage of the query and network traffic.
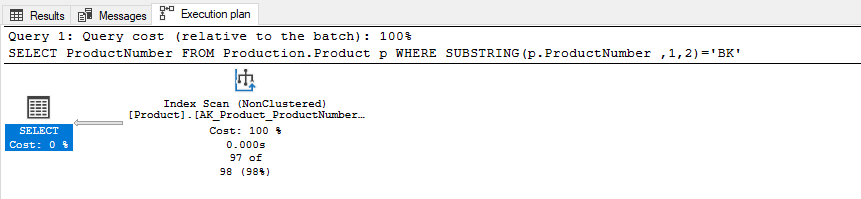
- As possible, we should write saragable queries so that our queries will use the indexes more efficiently. Such as we can look at the following queries, they will fetch some products whose first two names start with ‘BK’ characters.
This query will not use the index efficiently, we understand this situation from the execution plan of the query.
|
1 2 3 4 |
SELECT ProductNumber FROM Production.Product p WHERE SUBSTRING(p.ProductNumber ,1,2)='BK' |
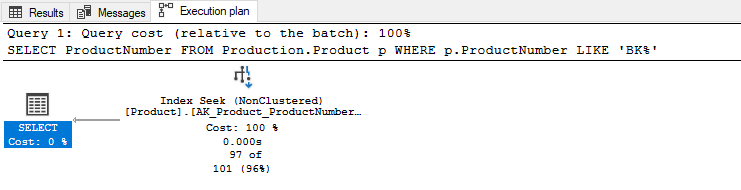
However, we can transform this query as the below and it will return the same results set as the previous query and its query plan will be more efficient.
|
1 2 3 4 |
SELECT ProductNumber FROM Production.Product p WHERE p.ProductNumber LIKE 'BK%' |
Other than this straightforward example, we can look at the SQL practice examples of how we can transform non-sargable queries into sargable queries.
Non-Sargable:
|
1 2 3 4 |
SELECT p.Color FROM Production.Product p WHERE ISNULL(p.Color,'Red') ='Red' |
Sargable:
|
1 2 3 4 |
SELECT p.Color FROM Production.Product p WHERE (p.Color IS NULL OR p.Color='Red') |
Non-Sargable:
|
1 2 3 4 |
SELECT p.ModifiedDate FROM Production.Product p WHERE YEAR(ModifiedDate)=2019 |
Sargable:
|
1 2 3 4 |
SELECT p.ModifiedDate FROM Production.Product p WHERE p.ModifiedDate BETWEEN '20190101' AND '20191231' |
- As possible as we should add understandable and brief comments to our queries
- Formatting the SQL queries will help to increase the readability of SQL Queries and we can use some tools like Code Beautify, Beautify Code, Poor SQL, etc.
What is the difference between a Primary Key and Clustered Index?
This SQL practice exercise aims to understand our expertise related to the logical concept of the SQL Server. Now let’s look at the answer to the question.
The clustered index is a type of index that sorts the data of the table according to the defined columns or set of columns. The data of a table can be sorted only one way, for this reason, there can be only one clustered index defined for a table. The main advantage of the clustered indexes is to enable access to the data more performant.
The primary key is a constraint that enables the unique identification of each row in a table through a column or set of column combinations. The primary key values can’t contain any NULL values and each table can have only one primary key. By default, after defining a primary key, that automatically creates a clustered unique index but we can change it to a nonclustered unique index.
So, the primary key and clustered index are different objects of the SQL Server but as a best SQL practice, we commonly use them together.
What is the result set of the following query?
During the technical interview, we can face some query reading questions to understand our SQL query reading capabilities. For this reason, we need to make some SQL practice to improve our query reading skills. For example, the following question, which seems very simple but contains a bit of confusion, may be asked of you during the interview.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
DROP TABLE IF EXISTS #Test CREATE TABLE #Test ( ID INT IDENTITY(1, 1) PRIMARY KEY , FruitName VARCHAR(100) , SalesAmount MONEY , TransactionDate DATETIME ) INSERT #Test VALUES ('Banana',10,'20220512') , (NULL,5,'20220401') , ('Orange',15,'20221211'), ('Apple',20,'20220312') SELECT t.FruitName AS [Fruit Name] , t.SalesAmount AS [Sales ] , SUM(t.SalesAmount) OVER () AS [Total] FROM #Test t WHERE t.FruitName NOT IN ('Apple',NULL) |
A-)
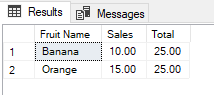
B-)
C-)
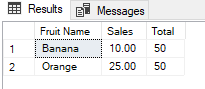
The right answer to this question is B because the NULL values cannot be correctly handled by the NOT IN operator. The reason for this problem is related to the FruitName!= NULL comparison result is always NULL, therefore the entire WHERE clause output will be always FALSE. As a best SQL practice consider the nullable column values when we decide to use the NOT IN operator in the queries.
