

The idea behind this article is to discuss the importance and the implication of SQL Partition and understand the SQL truncate command partitioning enhancements in SQL 2016
One of the biggest challenges for a DBA is to identify the right candidate for table partitioning, as it requires expertise in design and implementation.
The following are the various truncating options available in SQL 2016
- Truncate individual partitions
- Truncate multiple individual partitions
- Truncate a Range of partitions
- Truncate a Range with multiple individual partitions
Article Highlights
- Define the importance and the implication of SQL table partitioning
- Identify the right candidate for table partitioning
- Provide inline comparison of features available in the different editions of SQL 2016
- Discuss the SQL truncate partition enhancements in SQL 2016
- Demonstrate the SQL truncate table partition use cases
SQL Partition
Let’s understand the objective of SQL partitioning, why we need partitioning, and the factors that are vital to decide on a Table Partitioning Strategy.
Partitions are logical mapping of the physical data. A well-designed partition gives us an option to scale out the data. It optimizes the performance and simplifies the management of data by partitioning each table into multiple separate partitions. Although, not all tables are good candidates for partitioning. If the answer is ‘yes’ to all or most of the following questions, table partitioning may be a viable database design strategy; if the answer is ‘no’ to most of the following questions, table partitioning may not be the right solution for that table.
- Is the table large enough?
Large fact tables are good candidates for table partitioning. If we have millions or billions of records in a table, we may see performance benefits from breaking that data up into logically smaller chunks. Since smaller tables are less susceptible to performance problems, the administrative overhead of maintaining the partitions will outweigh any performance benefits we might see by partitioning. - Does your application or system maintain a window of historical data?
Another consideration for partition design is your organization’s data retention policy. For example, your data warehouse may require that you keep the data from the past twelve months. If the data is partitioned by month, you can easily drop the oldest monthly partition from the warehouse and load current data into the most recent monthly partition. - Are you experiencing performance issues on database maintenance tasks?
As we deal with larger tables, it is more difficult to perform the rebuilding operations. In such scenarios, one can rely on table partitioning, so that maintenance operations can be seamlessly performed. - Can the data be divided into equal parts based on a certain criteria?
Choose the partition criteria that will divide the data as evenly as possible. This will let the SQL Query Optimizer to decide and select the best plan for query execution. The monthly partition as mentioned in the second point is a good example for this. - Is concurrency an issue?
Does the system involve a huge volume of data loading and reporting? Are user queries frequently getting locked or blocked? If yes, partitioning could be an option to ease the situation, since the Query Optimizer would be able to handle the execution better.
If someone complains about slowness of a query, it isn’t necessary that the related tables need to be partitioned. In most cases, partitioning would not improve performance. A proper indexing strategy may suffice for some of the performance problems in many such use cases. For instance, if a query is written to use a partition key, then the query execution improves; deterioration in performance may be linked to not using the partition key in this case
The earlier versions of SQL Server required a lot of extra effort in restoring the database with partitioned tables to a non-Enterprise edition of SQL Server. Any attempt to restore resulted in dropping of the Partition Function and the Partition Scheme prior to the database backup and restore process; this is not the case with SQL 2016.
The data truncation/deletion/reshuffling operations had to rely on partition switching and merge mechanism. However, with SQL Server 2016, some interesting features with the truncate command have been introduced, which serve the purpose of data removal with minimal logging.
Feature Support
The Partitioning feature has been an Enterprise edition feature, starting from SQL 2005, but for the first time, it has been made available on all the editions of SQL 2016.
| Feature | Enterprise | Standard | Web | Express with Advanced Services | Express |
|
Table and
Index Partitioning | Yes | Yes | Yes | Yes | Yes |
SQL Truncate table syntax and its usage
SQL TRUNCATE TABLE and using WITH PARTITIONS () option enables the mechanism to truncate the data within the defined partition number(s) or a range of partitions.
|
1 2 3 4 5 6 7 8 9 10 11 |
TRUNCATE TABLE [ { database_name .[ schema_name ] . | schema_name . } ] table_name [ WITH ( PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ) ] [ ; ] <range> ::= <partition_number_expression> TO <partition_number_expression> |
-
Provide partition number , for example:
123TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2));
-
Provide the partition numbers for multiple individual partitions separated by commas, for example:
123TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (1,3,6))
-
Provide both range and multiple individual partitions, for example:
123TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (1,2, 4 TO 6));
-
Using the world TO, partition numbers separated by the word TO, for example:
123TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (4 TO 6));
