
In the previous articles of this series, we discussed a group of SQL Server Execution Plan operators that you will face when studying the SQL Execution Plan of different queries. We showed the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup and Sort Execution Plan operators. In this article, we will discuss the third set of these SQL Execution Plan operators.
At the beginning, we will implement a testing table with 3K records to be use it in the examples of this article. This demo table is created and filled with data using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
CREATE TABLE ExPlanOperator_P3 ( ID INT IDENTITY(1, 1) ,STD_Name VARCHAR(50) ,STD_BirthDate DATETIME ,STD_Address VARCHAR(MAX) ,STD_Grade INT ) GO INSERT INTO ExPlanOperator_P3 VALUES ( 'AA' ,'1998-05-30' ,'BB' ,93 ) GO 1000 INSERT INTO ExPlanOperator_P3 VALUES ( 'CC' ,'1998-10-13' ,'DD' ,78 ) GO 1000 INSERT INTO ExPlanOperator_P3 VALUES ( 'EE' ,'1998-06-24' ,'FF' ,85 ) GO 1000 |
SQL Server Aggregate Operator – Stream Aggregate
The Aggregate Operator is mainly used to calculate the aggregate expressions in the submitted query, by grouping the values of an aggregated column. The aggregate expressions include the MIN, MAX, COUNT, AVG, SUM operations. Let us run the below SELECT statement that retrieved the top 10 students who got the highest grade. And we will include the Actual SQL Execution Plan of the query. This can be achieved by aggregating the grades of the students to get the maximum grades using the MAX aggregate function. If all information about these top students is required, we should add all these columns in the GROUP BY clause, as shown below:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT TOP 10 ID ,STD_Name ,STD_BirthDate ,STD_Address ,MAX(STD_Grade) FROM ExPlanOperator_P3 GROUP BY ID ,STD_Name ,STD_BirthDate ,STD_Address |
Checking the SQL execution plan generated after executing that query, you will see that the SQL Server Engine will retrieve the rows from the table, then sort these values based on the columns specified in the GROUP BY clause and aggregate these values using the fastest aggregation method, which is the Stream Aggregate Operator. The Stream Aggregate operator is fast due to the fact that it requires the rows to be sorted based on the columns specified in the GROUP BY clause before aggregating these values. If the rows are not sorted in the Seek or Scan operator, the SQL Server Engine will force the use of the SORT operator, as shown below:

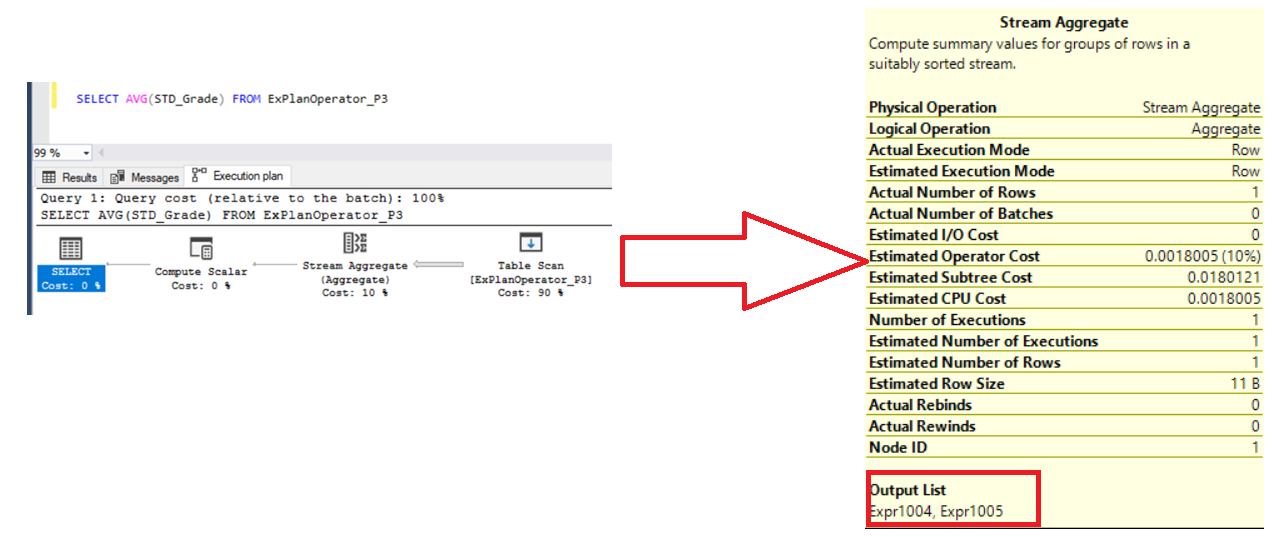
Another example for the Stream Aggregate operator is the AVG aggregate function order, that will compute the SUM and COUNT of the aggregated column and stored the values in Expr1004 and Expr1005 , in order to evaluate the AVG value, as shown below:
SQL Server Compute Scalar Operator
SQL Server Compute Scalar operator is used to calculate a new value from the existing row value by performing a scalar computation operation that results a computed value. These Scalar computations includes conversion or concatenation of the scalar value.
