
In this article, we will briefly explain the SUBSTRING function and then focus on performance tips about it.
SQL Server offers various built-in functions and these functions make complicated calculations easier for us. When we use these functions in the SELECT statement, performance impacts are mostly acceptable. However, scalar functions can affect query performances negatively when it uses after the WHERE clauses. The following rule is generally accepted as a performance practice to improve query performances.
- Note: Don’t use scalar-valued functions in the WHERE clause
The main idea behind this principle is, SQL Server can not know the result of the function without executing the scalar function. Therefore, SQL Server must perform the function individually for each row to find qualified data on the execution time. So, the data engine will read the entire index pages or the entire table rows so it causes more I/O activity.
SUBSTRING function is one of the built-in function and that helps to obtain a particular character data of the text data in the queries. This function is widely used by database developers in the queries, for this reason, we will focus on performance details of this function.
Syntax
This is the syntax of the Substring() function – SUBSTRING(string, start, length)
- string: The string expression, from which substring will be obtained
- start: The starting position of the value in which the substring will be extracted
- length: This parameter specifies how many characters will be extracted after the starting position
Now we will make a very straightforward example :
|
1 2 3 |
SELECT SUBSTRING('SAVE THE GREEN',6,3) |
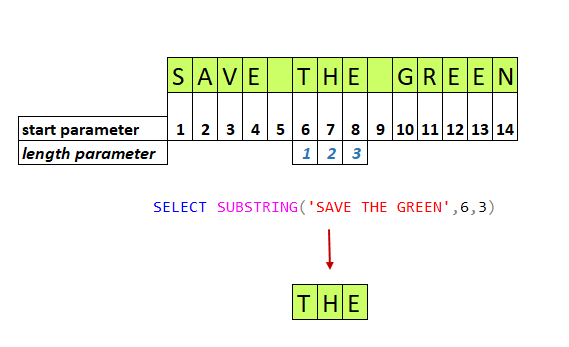
The following illustration represents how this function works for the above example.
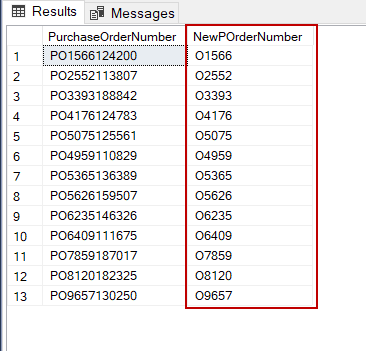
This function also can be implemented with the SELECT statement that retrieves data from the tables. The following query returns a certain part of the PurchaseOrderNumber column values. In this usage of the SUBSTRING function, it starts to extract from the second character of the column values and continues until the seventh character. So that it extracts five characters as we specified in the length parameter of the function.
|
1 2 3 4 5 |
SELECT PurchaseOrderNumber, SUBSTRING(PurchaseOrderNumber, 2, 5) AS NewPOrderNumber FROM Sales.SalesOrderHeader WHERE SalesOrderID BETWEEN 43682 AND 43694 |
You can direct to this article, Substring function overview to learn more interesting facts about the Substring() function.
Now, let’s talk about the performance details of this function.
Prerequisites
In the following examples, we will use the AdventureWorks sample database and use an enlarging script (Create Enlarged AdventureWorks Tables ) which helps to create a large amount of data. When we execute this script it will create the SalesOrderDetailEnlarged and SalesOrderHeaderEnlarged tables under the Sales schema.

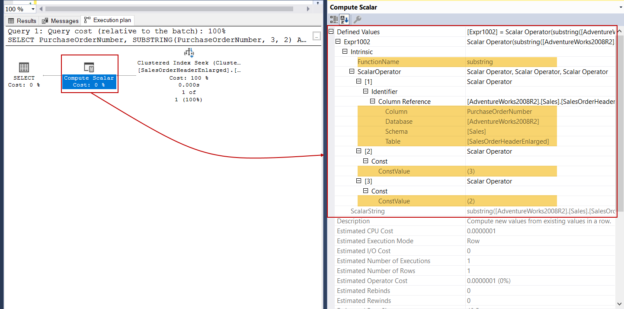
Compute Scalar Operator
Compute scalar operator performs computation and returns the value of this computation. This operator represented with the following image on the execution plans. The property detail of this operator gives detailed information about the performed function to us.

