
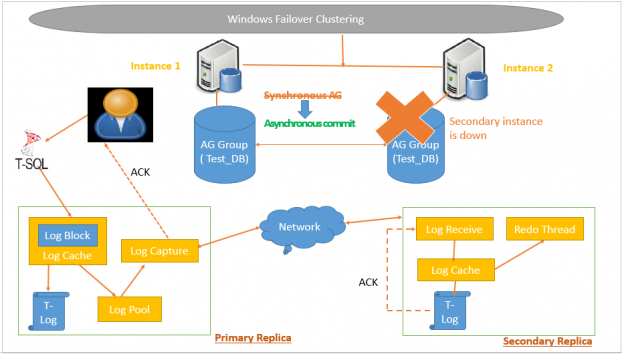
In my previous article Data Synchronization in SQL Server Always On Availability Group, we described a scenario where if a secondary replica goes down in synchronous data commit mode, SQL Server Always on Availability group changes to asynchronous data commit mode. It ensures that users can get their transaction commit irrespective of waiting for a secondary replica to come online.

In this article, we will explore the following scenario related with SQL Server Always on Availability group.
- Synchronous Secondary Replica resynchronization process SQL Server Always on Availability Group
- Automatic failover in case of Primary Replica goes down
- Manual planned Failover
- Force Manual failover with data loss
Synchronous Secondary Replica resynchronization process SQL Server Always on Availability Group
Suppose we have three SQL Always On replicas as follows.
- Two replicas in DC having synchronous data commit
- One replica is DR having asynchronous data commit

In the following screenshot, we can see two nodes are down. I have stopped SQL services on both secondary replicas (RDP to replica server and Open SQL Server Configuration Manager and stop SQL Service)
- Synchronous data commit – Down, It switches to Asynchronous data commit
- Asynchronous data commit – Down

Once the secondary synchronous data replica is offline, it switches database status to Not Synchronizing. In this mode, Primary replica does not wait for the acknowledgement from the secondary replica.
In the following screenshot, we can see that the status of both secondary replicas is Not Synchronizing.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT CASE r.replica_server_name WHEN 'ABC' THEN 'Primary Replica' WHEN 'XYZ' THEN 'Secondary DC Replica' ELSE 'Secondary DR Replica' END AS Replica, adc.database_name, drs.is_local, drs.is_primary_replica, drs.synchronization_state_desc, drs.is_commit_participant, drs.synchronization_health_desc, drs.recovery_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_databases_cluster AS adc ON drs.group_id = adc.group_id AND drs.group_database_id = adc.group_database_id INNER JOIN sys.availability_groups AS ag ON ag.group_id = drs.group_id INNER JOIN sys.availability_replicas AS ar ON drs.group_id = ar.group_id AND drs.replica_id = ar.replica_id ORDER BY Replica; |

In the following query, we use DMV sys.dm_hadr_database_replica_states to get details about LSN on primary and secondary replica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT CASE r.replica_server_name WHEN 'ABC' THEN 'Primary Replica' WHEN 'XYZ' THEN 'Secondary DC Replica' ELSE 'Secondary DR Replica' END AS Replica, rs.is_primary_replica IsPrimary, rs.last_received_lsn, rs.last_hardened_lsn, rs.last_redone_lsn, rs.end_of_log_lsn, rs.last_commit_lsn FROM sys.availability_replicas r INNER JOIN sys.dm_hadr_database_replica_states rs ON r.replica_id = rs.replica_id ORDER BY replica; |
In SQL Server Always on Availability Group, we can use last_commit_lsn to check the commit LSN on all the available nodes. We can see that end_of_log_lsn is similar when the always on the group were in a synchronized state.

Now, connect to primary replica and do some DML transactions. It generates transaction log records, but those records could not be sent to secondary replica because of their unavailability.
Again execute the query to check last_commit_lsn. We can see that the primary replica is ahead of the secondary replica. You can also check end_of_log_lsn column, and it indicates the last log LSN on respective replicas.

Bring the services online (take RDP to corresponding replica server and Open SQL Server Configuration Manager and Start SQL Service). Once the SQL Services are up on secondary replica, it establishes a connection with the primary replica. Secondary replica sends end_of_log_lsn to the primary replica. Previously we noticed that SQL Server Always on Availability Group changes to the asynchronous mode and commit the records in primary replica only. It commits the transactions but does not truncate the logs until a secondary replica is in sync again. Primary replica sends all transaction blocks starting from end_of_log_lsn to secondary replica.