Let us run the below SELECT T-SQL statement to generate a sentence that describes the grade for each student. And we will include the Actual SQL Execution Plan of the query:
|
1 2 |
SELECT STD_Name + '_ has achieved _ ' + cast(STD_Grade AS VARCHAR(50)) AS STD_Result FROM ExPlanOperator_P3 |
You will see from the execution plan, generated after executing the query, that the SQL Server Engine uses the Compute Scalar operator to perform a concatenation for the two specified columns to return a new scalar value, as shown below:

You can see from the previous SQL Execution Plan that the Compute Scalar operator is not an expensive operator, where it only costs 2% of the overall weight of our query, causing a minimal overhead.
SQL Server Concatenation Operator
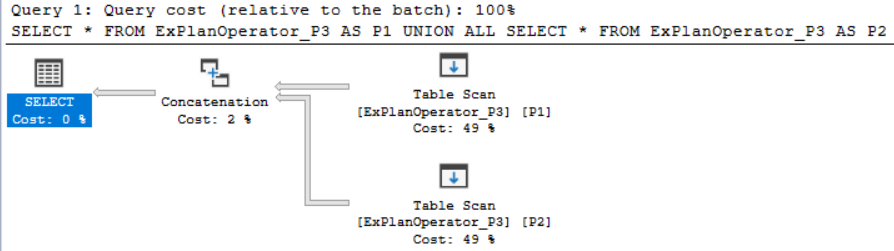
SQL Server Concatenation operator takes one or more sets of data in sequence and returns all records from each input data set. One of the most popular examples of this operator is the UNION ALL T-SQL statement. Let us run the below T-SQL statement that combines the result of two SELECT statement using the UNION ALL statement and we will include the Actual Plan of that query:
|
1 2 3 4 5 6 7 |
SELECT * FROM ExPlanOperator_P3 AS P1 UNION ALL SELECT * FROM ExPlanOperator_P3 AS P2 |