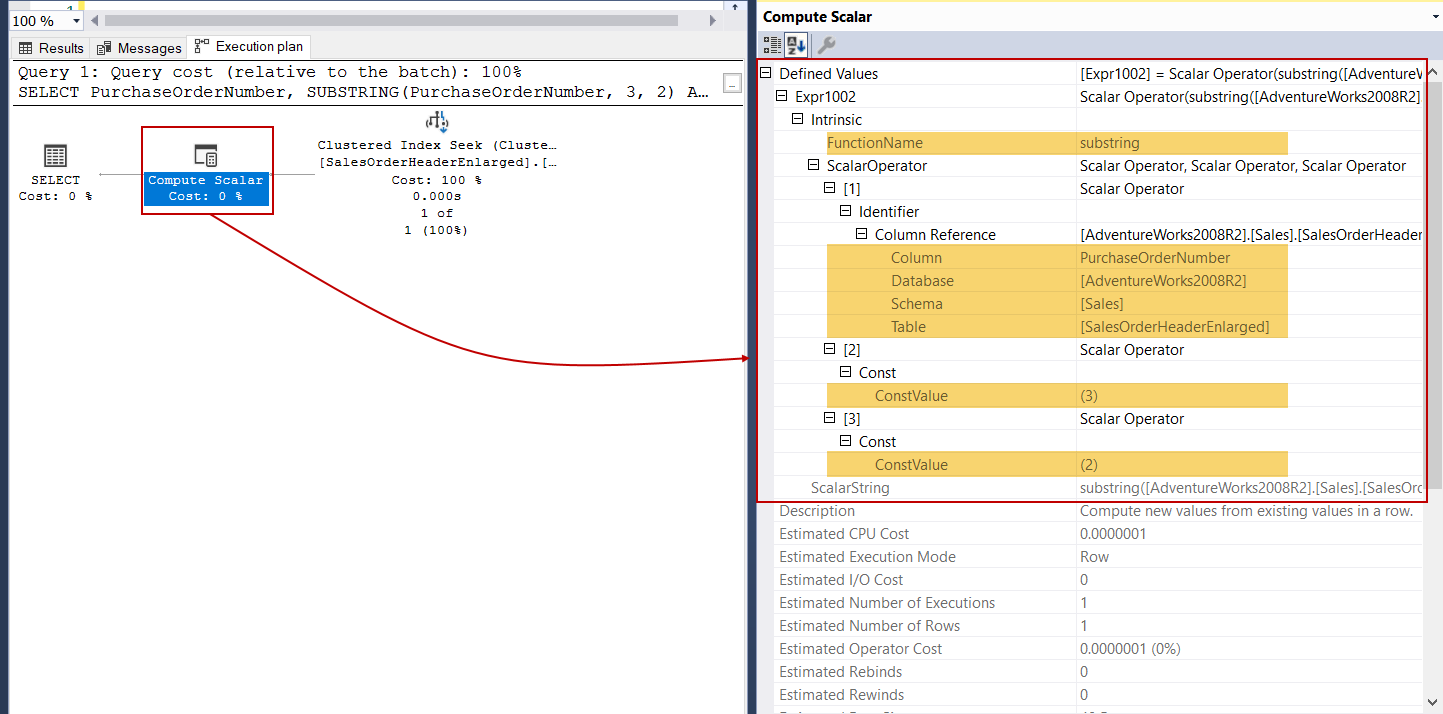
Now we will execute the following query and analyze the property details of the compute scalar operator. Defined Values subattribute shows every detail about the performed scalar-valued function for the following query on the execution plan.
|
1 2 3 4 5 |
SELECT PurchaseOrderNumber, SUBSTRING(PurchaseOrderNumber, 3, 2) AS NewPOrderNumber FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID = 43682 |
The LEFT function extracts the given character starting from the left side of the input string. Now we will execute the following query that includes the LEFT function and analyze the execution plan.
