

The goal of this article is to throw light on the less-known points about SQL Server statistics.
Introduction
SQL Server statistics are one of the crucial database objects because they are one of the extremely important inputs of the query optimizer. SQL Server statistics stores the distribution of the column values and this statistical data is used by the optimizer to estimate how many rows will return from a query. Based on this estimation optimizer decides query plan operators and performs other required calculations. In short, statistics accuracy plays a critical role in generating an effective query plan.
SQL Server offers three main database-level options to maintain statistics automatically.
Auto Create Statistics
This option allows the generation of new statistics for single columns by the optimizer that does not already have columns values distribution (histogram) data. The reason for this operation is, the optimizer wants to improve the accuracy of the estimated number of rows for the query plan.
Auto Update Statistics
This option allows the optimizer to trigger the update statistics operation when the data modifications reach a threshold, the optimizer decides to update the statistics operation. The query optimizer triggers to update statistics operation when the threshold value meets the following conditions:
- The table row number has gone from 0 rows to more than 0 rows
- The table had 500 rows or less when the statistics were last sampled and has since had more than 500 modifications
- The table had more than 500 rows when the statistics were last updated and the number of row modifications is more than MIN (500 + (0.20 * n), SQRT(1,000 * n) ) formula result after the statistics were last sampled
Auto Update Statistics Asynchronously
When we enable this feature, the optimizer does not trigger to update the statistics during the execution of the query and it uses stale statics. However, the statistics will be updated subsequently by SQL Server.
Unique Indexes and SQL Server statistics
We can use the unique indexes to ensure the singularity for column data. The optimizer does not leverage SQL Server statistical data when data is searched on the unique indexed column through the equals (“=”) operator. Now let’s discover this scenario with a very simple example. At first, we will create a sample table and define a unique index for the col1 column.
|
1 2 3 4 5 6 |
CREATE TABLE TblTestUIndex (Id INT PRIMARY KEY IDENTITY(1,1),Col1 VARCHAR(100),Col2 VARCHAR(100)) CREATE UNIQUE INDEX IX_TestIdex ON dbo.TblTestUIndex (Col1); |
In this step, we will insert only a single row into the table and execute a select query in order to create the statistics.
|
1 2 3 4 5 |
INSERT INTO TblTestUIndex VALUES('Col1','Col2') GO SELECT * FROM TblTestUIndex where Id > 1 and Col1 LIKE 'A%' |
After executing the select statement the statistics will be updated. This situation can be seen using the dm_db_stats_properties view. This view returns three important details about the SQL Server statistics;
- last_updated specifies when the statistic is last updated.
- modification_counter shows the total number of the modifications made since the last statistical update. This number is not affected by the rolled-back changes.
- rows_samples show the total number of rows sampled for statistics calculations.
|
1 2 3 4 5 6 7 8 9 |
SELECT obj.name, obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter ,rows_sampled FROM sys.objects AS obj INNER JOIN sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE obj.name = 'TblTestUIndex' |

Now, we will insert some data into the sample table.
|
1 2 3 4 5 |
INSERT INTO TblTestUIndex SELECT name,type_desc FROM sys.objects GO |

After this operation, we can expect that the statistics will be updated after any read request because the modification counter exceeds the threshold value. However, the following select query does not trigger the statistic update process.
|
1 2 3 |
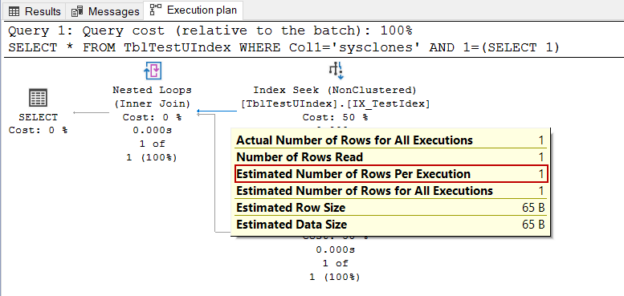
SELECT * FROM TblTestUIndex WHERE Col1='sysclones' AND 1=(SELECT 1) |
Tip: 1=(SELECT 1) expression helps to get rid of the trivial query plans because they prevent updating statistics.
 As we mentioned earlier, an equality condition search in a unique indexed column can return at most one row. The optimizer does not need to use statistics for this type of predicates because the estimation result is constant.