Then checking the Execution Plan generated after executing the query, you will see that the result returned from the two SELECT statements will be concatenated using the Concatenation operator to generate one result set, as showing below:
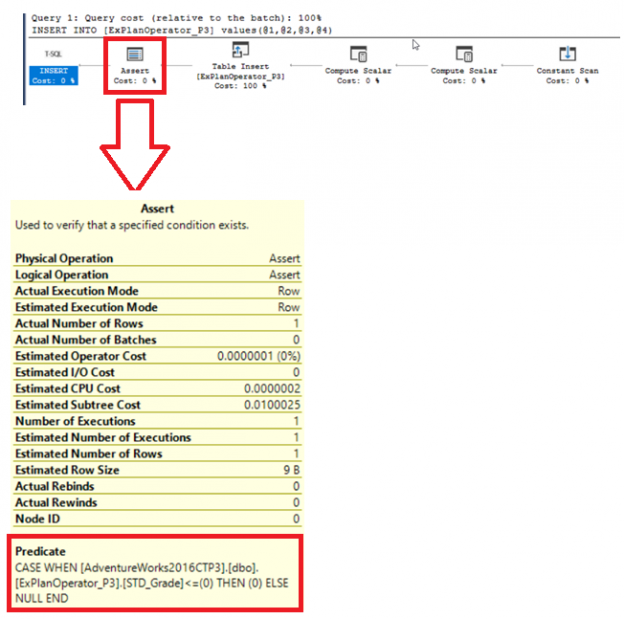
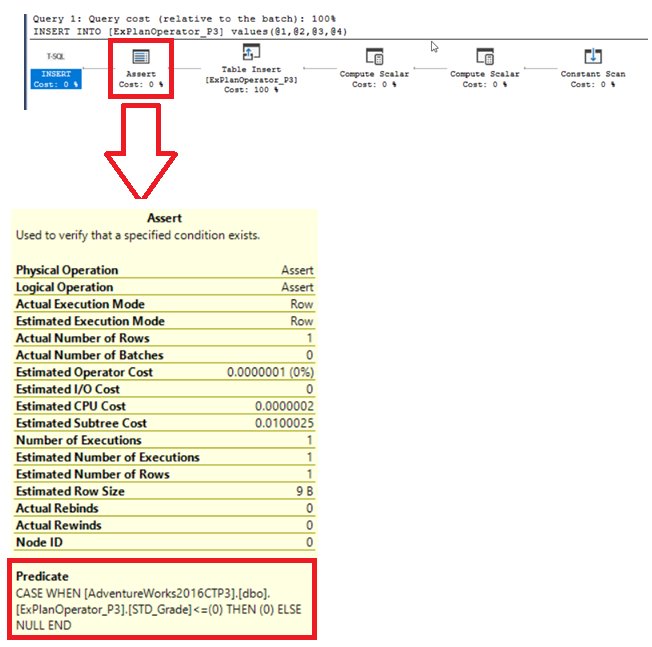
SQL Server Assert Operator
The SQL Server Assert operator is used to verify if the inserted values meet the previously defined CHECK or FOREIGN KEY constraints on the table. Assume that we have defined the below constraint on the demo table to ensure that only positive values are inserted into the STD_Grade column:
|
1 |
ALTER TABLE ExPlanOperator_P3 ADD CONSTRAINT CK_Grade_Positive CHECK (STD_Grade >0) |
If you try to perform the below INSERT statement, including the Actual SQL Execution Plan of the query:
|
1 |
INSERT INTO ExPlanOperator_P3 VALUES ('GG','1998-01-28','HH',74) |
You will see from the SQL Execution Plan generated after executing the query, that the SQL Server Engine uses the ASSERT operator to validate if the inserted grade for that student meets the defined CHECK constraint, as shown below:
SQL Server Hash Match Join Operator
When joining two tables together, the SQL Server Engine divides the tables’ data into equally sized categories called buckets in order to access these data in a quick manner. This data structure is called a Hashing Table. It uses an algorithm to process the data and distribute it within the buckets. This algorithm called a Hashing Function.