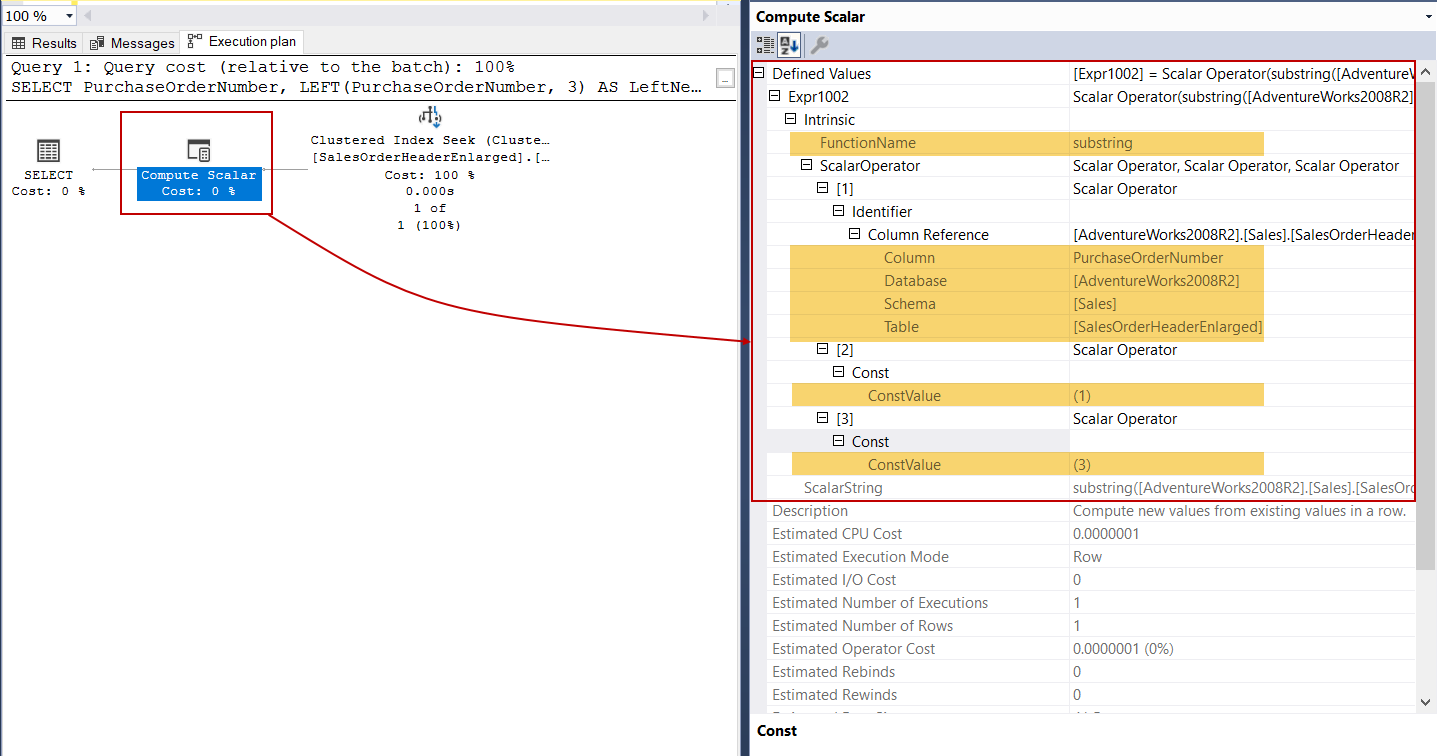
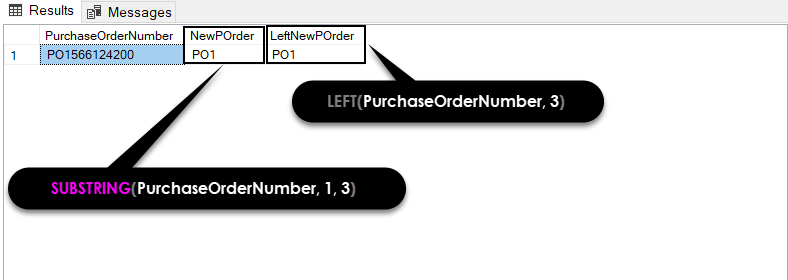
As we can see clearly, the LEFT function is an implementation of the SUBSTRING function. Obviously, using the SUBSTRING function to compute the LEFT function is a very logical approach. For example, the following two functions will return the same values.
|
1 2 3 4 5 6 7 |
SELECT PurchaseOrderNumber, SUBSTRING(PurchaseOrderNumber, 1, 3) AS NewPOrder, LEFT(PurchaseOrderNumber, 3) AS LeftNewPOrder FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID = 43682 |
The RIGHT function performs the opposite of the LEFT function and it extracts the given character starting from the right side of the input string. However, it doesn’t use the SUBSTRING function on its calculations. Now we will execute the following query and analyze the execution plan.