How and when to use the SQL truncate table with Partition clause?
The following section discusses the scenario of how to use the SQL truncate Table option for data removal for partitioned table
The Quick Archival/Purging process involves switching out the partitions. Though Switch Partition is a metadata update operation and doesn’t involve movement of physical data between the data files, in some cases like high transactional databases, it requires exclusive locks, and this causes the table being blocked for loading and removing the data.
Data purging (deletion) from specific partition or partitions was a tedious task in the previous versions of SQL. Data caused slowness and locked the table, which prevented the users from querying the table; it also ended up using a lot of transaction log space. Prior to SQL 2016, the following steps were performed for data deletion or to remove files from the partition
- Create a new table for switching out with the same definition and clustered index as of the partitioned table
- Switch partition out to the other table
- Alter the Partition function and Partition Scheme to get rid of the file group
- by merging the boundary
- Remove the file group
Note: This is challenging when we deal with a huge number of rows
What about introducing the new SQL TRUNCATE TABLE command in this scenario?
This is a quite seamless and an efficient way to delete the rows from the partitioned table, as it works as a normal SQL Truncate Table operation.
- Execute SQL TRUNCATE TABLE with partition clause
- Execute MERGE command
- Remove the empty filegroup
Demonstration
In SQL Server 2016 we have the feature to truncate data at the partition level. It’s pretty straight forward and simple. Let’s go through the simple steps to show how it works.
Create a sample database powerSQLPartitionTest and add new filegroups. These files are physical representation of SQL data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
DROP DATABASE IF EXISTS powerSQLPartitionTest; GO CREATE DATABASE powerSQLPartitionTest; USE powerSQLPartitionTest GO --The following statements create filegroups to a database powerSQLPartitionTest ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2017] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2018] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2019] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2020] GO ALTER DATABASE powerSQLPartitionTest ADD FILEGROUP [Filegroup_2021] #Add one file to each filegroup so that you can store partition data in each filegroup ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2017’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2017.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2017] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2018’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2018.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2018] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2019’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2019.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2019] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2020’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2020.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB ) TO FILEGROUP [Filegroup_2020] GO ALTER DATABASE powerSQLPartitionTest ADD FILE ( NAME = N’data_2021’, FILENAME = N’f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\data_2021.ndf’, SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 2MB) TO FILEGROUP [Filegroup_2021] GO ---Create Partition Range Function as follows CREATE PARTITION FUNCTION powerSQLPartitionTest_PartitionRange (INT) AS RANGE LEFT FOR VALUES (10,20,30,40,50); GO ----Mapping partition scheme filegroups to the partition range function CREATE PARTITION SCHEME powerSQLPartitionTest_PartitionScheme AS PARTITION powerSQLPartitionTest_PartitionRange TO ([PRIMARY], [Filegroup_2017],Filegroup_2018,Filegroup_2019,Filegroup_2020,Filegroup_2021); GO --Now that there is a partition function and scheme, you can create a partitioned table. The syntax is very similar to any other CREATE TABLE statement except it references the partition scheme instead of a referencing filegroup CREATE TABLE powerSQLPartitionTestTable (ID INT NOT NULL, Date DATETIME default getdate()) ON powerSQLPartitionTest_PartitionScheme (ID); GO --Now that the table has been created on a partition scheme powerSQLPartitionTestTable , populate table using sample data Insert into powerSQLPartitionTestTable (ID) SELECT r_Number FROM ( SELECT ABS(CAST(NEWID() AS binary(6)) %1000) + 1 r_Number FROM master..spt_values) sample GROUP BY r_Number ORDER BY r_Number --- select Data from powerSQLPartitionTestTable SELECT * FROM powerSQLPartitionTestTable; GO --Next we can use $PARTITION function to retrieve row counts For each partition: SELECT $PARTITION.powerSQLPartitionTest_PartitionRange(ID) AS PARTITIONID, COUNT(* ) AS ROW_COUNT FROM dbo.powerSQLPartitionTestTable GROUP BY $PARTITION.powerSQLPartitionTest_PartitionRange(ID) ORDER BY PARTITIONID SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO --SQL Truncate individual Partition TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2)); SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 8 9 |
--SQL Truncate Multiple individual Partition TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (1,3)) GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 8 9 |
--Range of Parititions TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (4 TO 6)); GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 4 5 6 7 8 9 |
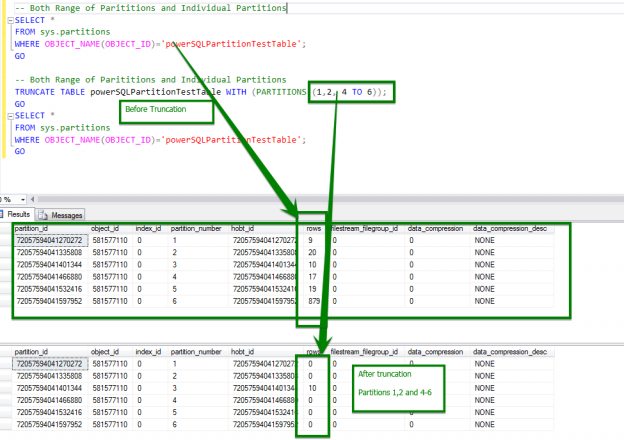
-- Both Range of Parititions and Individual Partitions TRUNCATE TABLE powerSQLPartitionTestTable WITH (PARTITIONS (1,2, 4 TO 6)); GO SELECT * FROM sys.partitions WHERE OBJECT_NAME(OBJECT_ID)=’powerSQLPartitionTestTable’; GO |