As we mentioned earlier, an equality condition search in a unique indexed column can return at most one row. The optimizer does not need to use statistics for this type of predicates because the estimation result is constant.
Estimated execution plan and SQL Server statistics
Execution plans are used to analyze and diagnose the query performance because the execution plans describe the query compilation and execution steps with all details. SQL Server offers two types of the execution plan:
- Estimated Execution Plan is generated without executing the query.
- Actual Execution Plan is generated after executing the query.
For the specific situations, we can need to analyze an estimated query plan but it may trigger the creation of the statistics behind the scenes during the generation of the estimated plans. Now, we will clarify this scenario with an example. At first, we will create an extended event to monitor which activities occur when an estimated execution plan is created. This event session will involve the following events:
- object_created occurs when a new object is created using CREATE statement
- query_post_compilation_showplan occurs when a SQL statement is compiled
- auto_stats occur when the statistics are being loaded for use by the optimizer.
With the help of the following query, we will create this extended event session. We need to underline one point about this event session, we apply a filter to the session-id field so that we can exclude capturing other irrelevant activities.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE EVENT SESSION EstimatedExecutionPlan ON SERVER ADD EVENT sqlserver.object_created(SET collect_database_name=(1) ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(127))), ADD EVENT sqlserver.query_post_compilation_showplan(SET collect_database_name=(1) ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(172))), ADD EVENT sqlserver.uncached_sql_batch_statistics( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(127))) WITH (STARTUP_STATE=OFF) GO ALTER EVENT SESSION EstimatedExecutionPlan ON SERVER STATE = START |
After creating the event session, we create a new sample table and populate it some data.
|
1 2 3 4 5 6 7 |
CREATE TABLE TestTableStat (Id INT IDENTITY(1,1) ,Col1 VARCHAR(100),Col2 VARCHAR(100)) GO INSERT INTO TestTableStat SELECT name,type_desc FROM sys.objects GO |
Now we will start the event session and then we launch the Watch Live Data screen to view the captured events data in real-time. As the last step, we click the Display Executed Execution Plan for the following query.
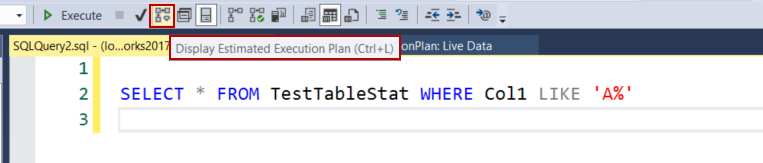
The extended event has captured some events related to this operation. Now let’s interpret what these events indicate.
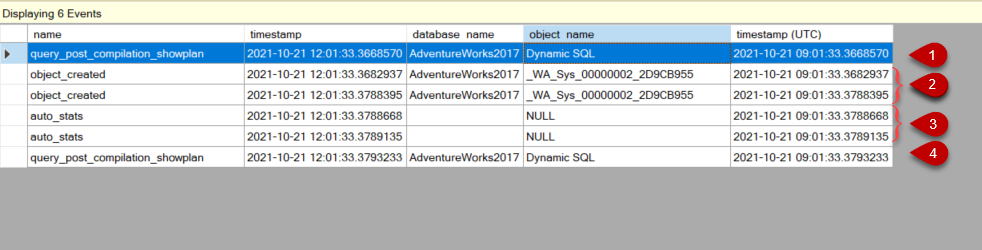
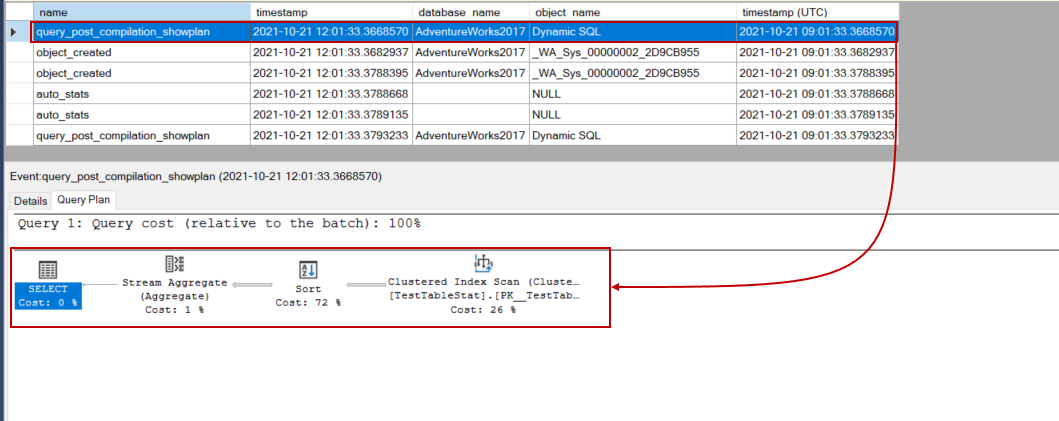
The first event indicates the initial compiled query plan and this query plan does not use any statistics data. When we click the Query Plan, we can see this query plan.
