
In the previous articles of this series, we went through three sets of SQL Server Execution Plan operators that you will meet with while working with the different Execution Plan queries. We described the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup, Sort, Aggregate – Stream Aggregate, Compute Scalar, Concatenation, Assert, Hash Match Join, Hash Match Aggregate , Merge Join and Nested Loops Join Execution Plan operators. In this article, we will dive in the fourth set of these SQL Server Execution Plan operators.
Before listing the fourth set of the SQL Server Execution Plan operators, let us prepare for the practical demos of this article by creating a new table and insert into that table 2K records for testing purposes. The table can be created and filled with the testing data using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE TABLE ExPlanOperator_P4 ( ID INT IDENTITY(1, 1) ,CX_Name VARCHAR(50) ,CX_PhoneNum VARCHAR(50) ,CX_Address VARCHAR(MAX) ,CX_Credit INT ) GO INSERT INTO ExPlanOperator_P4 VALUES ( 'Alen' ,'9625788954' ,'London' ,500 ) GO 1000 INSERT INTO ExPlanOperator_P4 VALUES ( 'Frank' ,'962445785' ,'Germany' ,1400 ) GO 1000 |
SQL Server Segment Operator
SQL Server Segment operators iare used to divide the input data into different groups based on their values. Assume that we run the below SELECT statement that uses the ROW_NUMBER() ranking function to rank the customers regarding their credits, including the Actual SQL Server Execution Plan of the query:
|
1 2 3 4 5 6 7 8 |
SELECT ID ,CX_Name ,CX_PhoneNum ,CX_Address ,ROW_NUMBER() OVER ( PARTITION BY CX_Credit ORDER BY ID ) FROM ExPlanOperator_P4; |
You can see from the generated SQL Server explian plan that, the SQL Server Engine will read all the requested data from the underlying table, sort these values bases on the Credit and ID values then use the Segment operator to partition the customers into groups depending on their credits, as shown in the SQL Server Execution Plan below:

SQL Server Table Spool Operator (Lazy Spool)
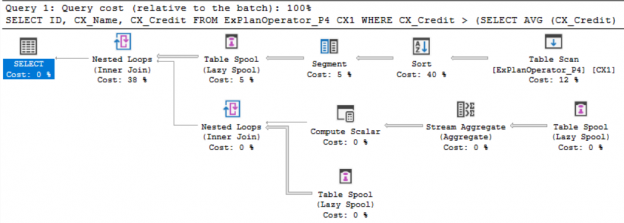
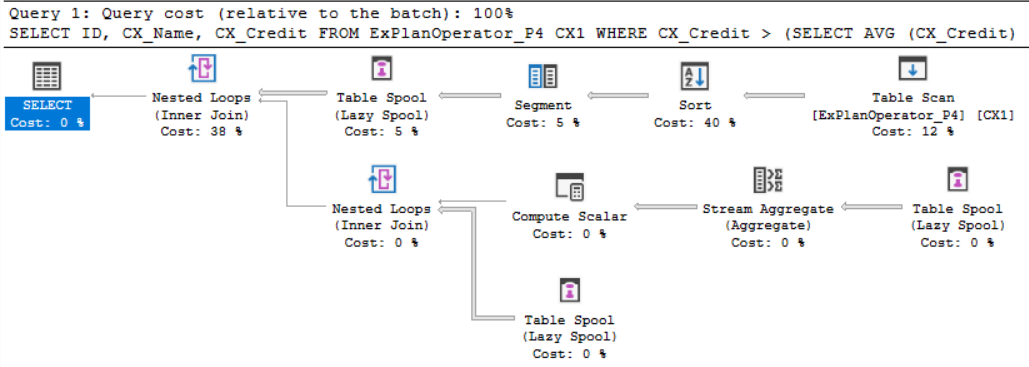
Te SQL Server Lazy Spool is used to build a temporary table on the TempDB and fill it in lazy manner. In other words, it fills the table by reading and storing the data only when individual rows are required by the parent operator. Assume that we run the below query that returns all the customers with credit values greater than the average credit of all customers, using a sub select query that returns the average credit value for comparison and filtration purposes, including the Actual Execution Plan of the query:
|
1 2 3 4 5 6 7 8 9 |
SELECT ID ,CX_Name ,CX_Credit FROM ExPlanOperator_P4 CX1 WHERE CX_Credit > ( SELECT AVG(CX_Credit) FROM ExPlanOperator_P4 CX2 WHERE CX1.ID = CX2.ID ) |
From the generated SQL Server Execution Plan, you can see that the SQL Server Engine reads the data from the table first, sort the data before dividing it into segments, then create a temp table to store the data groups. On the other part of the explain plan, the SQL Server Engine reads from the Table Spool then calculate the average credit value for each group using the Stream Aggregate operator. The last Table Spool operator will read the grouped data and join it to retrieve the values higher than the average value. The three Table Spool operators will use the same temp table created at the first time, as shown in the SQL Server Explain Plan below:
SQL Server Merge Interval Operator
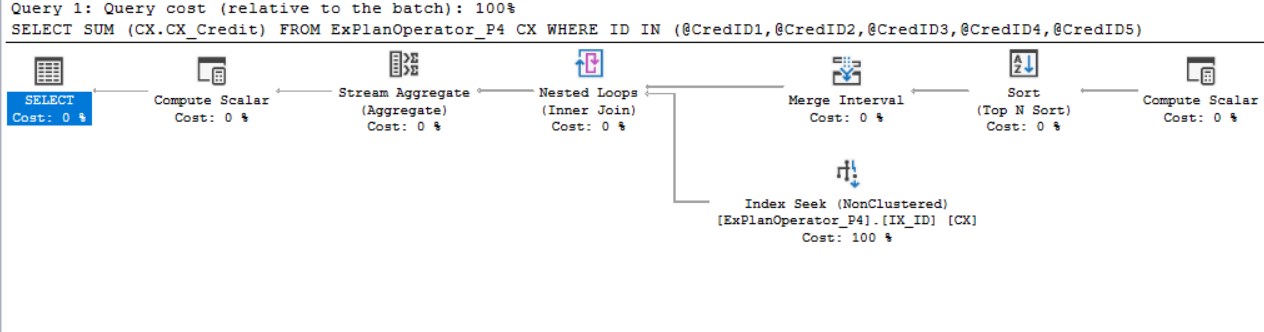
The SQL Server Merge Interval operator is used to perform a DISTINCT query by identifying the overlapping intervals and merge it to generate a non-overlapping interval with no duplicated predicates in a query, in order to avoid scanning the same values more than one time. Assume that we run the below SELECT statement that calculates the sum of the credits for a group of customers, including the Actual Execution Plan of the query, after creating an index on the ID column including the Credit column:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE INDEX IX_ID ON ExPlanOperator_P4 (ID) INCLUDE (CX_Credit) DECLARE @CredID1 INT = 10 ,@CredID2 INT = 20 ,@CredID3 INT = 50 ,@CredID4 INT = 70 ,@CredID5 INT = 90 SELECT SUM(CX.CX_Credit) FROM ExPlanOperator_P4 CX WHERE ID IN ( @CredID1 ,@CredID2 ,@CredID3 ,@CredID4 ,@CredID5 ) |
You can see from the generated SQL Server execution plan, how the SQL Server Engine uses the Merge Interval operator to identify the duplicates and speed up the data comparison and retrieval by performing one index seek operation rather than seeking the same data twice, as shown below:
SQL Server Filter Operator
The SQL Server Filter operator is used to check the input data and return only the data that satisfies the predicate expression. Assume that we run the below SELECT statement that returns the number of duplicate credit values, including the Actual Execution Plan of that query:
|
1 2 3 |
SELECT COUNT(cx_credit) FROM ExPlanOperator_P4 HAVING COUNT(cx_credit) > 5 |
From the generated SQL Server Execution Plan, you can see that the SQL Server Engine uses the Filter operator to return the records that matches the HAVING clause predicate at the last stage, as in the Execution Plan in SQL Server below:

SQL Server Online Index Insert Operator
When creating an index, SQL Server provides you with the ability to create or alter that index online, without preventing the clients from connecting to the underlying table during the index creation process. The SQL Server Online Index Insert operator is used for creating or altering the index online.
For more information about the index creation options, see the article SQL Server index operations.
Assume that we run the below CREATE INDEX T-SQL statement, including the Actual Execution Plan of the query:
|
1 2 3 4 5 |
CREATE INDEX IX_ID ON ExPlanOperator_P4 (ID) INCLUDE (CX_Credit) WITH ( DROP_EXISTING = ON ,ONLINE = ON ) |
The generated SQL Server Execution Plan will show you that, the SQL Server Engine uses the Online Index Insert operator to perform the index creation process online, without holding a lock on the underlying table, as shown below:

SQL Server Sequence Project Operator
The SQL Server Sequence Project operator is the closest friend of the Segment operator, that can be seen when using the ROW_NUMBER (), RANK () or DENSE_RANK() windowed functions. The Sequence Project operator is simply used while classifying the data into groups by adding 1 to the row count column when the Segment operator still working with the same group or resets the counter to 1 when start working with a new group. Let us revisit the same SELECT query that we used as an example for the Segment operator, including the Actual Execution Plan of that query:
|
1 2 3 4 5 6 7 8 |
SELECT ID ,CX_Name ,CX_PhoneNum ,CX_Address ,ROW_NUMBER() OVER ( PARTITION BY CX_Credit ORDER BY ID ) FROM ExPlanOperator_P4; |
The generated Execution Plan will show you the friendship between the Segment and Sequence Project operators, where the Segments will be used to classify the sorted data into groups and the Sequence Project operator will control completing with the current group or start counting with for a new group, as shown below:

SQL Server Eager Spool operator
Te SQL Server Eager Spool operator is used to take all the records passed to it from another operator, read all the data at one time, blocking any access to the data during that one shot read and store it in a temp table in the tempdb database. Let us drop the previously created index on the ID column and replace it with Clustered index on the ID column and Non-Clustered index on the cx_credit column, using the T-SQL script below:
|
1 2 3 4 5 |
DROP INDEX IX_ID ON ExPlanOperator_P4 CREATE CLUSTERED INDEX IX_NEWID ON ExPlanOperator_P4 (ID) CREATE INDEX IX_CX_Credit ON ExPlanOperator_P4 (CX_Credit) |
Then execute the below UPDATE statement to modify the credit of a group if customers, including the Actual Execution Plan of the query:
|
1 2 3 4 |
UPDATE ExPlanOperator_P4 SET cx_credit = cx_credit * 1.075 FROM ExPlanOperator_P4 WITH (INDEX = IX_CX_Credit) WHERE cx_credit >= 900 |
The generated SQL Server Execution Plan will show you that the SQL Server Engine will seek for the requested data in the Non-Clustered index then it will use the Eager Spool operator to read the data from the index and write it to the temp table, blocking the access to that data during the read process, as shown below:

SQL Server Parallelism Operator
SQL Server will manage to execute a query using a parallel plan to speed up the execution of the expensive queries. The decision of using a parallel plan depends on multiple factors, such as whether the SQL Server should be installed on a multi-processor server, the requested number of threads should be available to be satisfied, the Maximum Degree of Parallelism option is not set to 1 and the cost of the query exceeds the previously configured Cost Threshold for Parallelism value. SQL Server performs that using the Parallelism operator. Assume that we run the below command to rebuild the highly fragmented clustered index on out demo table, including the Actual Execution Plan of the query:
|
1 |
ALTER INDEX IX_NEWID ON ExPlanOperator_P4 REBUILD |
You will see from the generated SQL Server Execution Plan that the SQL Server Engine decided to speed up the execution of that heavy query using a parallel plan. This is clear from the existence of the Parallelism operator with yellow arrows identifying that operator, as shown below:

For now, we have covered most of the common SQL Server Explain Plan operators that you will deal with, while working with the Execution Plans in SQL Server. In the next article, we will jump another step in the SQL Server Execution Plans series. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021