

In this article, we will explain batch mode on rowstore feature, which was announced with SQL Server 2019. The main benefit of this feature is that it improves the performance of analytical queries, and it also reduces the CPU utilization of these types of queries. Behind the scene, this performance enhancement uses the batch mode query processing feature for the data, which is stored in row format. Also, this feature has been using by columnstored indexes for a long time.
Columnstore indexes have been announced with SQL Server 2012, and it offers two main benefits to us. These are:
- Reducing the I/O activity of the query due to using columnstore index structure
- More efficient CPU usage through the batch mode execution query processing method
However, using columnstore indexes is not well-suited for the OLTP database usage scenarios that are getting high Update and Delete workload because columnstore index usage adds extra overhead to the Delete and Update operations. For this reason, we need a way out that does not affect the performance of the Delete and Update operations, and it also improves the performance of the analytical queries. Using analytical queries and operational requirements at the same time is certainly a long-accepted approach.
The solution has come with SQL Server 2019 for these issues. Batch mode execution on the rowstore feature can solve these types of issues because it has multiple row handling capabilities at the same time instead of the traditional row-by-row processing method.
Before going through details of the batch mode on rowstore, we will take a glance at the batch mode execution.
Batch mode execution
Batch mode execution is a query processing method, and the advantage of this query processing method is to handle multiple rows at a time. This approach gains us performance enhancement when a query performs aggregation, sorts, and group-by operations on a large amount of data. Now we will analyze the following execution plan:
|
1 2 3 |
SELECT ModifiedDate,CarrierTrackingNumber, SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged GROUP BY ModifiedDate,CarrierTrackingNumber |

This clustered index scan operator execution mode is the row, and it handles the rows one by one. The following execution plan illustrates the execution plan of the same query, but the clustered index has replaced with the clustered columnstore index:

In this execution plan, we can see that the batch mode query processing had been performed by the columnstore index scan operator. The dramatic performance difference between row mode and batch mode query processing in terms of the CPU times can be seen. Batch mode query processing can boost the performance of the analytical queries because it processes multiple rows at once. This is the main idea behind the batch execution mode query processing method. In the next sections, we will learn how this mechanism works for the data where is stored in row structure.
Pre-requirements
In the following examples, we will use the AdventureWorks sample database. At first, we will switch compatibly level to 150, so we will be able to take advantage of all the features of the SQL Server 2019.
|
1 |
ALTER DATABASE AdventureWorks2008R2 SET COMPATIBILITY_LEVEL = 150 |
On the other hand, we should work large tables to perform straightforward examples. For this reason, we will use an enlarging script (Create Enlarged AdventureWorks Tables ), which helps to create a large amount of data. This script is going to create the SalesOrderDetailEnlarged and SalesOrderHeaderEnlarged tables under the Sales schema:

Batch Mode on RowStore
As we mentioned, the batch mode query processing method is boosting the performance of the analytical queries. With SQL Server 2019, we can take advantage of this option for the tables that do not contain any columnstore indexes. The batch mode on rowstore feature can be enabled by switching the database to the latest compatibility level, which is 150.
Now we will execute the following query and enable the actual execution plan:
|
1 2 3 |
SELECT ModifiedDate,CarrierTrackingNumber , SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged GROUP BY ModifiedDate,CarrierTrackingNumber |
The BatchModeOnRowStoreUsed property can be seen as true on the Select operator properties. This property specifies at least one of the execution plan element have performed batch mode query processing for the rowstore data:

When we look at the property of the clustered index scan operator, we will see that the execution mode property is Batch, so it indicates this operator process data using the batch mode:

At this point, we should draw attention to the batch number in the execution plan. 5.259 batches have been executed by the clustered index scan operator, and it has handled 4.731.363 rows. Therefore, processing about 900 rows per batch will be more effective than handling row by row.
At the same time, these batch executions have been acted by the separated threads. If we expand the Actual Number of Batches option we can find out how many batches have been executed by the individual threads:

We can disable batch mode on rowstore option to using DISALLOW_BATCH_MODE hint. When we execute the following query, the query optimizer does not decide to use the batch mode on rowstore option:
|
1 2 3 4 |
SELECT ModifiedDate,CarrierTrackingNumber , SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged GROUP BY ModifiedDate,CarrierTrackingNumber OPTION(USE HINT('DISALLOW_BATCH_MODE')) |