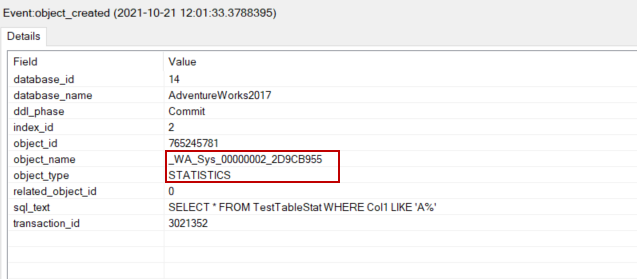
The object_created events show the created statistics details.
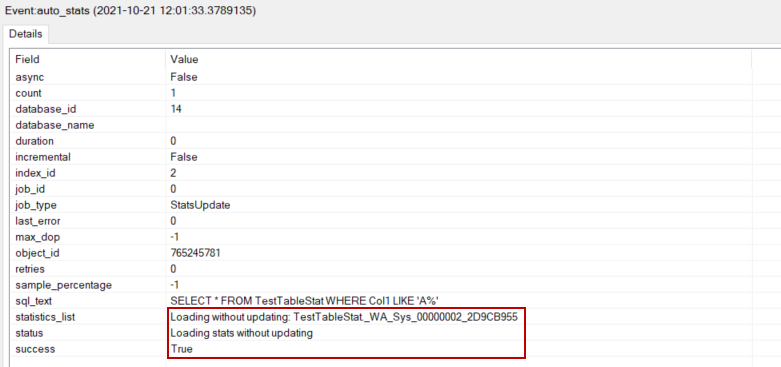
The auto_stats events indicate the statistics are loaded by the optimizer to generate an efficient query plan.
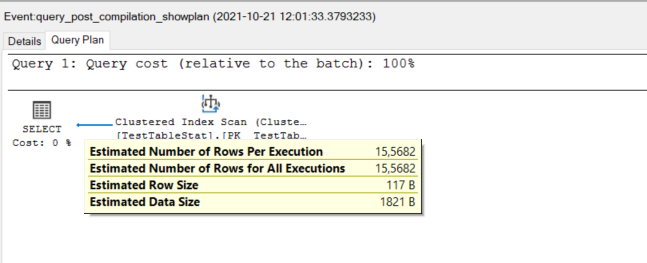
In the final process, the optimizer generates a new query plan using the newly created SQL Server statistics. In this plan, the estimated number of rows is more accurate than the initial query plan because of the freshly created statistics.
SQL Server statistics and ROLLBACK
The ROLLBACK statement is used to revert changes made in a transaction so that all changed data is reverted to what it was before the transaction state. However, change_counter is not affected by these rollbacks and this rollback can be caused to redundant query recompiles. Let’s demonstrate this case with a very simple example.
|
1 2 3 4 5 |
CREATE TABLE TestTableRollBack (Id INT IDENTITY(1,1) PRIMARY KEY ,Col1 VARCHAR(100),Col2 VARCHAR(100)) GO INSERT INTO TestTableRollBack VALUES ('Col1','Col2') |
Step 2: We create a stored procedure and execute it. After executing the stored procedure SQL Server statistics will be updated.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE PROC UProc_RollBack @Param1 AS VARCHAR(100) AS SELECT * FROM TestTableRollBack WHERE Col1 LIKE @Param1 + '%' AND 1=(SELECT 1) AND Id>1 GO EXECUTE UProc_RollBack @Param1 ='K' |

Step 3: In this step, we will insert some rows into the table, and then we undo these changes through the ROLLBACK command. However, this situation increments the modification_counter value of the statistics.