Assume that we have created a new table that follows the absence of the students and fill it as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE ExPlanOperator_JOIN ( STD_ID INT ,STD_AbsenceDays INT ) INSERT INTO ExPlanOperator_JOIN VALUES ( 1 ,5 ) GO 100 INSERT INTO ExPlanOperator_JOIN VALUES ( 10 ,2 ) GO 100 |
After that, we will run the below SELECT statement that joins the base Students table with the Absence table, including the Actual SQL Execution plan of that query:
|
1 2 3 4 5 |
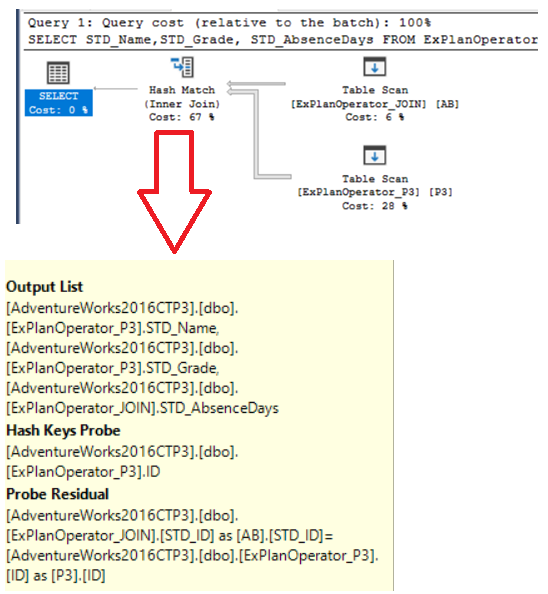
SELECT STD_Name ,STD_Grade ,STD_AbsenceDays FROM ExPlanOperator_P3 P3 INNER JOIN ExPlanOperator_JOIN AB ON P3.ID = AB.STD_ID |
You will see from the Execution Plan generated after executing the query that, after reading data from the two joined table, the SQL Server Engine uses the Hash Match Join operator, in which it fills the hash table with data from the small, also called Probe table, then process the second large table, also called Build table, depending on the hash table values, to speed up the access to the requested data, as shown below:
SQL Server Hash Match Aggregate operator
SQL Server Hash Match Aggregate operator is used to process the large tables that are not sorted using an index. It builds a hash table in the memory, calculates a hash value for each record, then scan all other records for that hash key. If the value is not existing in the hash table, it will create a new entry in that hash table. In this way, the SQL Server Engine will guarantee that there is only one record for each group of data.
Let us run the below SELECT statement that returns the number of duplicates for each ID value. And we will include the Actual SQL Execution Plan of the query:
|
1 2 3 4 |
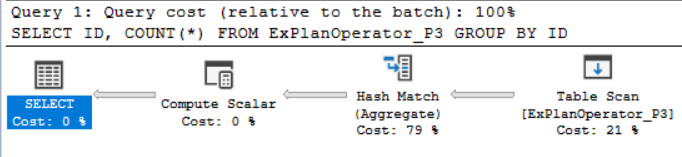
SELECT ID ,COUNT(*) FROM ExPlanOperator_P3 GROUP BY ID |
You will see from the SQL Execution plan generated after executing the query that, the SQL Server Engine will use the Hash Match Aggregate operator to perform and speed up the COUNT aggregation operation, as shown below:
SQL Server Merge Join Operator
SQL Server Merge Join operator is used with the different types of the JOIN operation, but only when the two JOIN data sets are sorted according to the join predicate. In this case, the Merge Join operator will read from the two input data sets at the same time, compare it then return the matched results.
Let us run the below query that joins the ExPlanOperator_P3 table with itself, and include the Actual SQL Execution Plan of the query:
|
1 2 3 |
SELECT * FROM ExPlanOperator_P3 E1 INNER JOIN ExPlanOperator_P3 E2 ON E1.ID = E2.ID |
You will see from the SQL Execution Plan generated after executing the query that, the SQL Server Engine will scan each input, sort the data based on the ID column, as there is no index created on that table yet, then join the two inputs, that are sorted now based on the JOIN predicate using the fast Merge Join operator, as shown below:
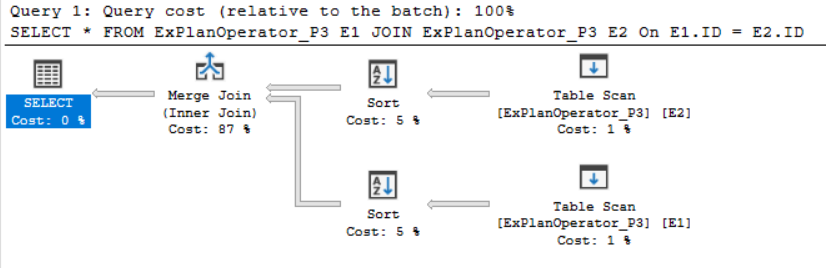
Although the Merge Join operator joins the sorted tables very fact, there still be an overhead, as both inputs will be loaded in memory for comparison purpose. The cost of the Merge Join operator is the sum of the two operator inputs.