What is the difference between NOLOCK and READPAST query hints?
The NOLOCK hints allow reading data from the table by ignoring any locks but THE NOLOCK hint can’t ignore the schema locks. It has one advantage and one disadvantage.
- The advantage is it enables improving query performance.
- The disadvantage is it causes dirty reads, which means that the uncommitted data will be included in the result of the query.
The READPAST hint does not read the rows locked by the other seasons during the read operation.
What is parameter sniffing in SQL Server?
SQL Server query optimizer will compile the stored procedure when it invokes the first time according to the input parameters. After this, it keeps this compiled execution plan in the plan cache to use for the next execution of the same procedure. So, parameter sniffing is a process to sniff the first input parameters and generate an optimal execution plan according to these parameters and use this plan for other parameters. However, this plan may not be optimum for the other parameter used when the data distribution of the exposed tables is very uneven. In the SQL practice, we can resolve the parameter sniffing in different ways:
- For SQL Server 2022 consider enabling Parameter Sensitive Plan optimization
- Can use WITH RECOMPILE option in the stored procedure
- Can use the RECOMPILE option when creating a stored procedure
- Can use OPTIMIZE FOR UNKNOWN hint;
- Can use OPTIMIZE FOR hint for the particular parameter values
- Can use local variables in the stored procedures
- Can enable the Trace flag 4136;
- Can Disable the Parameter Sniffing option of the Database Scoped Configuration
What is the Table Variable in SQL Server? Explain its pros and cons?
The table variable is a particular local variable type that allows for storing data in the table structure.
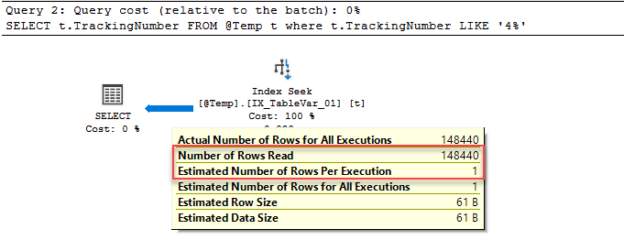
The advantage of table variables is mainly that they are not fully logged thus populating them with data will be faster and will require less space in the transaction log. At the same time, they are causing less contention in the system tables. On the other hand, the optimizer makes a constant estimation for it because they do not have any statistics. However, this issue was resolved with the SQL Table variable deferred compilation feature which was announced with the SQL Server 2019. Now let’s make a little SQL practice about this feature. When we execute the following query in a database which is the compatibility level is equal to 140 or under, we will see a dramatic difference between the estimated number of rows per execution.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @Temp AS TABLE ( TrackingNumber VARCHAR(100) INDEX IX_TableVar_01 NONCLUSTERED , LTotal FLOAT ) INSERT INTO @Temp SELECT CarrierTrackingNumber , LineTotal FROM Sales.SalesOrderDetailEnlarged SELECT t.TrackingNumber FROM @Temp t WHERE t.TrackingNumber LIKE '4%' |
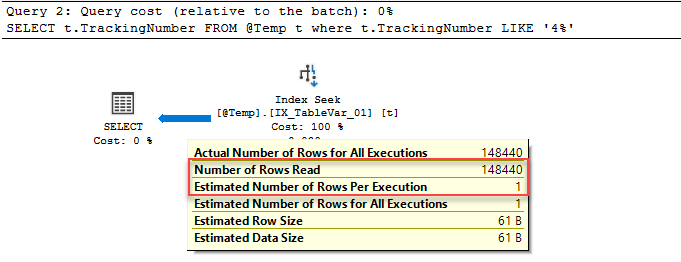
Now we will change the compatibility level of the database to 150 which indicates the SQL Server 2019
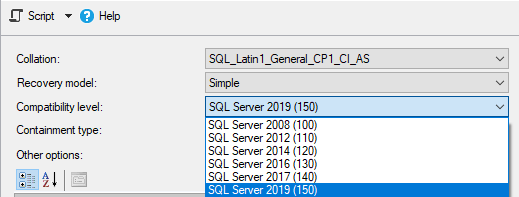
Now, we will execute the same query and look at its execution plan. As seen below the optimizer makes more accurate estimations because of the SQL Table variable deferred compilation
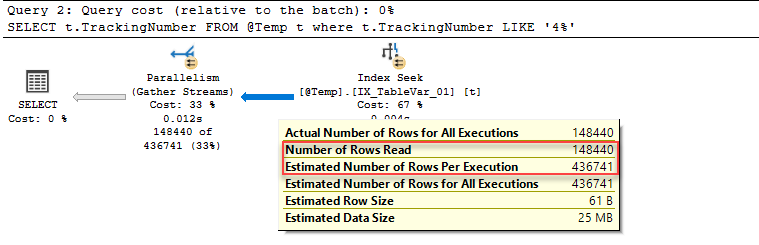
Tip: Insert operations into the table variable can’t be processed as parallel. After enabling the actual execution plan, we will execute the following query.