Secondary replica receives these transaction blocks and hardens those transactions. Data Synchronization mode is still asynchronous. It also changes synchronization state from Not Synchronizing to Synchronizing.
The secondary replica sends an acknowledgement for transaction blocks and keeps doing this process until last_hardened_lsn of both primary and secondary replica is the same.

At this point, SQL Server Always on Availability group data synchronization changes to synchronous data commit from Asynchronous data commit.
Note: Asynchronous data commit mode remains the same. It does not change to synchronous data commit automatically. SQL Server again starts waiting for the acknowledgement from secondary replica for all transactions.
We have one secondary DR replica as well. In this case, the first connection gets established between primary and secondary replica and Primary replica send transaction log after end_of_log_lsn of the secondary replica. It changes the status to synchronizing from not synchronized.


Automatic failover in case of Primary Replica goes down
We can achieve automatic failure in case of loss of primary replica. Automatic failover could occur in case of synchronous data commit only.
In SQL Server 2012 and 2014, if the primary instance is available and healthy, it does not perform automatic failover. It does not check the individual database in an availability group. In SQL Server 2016, we can have availability group health monitoring as well. We can configure that if a database in an availability group becomes unavailable, it can also trigger an automatic failover.
Automatic failover Steps
- SQL Server Always On Availability group status for primary replica changes to Disconnected from Synchronized
- Secondary replica starts taking Primary role in Availability group. It rolls forward any pending transactions in the recovery queue and hardens them
- The secondary replica works as a new primary replica. It rolls back any uncommitted transactions and database become available for the users. If we are using listener configuration in Always On, it automatically points all connections to the new primary replica. It also starts asynchronous data commit and commit transactions on Primary replica only
- Later, once the secondary replica becomes available and connects with Primary replica, it follows the steps we explored in the previous section and start data synchronizing process. Once the databases are in sync, new primary replica starts synchronization data commit with the new secondary replica node. It does not do automatic failover again to change the status of an old primary replica (current secondary replica) to the current primary replica
Manual planned Failover
We can perform planned manual failure to secondary transition replica to the primary replica. We can perform planned failover using SSMS or t-SQL.
- Both the primary and secondary replica should be running in synchronous data commit mode
- Status of SQL Server always on availability group databases should be Synchronized
We can check whether the database is ready for manual failover using the is_failover_ready column of sys.dm_hadr_database_replica_cluster_states DMV.
|
1 |
select replica_id ,database_name ,is_failover_ready from sys.dm_hadr_database_replica_cluster_states |
In the following screenshot, we can see the bottom two rows are showing failover ready. It is because we have two replicas in synchronous data commit mode. We have another DR secondary replica in asynchronous data commit mode; therefore, it does not show is_failover_ready value as one for this replica. We should initiate a planned manual failover from the secondary replica.

Manual planned failover actions
- Once a user initiates manual planned failover secondary replica database roll forward pending logs and bring it online
- It also rolls back any uncommitted transactions to keep the database in a consistent state
- Secondary replica takes the role of a new Primary replica and starts to synchronize with the current secondary replica (old primary replica)
- The database status remains NOT SYNCHRONIZING until synchronization happens between primary and secondary replica
- It changes database status to Synchronized
Force Manual failover with data loss
We can do a manual failover to any secondary replica including asynchronous data commit replica. Usually, we should use forced failover for disaster recovery purpose only. Once we initiate a forced failover, the secondary replica takes the role of the new primary replica. In this case, data synchronization does not start automatically. It remains in the suspended state. We need to resume it manually. You might have data loss in case of forced manual failover.
In the following image, you can notice the following
- Secondary replica for synchronous data commit is down
- Due to some issues, the primary replica also goes down. We have now only DR replica available is for configured for asynchronous data commit
- Due to asynchronous data commit, Last_hardended_LSN value is also different on both replicas

Once we initiate forced failover, the secondary replica takes over the role as Primary replica. In this new primary replica, we have Last_hardended_LSN 90. Once we bring old primary replica online, both primary and secondary replica communicates with each other. Since the Last_hardended_LSN value
Once the old primary replica is brought online, it shows its synchronization as suspended is 90 on the primary replica, secondary replica (Last_hardended_LSN – 150) rolls back its transaction to LSN 90 and start the synchronization process. It caused data loss for forced manual failover.

Conclusion
In this article, we explored scenario related to data resynchronization in SQL Server Always on Availability Groups. I will cover more materia related to SQL availability group in the upcoming articles. If you had comments or questions, feel free to leave them in the comments below

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023