SQL Server Nested Loops Join Operator
The SQL Server Nested Loops Operator is used to join the upper input, also known as the outer input, by executing it one time, with the lower input, also known as the inner input, by executing it number of times equal to the number of records that matched the outer input. The SQL Server Query Optimizer decides to use the Nested Loops Join operator only when the outer input table is small, and the inner input table has an index created on the join predicate key.
Assume that we have created the below two indexes on our demo tables, as shown below:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX IX_ExPlanOperator_P3_ID ON ExPlanOperator_P3 (ID) GO CREATE INDEX IX_ExPlanOperator_JOIN ON ExPlanOperator_JOIN ( STD_ID ,STD_AbsenceDays ) WITH (DROP_EXISTING = ON) |
Then run the below SELECT statement that returns the students who missed the classes more than days, by joining the two demo tables together, including the Actual SQL Execution Plan of the query:
|
1 2 3 4 |
SELECT E1.ID FROM ExPlanOperator_P3 E1 INNER JOIN ExPlanOperator_JOIN E2 ON E1.ID = E2.STD_ID WHERE E2.STD_AbsenceDays > 4 |
From the SQL Execution Plan, generated after executing the query, you can see that the SQL Server Engine joins the two tables using the Nested Loops Join operator, but performing an Index Scan operation for the outer input one time then performing an Index Seek operation 100 times for the inner input, as shown below:
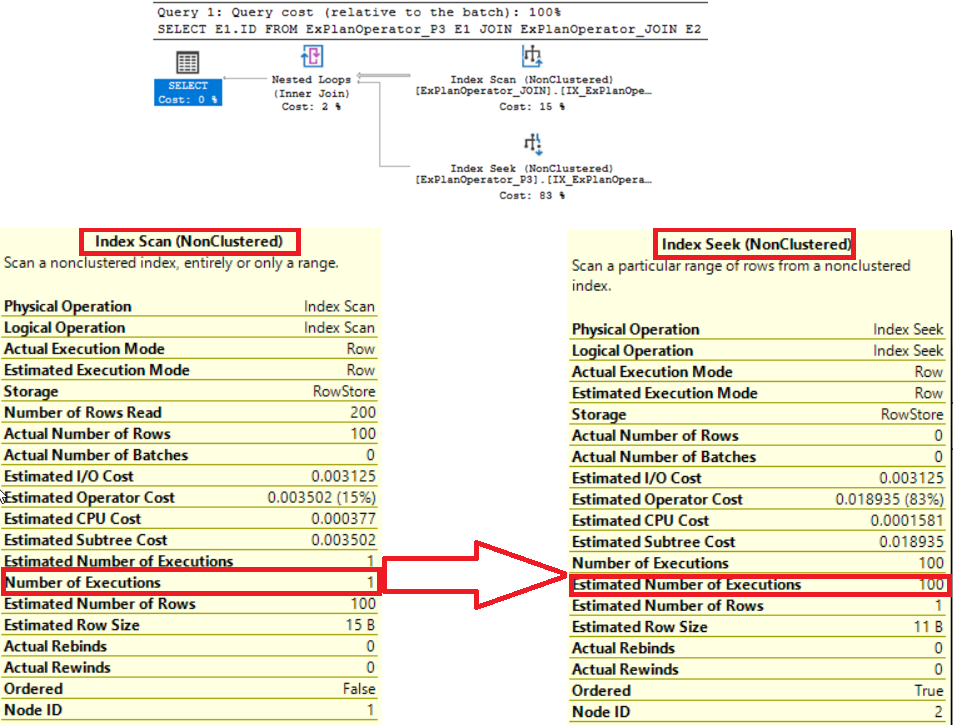
Again, although the cost of the Nested Loops operator is low compared to the overall weight of the query, you need to consider that the cost of that operator is highly depends on the multiplication of size of the outer input table and the size of the inner input table.
Stay tuned for the next article in which we will discuss the fourth set of the SQL Server Execution Plan operators.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021