|
1 2 3 4 5 6 7 8 9 10 11 |
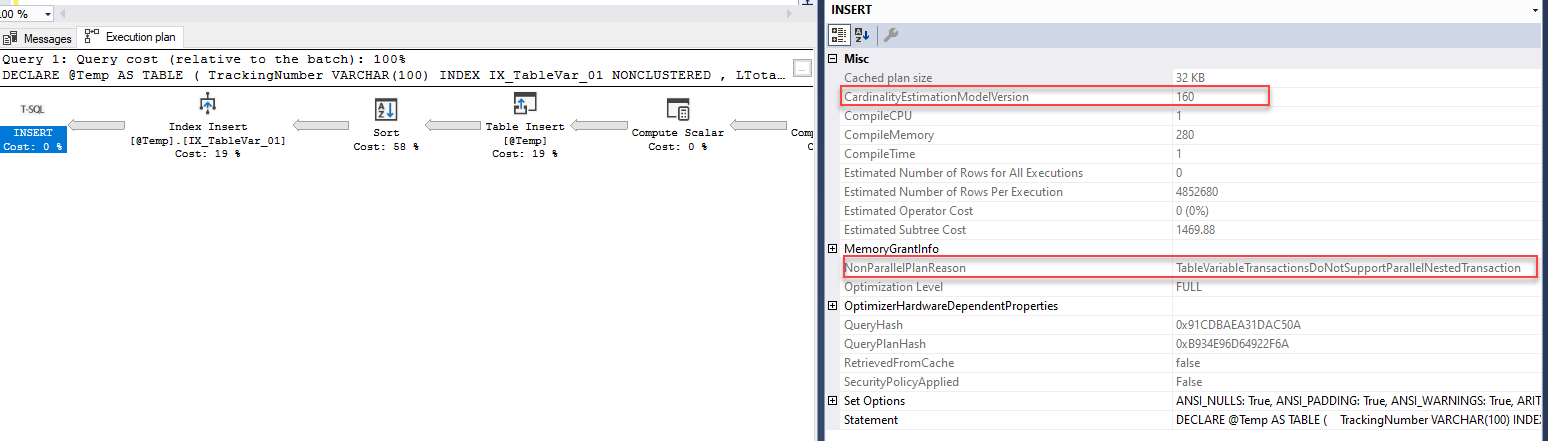
DECLARE @Temp AS TABLE ( TrackingNumber VARCHAR(100) INDEX IX_TableVar_01 NONCLUSTERED , LTotal FLOAT ) INSERT INTO @Temp SELECT CarrierTrackingNumber , LineTotal FROM Sales.SalesOrderDetailEnlarged |
The execution plan of the query gives the detail of why it can’t generate a parallel execution plan. However, if you see a message like CouldNotGenerateValidParallelPlan, it’s related to your SQL Server version because with SQL Server 2022 these messages become more understandable.
Summary
In this article, we made SQL practice that may ask in the technical interviews of the SQL jobs and review some major topics of the SQL Server. We should not forget that preparing for technical interviews will always put us one step ahead of other candidates.
See more
ApexSQL Complete is a SQL code complete tool that includes features like code snippets, SQL auto-replacements, tab navigation, saved queries and more for SSMS and Visual Studio


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023