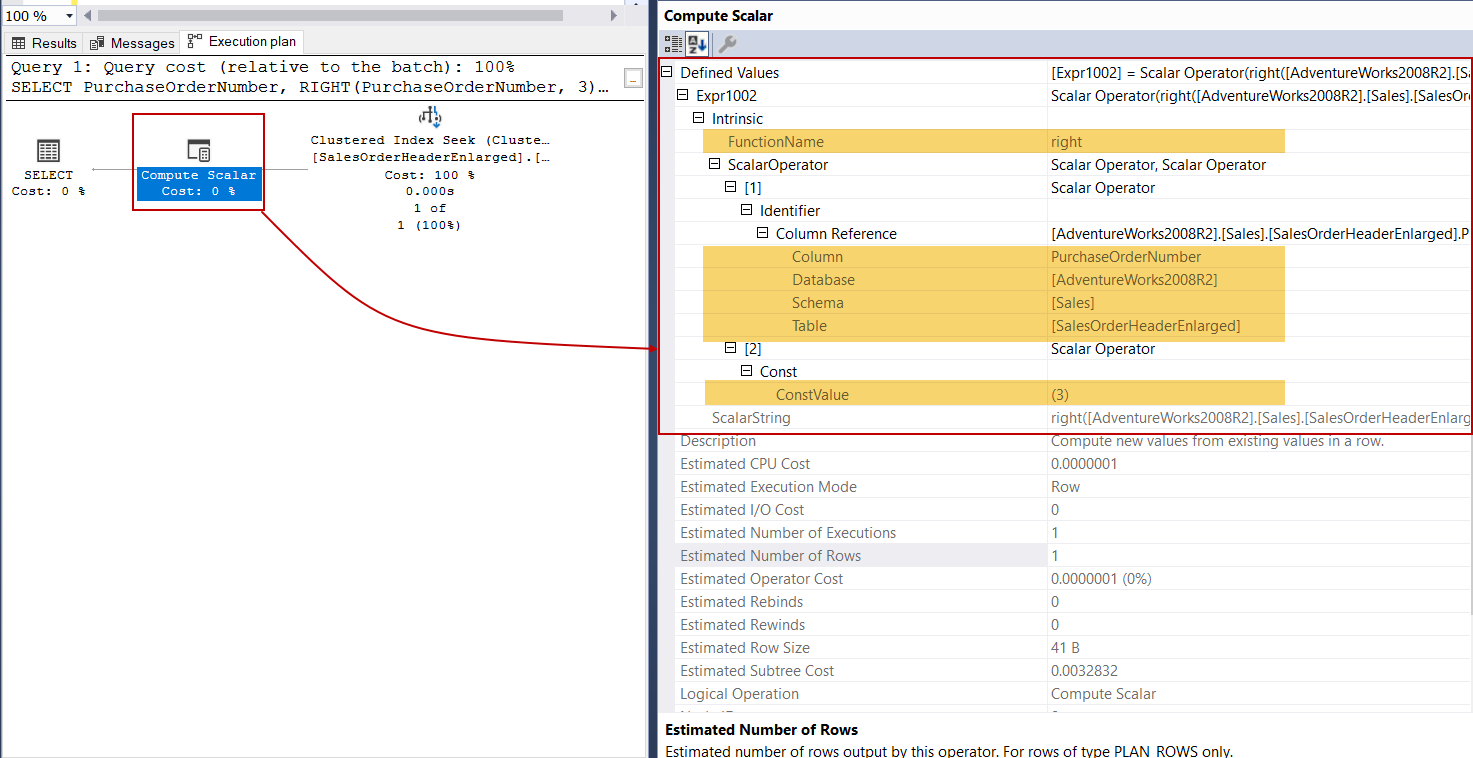
This execution plan has shown us that the RIGHT function characteristic differs from the LEFT function because the FunctionName property indicates the right value.
How to improve the performance of the SUBSTRING function?
Now, let’s remember and open up the subject that we stated at the beginning of the article about the scalar-valued functions.
- Note: Don’t use scalar-valued functions in the WHERE clause
At first, we will execute the following query and analyze the execution plan carefully.