|
1 2 3 4 5 6 |
BEGIN TRAN INSERT INTO TestTableRollBack SELECT s1.name,s2.type_desc FROM sys.objects s1,sys.objects s2 ROLLBACK TRAN |

Step 4: We will create an extended event session that helps to monitor the activities when we execute the sample stored procedure again.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE EVENT SESSION CaptureStoredProcedure ON SERVER ADD EVENT sqlserver.auto_stats(SET collect_database_name=(1) WHERE ([package0].[equal_uint64]([database_id],(14)))), ADD EVENT sqlserver.sp_cache_hit( WHERE ([object_id]=(1581248688))), ADD EVENT sqlserver.sp_cache_insert(SET collect_cached_text=(1),collect_database_name=(1) WHERE ([database_id]=(14))), ADD EVENT sqlserver.sp_statement_completed(SET collect_object_name=(1) WHERE ([package0].[equal_uint64]([source_database_id],(14)))), ADD EVENT sqlserver.sp_statement_starting(SET collect_object_name=(1) WHERE ([package0].[equal_uint64]([source_database_id],(14)))), ADD EVENT sqlserver.sql_statement_recompile(SET collect_object_name=(1),collect_statement=(1) WHERE ([package0].[equal_uint64]([source_database_id],(14)))) WITH (STARTUP_STATE=OFF) GO |
Step 5: Start the extended event session
|
1 2 3 |
ALTER EVENT SESSION CaptureStoredProcedure ON SERVER STATE = START |
Step 6: Open the Watch Live Data screen of the event session.
Step 7: In this last step, we execute our sample procedure with the same parameters, and we discover what is going on behind the scene during the execution of the procedure.
|
1 2 3 |
EXECUTE UProc_RollBack @Param1 ='K' |
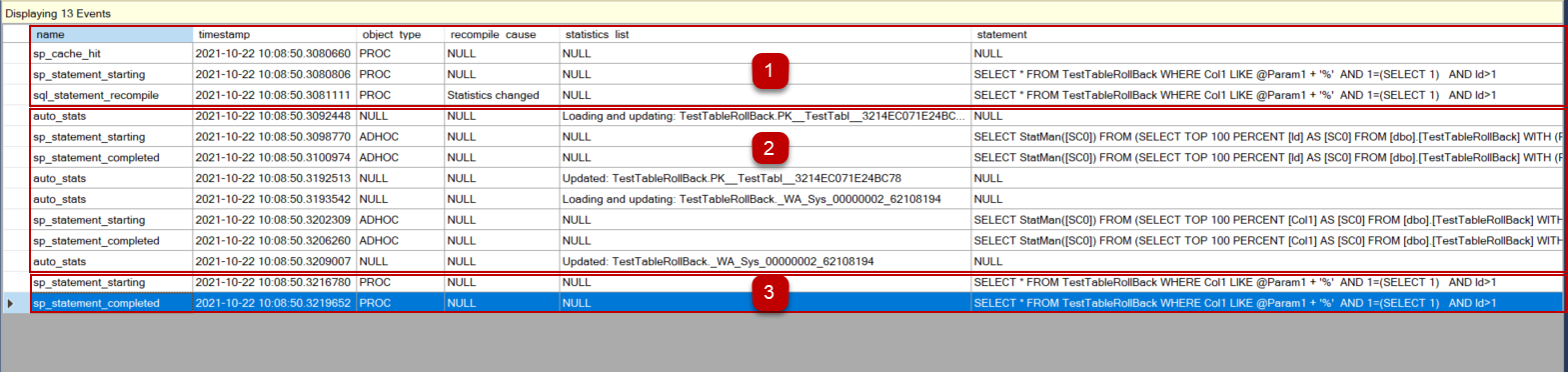
We can separate captured events into 3 sections and then interpret them. In the first part, the optimizer finds a cached plan of the procedure and decides to use it but then noticed the statistics are out-of-date. At this point, the optimizer begins to recompile the stored procedure because of the statistics changing. The second section specifies which statistics are updated. In the last step, the procedure is started to execute and is completed successfully.
Summary
SQL Server statistics are crucial objects for the optimizer to generate more effective query plans. In this article, we deep dove into some less-known points of statistics and explored which activities are occurred behind the scene.
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023