
In this article, we will try to find out the answer to the question of “Does a foreign key lead to a deadlock?”
Introduction
In relational databases, foreign keys are used to enforce data integrity between two tables. At its simplest, a foreign key is a column (or set of columns ) that refers to the primary key of another table. The table that holds the foreign key is called the child table, and the table that holds the primary key is called the parent table. Due to this structure of the foreign keys, when we insert a row into the child table, this inserted data must also be verified in the parent table. These extra operations will sometimes reflect as lock issues to us and often lead to deadlock problems. In the next sections of this article, we will explore how a foreign key leads to deadlocks and how we can resolve these types of issues.
Pre-requisites
In this article, we will use Department and Employee tables. The DepId column will be defined as a foreign key in the Employee table; therefore, the newly added data will be checked for its existence in the DepartmentId column of the Department table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE [Department]( [DepartmentId] [int] NOT NULL PRIMARY KEY, [DepartmentName] [varchar](10) NULL, ) GO CREATE TABLE [dbo].[Employee]( [EmployeeId] [int] NOT NULL PRIMARY KEY, [FirstName] [varchar](50) NULL, [LastName] [varchar](50) NULL, [DepID] [int] NOT NULL, [IsActive] [bit] NULL ) ON [PRIMARY] ALTER TABLE [dbo].[Employee] WITH CHECK ADD FOREIGN KEY([DepID]) REFERENCES [dbo].[Department]([DepartmentId]) GO CREATE NONCLUSTERED INDEX [IX_DepId] ON Employee ( [DepID] ASC ) |
What’s happening behind the scene of the Insert statement
In this part of the article, we will go uncover which operations are performed when we insert a row into the child (Employee) table using the query plan.
As a first step, we will insert a sample row into the parent (Department) table.
|
1 2 |
INSERT INTO Department (DepartmentId ,DepartmentName) VALUES (1,'Sales') |
Before executing the following query, we will enable the actual execution plan and insert a row into the Employee (child) table.
|
1 2 |
INSERT INTO Employee (EmployeeId,FirstName,LastName,DepID,IsActive) VALUES(1,'Brandon','Lord',1,0) |

The Clustered Index Insert operator performs the process of adding data to a clustered index and it can also insert data into the non-clustered indexes synchronously. When we look at the Cluster Index Insert operator carefully in the execution plan, we notice that there is not an object name listed on it. The reason for this situation is that when new data is inserted into the Employee table clustered index, at the same time, this new data is inserted into the non-clustered index of the Employee table. The Clustered Index Insert operator tooltip shows these two different index names.

The Clustered Index Seek operator checks the inserted foreign key expression that exists on the parent table.
The Nested Loops compares the inserted foreign key values and the values that return from the index seek. According to this comparison, it returns an output that indicates whether or not a matching row exists.
The Assert Operator evaluates the output of the Nested Loops operator. When the Nested Loops operator returns a null expression, the assert operator evaluates it as 0 and the query returns an error; otherwise, the insert operation will be performed successfully.

How a Foreign Key causes a deadlock?
During the data insert operation of the foreign keys, SQL Server performs some extra operations to validating the inserted data over the parent table. In certain scenarios, such as batch insert operations, this data validation operation can lead to deadlocks if multiple transactions try to process the same data. Now, we will simulate this type of scenario. At first, we will insert some data into the Department table.
|
1 2 3 4 5 6 |
DECLARE @Counter AS INT=1 WHILE @Counter <=10000 BEGIN SET @Counter = @Counter+1 INSERT INTO Department VALUES(@Counter,CONCAT('Column' , @Counter)) END |
As a second step, we will create a global temp table to help insert multiple rows into the Employee table.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE ##Emp (Id INT,EmpFname VARCHAR(50),EmpLname VARCHAR(50),DepId INT,IsActive bit) DECLARE @Counter AS INT=1 DECLARE @RoundNumber AS INT WHILE @Counter <=10000 BEGIN SET @Counter = @Counter+1 SELECT @RoundNumber = ROUND(((10000) * RAND() + 1), 0) INSERT INTO ##Emp VALUES(@Counter,'EmpFname', 'EmpLname',@RoundNumber , 0) END |
We will open two different query windows and then execute the first part of the following queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
--Query-1: --***Part 1***-- BEGIN TRAN INSERT INTO [dbo].Department (DepartmentId,DepartmentName) VALUES (10000,N'Lauren') ---***--- --***Part 2***-- INSERT INTO [Employee] SELECT * FROM ##Emp WITH(NOLOCK) WHERE DepId <=10000 ---***--- |
We will execute the following first part of the following query.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
---Query-2: --***Part 1***-- BEGIN TRAN INSERT INTO [dbo].Department (DepartmentId,DepartmentName) VALUES (10001,N'Lauren') ---***--- --***Part 2***-- INSERT INTO [Employee] SELECT * FROM ##Emp WITH(NOLOCK) WHERE DepId <=9999 ---***--- |
As the last step, we will execute the second part of the queries; as a result, a deadlock has occurred.