At the same time, we can disable the batch mode feature at the database level. The BATCH_MODE_ON_ROWSTORE option can be applied at the database level and disable the batch mode on rowstore feature:
|
1 |
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = OFF |
The following query re-enables the batch mode on rowstore:
|
1 |
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON |
We should consider that this feature is still only enabled for the SQL Server 2019 Enterprise edition.
Performance test: Batch mode execution vs Row mode execution
In this test, we will compare the CPU utilization of the batch mode query processing against row mode for the same query.
The convenient and simple way to measure the CPU utilization of a query is to enable the SET STATISTICS TIME option. To test queries on a cold buffer cache environment, we will use the DROPCLEANBUFFERS statement.
Thus, we will create equal conditions for these two queries.
Note: DROPCLEANBUFFERS option should not be executed on the production servers if you don’t have enough knowledge background of this statement.
At first, we are going to execute the following query which process rows on the batch mode:
|
1 2 3 4 5 6 7 |
SET STATISTICS TIME ON GO DBCC DROPCLEANBUFFERS GO SELECT ModifiedDate,CarrierTrackingNumber , SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged GROUP BY ModifiedDate,CarrierTrackingNumber |

We will parse this output with Statistics Parser to convert to more meaningful reports:

For the following query, we will disable batch mode on the rowstore feature and execute the query:
|
1 2 3 4 5 6 7 8 |
SET STATISTICS TIME ON GO DBCC DROPCLEANBUFFERS GO SELECT ModifiedDate,CarrierTrackingNumber , SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged GROUP BY ModifiedDate,CarrierTrackingNumber OPTION(USE HINT('DISALLOW_BATCH_MODE')) |


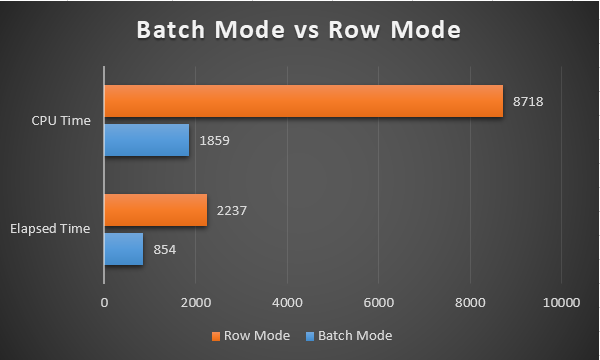
The following chart represents the graphical illustration of the performance results on the SQL Server 2019 environment:

It seems that, obviously, batch mode query processing has outstanding performance against row mode query processing. The batch mode CPU utilization is nearly 4 times lower than the row mode. Batch mode elapsed time is also 2.5 times lower than the row mode.
Normally the elapsed time should be greater than the CPU time, but for these queries, it is just the opposite. The reason for this absurd case is very simple; the query optimizer decided to use parallel execution plans for these queries. In the parallel execution plans, the CPU time indicates the cumulative total value of the separated threads CPU time values:

Tip: Adaptive Joins
In the execution plans, the query optimizer chooses different joining algorithms to connect the rows of the different tables. However, if the query optimizer uses the batch execution mode, it also considers using adaptive join type. The main benefit of this join operator is that it decides to a join method dynamically on the runtime according to the row count threshold. These join methods can be hash or nested join algorithms. Now we will execute the following query and look at the execution plan:
|
1 2 3 4 5 6 |
SELECT ProductID,SUM(LineTotal) , SUM(UnitPrice) , SUM(UnitPriceDiscount) FROM Sales.SalesOrderDetailEnlarged SOrderDet INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID GROUP BY ProductID |

For this execution plan, the row number crosses Adaptive Threshold Rows value, so it has performed the hash join method.
“You can see the article SQL Server 2017: Adaptive Join Internals for more details about the adaptive joins”
Conclusion
In this article, we learned batch mode on rowstore feature, which was introduced with the SQL Server 2019. This feature provides performance improvements for the analytical queries and reduces CPU utilization. However, the main advantage of this feature is not required for any code replacing for the queries or the application sides. As the last sentence, if we want to take advantage of the batch mode query processing for the lower versions of the SQL Server, this Batch Mode Hacks for Rowstore Queries in SQL Server article might be helpful to overcome this issue.
See more
Check out SpotLight, a free, cloud based SQL Server monitoring tool to easily detect, monitor, and solve SQL Server performance problems on any device


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023