|
1 2 3 |
--Remove files from Partitioned table using truncate enhancement |
The below SQL gives SQL partition internal details
|
1 2 3 4 5 6 7 |
SELECT $PARTITION.powerSQLPartitionTest_PartitionRange(ID) AS PARTITIONID, COUNT(* ) AS ROW_COUNT FROM dbo.powerSQLPartitionTestTable GROUP BY $PARTITION.powerSQLPartitionTest_PartitionRange(ID) ORDER BY PARTITIONID |

|
1 2 3 |
--The filegroup_2017 is ready for data deletion by using SQL truncate command |

|
1 2 3 4 |
--SQL Truncate individual Partition TRUNCATE TABLE dbo.powerSQLPartitionTestTable WITH (PARTITIONS (2)); |

Now, the filegroup_2017 is empty and ready for removal. Make sure the dependency is broken from every part of its usage. Once done, merge the boundary point this will remove the entry from Partition Function
|
1 2 3 4 |
--Merge the range in order to get rid of the data filegroup_2017 ALTER PARTITION FUNCTION powerSQLPartitionTest_PartitionRange() MERGE RANGE (200); |

|
1 2 3 |
ALTER DATABASE powerSQLPartitionTest REMOVE FILE data_2017 |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--Online Index Maintenantenance on ALL Paritions ALTER INDEX PK_powerSQLPartitionTestTable_IDX ON [dbo].powerSQLPartitionTestTable REBUILD PARTITION = ALL WITH (ONLINE= ON); --Online Index Maintenantenance on Parition 3 ALTER INDEX PK_powerSQLPartitionTestTable_IDX ON [dbo].powerSQLPartitionTestTable REBUILD PARTITION = 3 WITH (ONLINE= ON); |

Conclusion
This article details the use of Partitioning in SQL Server and the factors which are vital for considering before partitioning a table. It also outlines the use of the SQL truncate table partition enhancement. With SQL Server 2016, one can plan for a better index maintenance and data management strategies.
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021