Now let’s analyze how this deadlock has occurred:
- The first part of Query-1 opens a transaction and inserts a row into the Department table. The Department table’s data page is locked with an intent exclusive lock (IX) and the inserted row is locked with an exclusive lock (X)
- The first part of Query-2 opens a transaction and inserts a row into the Department table. The Department table’s data page is locked with an intent exclusive lock (IX) and the inserted row is locked with an exclusive lock (X). At this point, no lock issue has occurred
- When we execute the second part of Query-1, it will start to scan the Department table primary keys to verify the newly inserted rows’ referential integrity. However, one row is locked with an exclusive lock by Query-2. In this case, Query-1 must wait until the completion of Query-2
- Query-2 is blocked in its attempt to read the rows that have been inserted into Department by Query-1. Finally, a deadlock has occurred
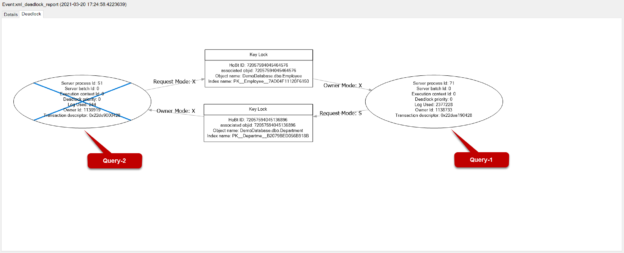
The following deadlock graph illustrates everything as we stated. Session 71 (Query-1) has generated an exclusive (X) lock on the Employee table rows and wants to construct a shared lock (S) on the Department table rows. In spite of that, session 51 has generated an exclusive lock (X) on the Department table rows and wants to construct an exclusive lock (X) on the Employee table rows. As a result, a resource contention occurs between these two sessions, and SQL Server has selected session 51 as a victim and terminates all processes of this session.

Eliminating the Foreign Key Deadlocks
In the previous example, we have simulated that how a foreign key referential integrity verification mechanism causes a lock problem when we perform a bulk insert operation. Actually, this lock issue is related to how a database engine access the parent table data. Looking at the second part of the execution plan of sample queries, we will see a Merge Join operator.
|
1 2 3 |
INSERT INTO [Employee] SELECT * FROM ##Emp WITH(NOLOCK) WHERE DepId <=9999 |

The Merge Join operator is the most effective, but it requires their inputs must be pre-sorted. In our example, the Merge Join operator is required to scan each data of the parent table, but it encounters a locked row and the scan operation cannot complete the scan until the rowlock is released. We can change this data access method of the query to use OPTION (LOOP JOIN). When we use the LOOP JOIN hint, SQL Server query optimizer will generate a different execution plan and it also replaces the MERGE JOIN operator with a NESTED LOOPS operator and Clustered Index Scan operator will be replaced with a Clustered Index Seek operator. With the help of the Clustered Index Seek operator database engine access the parent table data directly so that it is not required to wait any locked row. On the other hand, the NESTED LOOP operator performs line-by-line reading even though the MERGE JOIN operator does a single sequential reading. These two data access method changes reduce the likelihood of a query being blocked by locks in rows in a table that is locked by other operations.
|
1 2 3 4 |
INSERT INTO [Employee] SELECT * FROM ##Emp WITH(NOLOCK) WHERE DepId <=9999 OPTION (LOOP JOIN) |

In this execution plan, Row Count Spool is used to count how many rows are returned from the Clustered Index Seek operator and pass this information into the Nested Loops operator. This operator is used by the SQL Server query optimizer when it is important to check for the existence of rows, but not what data they hold.
Conclusion
In this article, we have learned how a foreign key changes the insert statement query plan and adds some additional operations to its process. At the same time, we have explored that in certain scenarios, foreign keys can lead to deadlocks. To eliminate this type of lock issue, we can use the LOOP JOIN hint.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023