
In this post, I continue the exploration of SQL Server 2017 and we will look at the nonclustered columnstore index updates.
Columnstore index has some internal structures to support updates. In 2014 it was a Delta Store – to accept newly inserted rows (when there will be enough rows in delta store, server compresses it and switches to Columnstore row groups) and a Deleted Bitmap to handle deleted rows. In 2016 there are more internal structures, Mapping Index for a clustered Columnstore index to maintain secondary nonclustered indexes and a deleted buffer to speed up deletes from a nonclustered Columnstore index.
Updates were always split into insert + delete. But that is now changed, if a row locates in a delta store, now inplace updates are possible. Another change is that it is now possible to have a per row (narrow) plan instead of per index (wide) plan.
Let’s make some experiments.
I will create a table, insert 100 000 rows into it and then create a nonclustered Columnstore index. All the rows will go to the compressed row group. After that, I insert one more portion of 100 000 rows, that is not enough to go directly to a compressed row group, so a delta store will be created and the new rows will go to it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
use opt; go -- Creating a table drop table if exists dbo.Orders; create table dbo.Orders(OrderID int, CustomerID int, OrderDate datetime, Note varchar(max)); go -- Inserting 100 000 rows with cte as (select top(100000) rn = row_number() over(order by (select null)) from sys.all_columns c1, sys.all_columns c2) insert dbo.Orders(OrderID, CustomerID, OrderDate, Note) select rn, rn%10000, dateadd(dd, rn%10000, '20161201'), replicate('a', 8001) from cte ; go -- Creating nonclustered columnstore index, and all the rows are compressed and goes to compressed row groups create nonclustered columnstore index ncci on dbo.Orders(OrderID, CustomerID, OrderDate); go -- Inserting 100 000 rows, all these goes go to delta store with cte as (select top(100000) rn = row_number() over(order by (select null)) from sys.all_columns c1, sys.all_columns c2) insert dbo.Orders(OrderID, CustomerID, OrderDate, Note) select rn+100000, rn%10000, dateadd(dd, rn%10000, '20161201'), replicate('a', 8001) from cte ; go -- Check that we have two row groups, compressed and delta store select * from sys.column_store_row_groups where [object_id] = object_id('dbo.Orders') |
The result is:

Note: Notice, that I created a varchar(max) column in a table, that was done deliberately, because I wanted to test if LOB columns are supported in 2017. Unfortunatelly, when I tried to create a nonclustered Columnstore index, I got an error:
The statement failed. Column ‘Note’ has a data type that cannot participate in a columnstore index. Omit column ‘Note’.
However, if you create a clustered Columnstore, you will succeed! Though, you will get the following warning in CTP 1.2:
Warning: Using Lob types (NVARCHAR(MAX), VARCHAR(MAX), and VARBINARY(MAX)) with Clustered Columnstore Index is in public preview. Do not use it on production data without backup during the public preview period.
I think it is great that we can now have LOB varchar columns in Columnstore, because it was a blocker for some scenarios, at least I have seen some of those.
Now, let’s look at the update plans under compatibility level of SQL Server 2016 (130) and SQL Server 2017 (140):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
-- SQL Server 2016 alter database opt set compatibility_level = 130; go set showplan_xml on; go update o set o.OrderDate = getdate() from dbo.Orders o where o.OrderID = 100001; go set showplan_xml off; go -- SQL Server 2017 alter database opt set compatibility_level = 140; go set showplan_xml on; go update o set o.OrderDate = getdate() from dbo.Orders o where o.OrderID = 100001; go set showplan_xml off; go |
The plans are:

The first plan is a per index plan, that means that a server will apply changes in each index one after another separately. The second plan is a per row plan, and the changes are done in one iterator. Usually, if a small portion of rows is updated, the per row plan is cheaper and more convenient.
We can see, that in 2017 the per-row narrow plan is now possible.
Next, we will check the in-place updates for delta stores. That means that an update operator should not be split as insert + delete, but rather done in place as a single update.
We will issue an update of the delta store row (OrderID > 100000) and then query transaction log, to see, what is done, was it an insert + delete or update. We do this first under compatibility level 2016 and then under 2017.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
-- Switch to simple recovery mode alter database [opt] set recovery simple with no_wait; go -- SQL Server 2016 alter database opt set compatibility_level = 130; go checkpoint; go update o set o.OrderDate = getdate() from dbo.Orders o where o.OrderID = 100001 option(maxdop 1); go go select Operation, Context, AllocUnitName from fn_dblog(null,null) l where AllocUnitName like 'dbo.Orders%'; go -- SQL Server 2017 alter database opt set compatibility_level = 140; go checkpoint; go update o set o.OrderDate = getdate() from dbo.Orders o where o.OrderID = 100002 option(maxdop 1); go go select Operation, Context, AllocUnitName from fn_dblog(null,null) l where AllocUnitName like 'dbo.Orders%'; go |
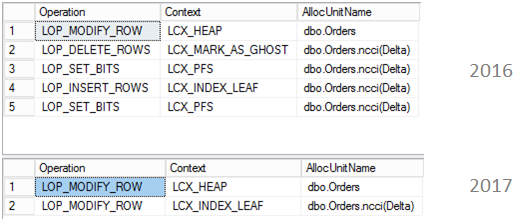
The result is:

You may see, that in case of 2016 there was first LOP_MODIFY_ROW for a base table which is a heap and then LOP_DELETE_ROWS and LOP_INSERT_ROWS for a delta store of dbo.Orders (function fn_dblog is very user friendly and even adds “(Delta)” for an allocation unit name, cool)!
In case of 2017, there are just two operations, both of them are LOP_MODIFY_ROW, one for a base heap and one for a delta store.
What I like about it, is that it is one of the additions that you get out of the box simply by upgrading to a newer version (when there will be an official RTM), as Microsoft used to say – it just runs faster. You have less pressure on transaction log and you save CPU instructions doing one operation instead of two, which, I believe, is quite important for the real-time analytics.
If you change the OrderID to the value that is stored in a compressed row group and run it (two times, to exclude PFS and GAM page actions when the deleted buffer is created for the first row), you will see that for a compressed row groups nothing is changed:

That’s all for today, but stay tuned, there are some more interesting query processing related things in 2017 to be covered.
Thank you for reading.
Table of contents

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018