|
1 2 3 4 |
SELECT AccountNumber, PurchaseOrderNumber FROM Sales.SalesOrderHeaderEnlarged WHERE SUBSTRING(AccountNumber, 4, 4) = '4020' |
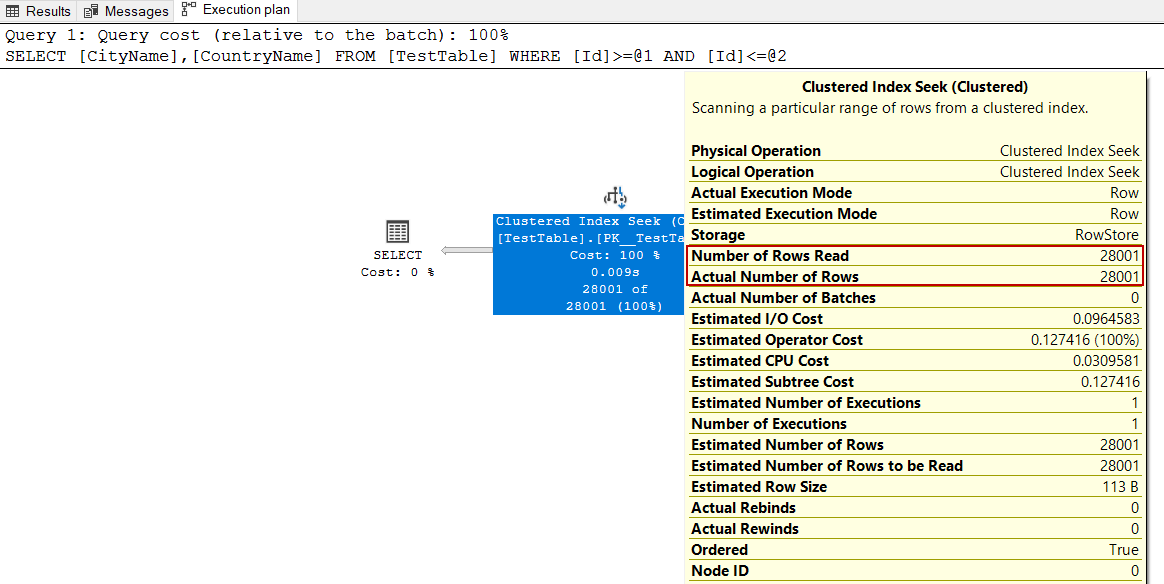
The Number of Rows Read option shows how many rows have been read by the operator and for this example Clustered Index Scan operator has read the whole table and this situation is not a good option for the performance. Actual Number of Rows indicates how many rows transferred to the next operator. For this execution plan, this value is 148434.
When we right-click on the Clustered Index Scan operator and expand the Actual I/O Statistics property and find out the I/O measurement of this operator.
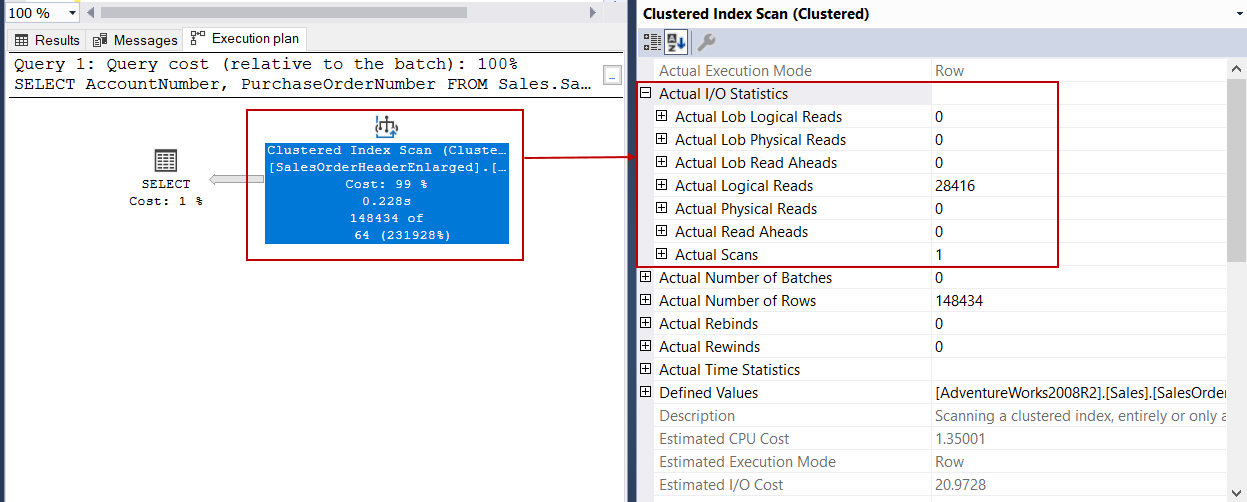
Actual Logical Reads value indicates how many pages read from the buffer pool. Now we will make a very simple calculation for this value:
1 Logical I/O read indicates a reading of a data page and a data page stores 8 kb data. So the total read amount equals 28416*8KB = 227.328 KB and it approximately 227 MB. This amount is not small for a query.
SQL Server does not support function-based indexes so it is a bit complicated to improve the performance of the queries that include scalar-valued function in the WHERE clauses. However, we can create computed columns and create indexes for the computed columns. So that we can improve the performance of these types of queries.
Now we will apply this solution method to our example and observe performance improvement. At first, we will add a computed column to the SalesOrderHeaderEnlarged table.
|
1 2 |
ALTER TABLE Sales.SalesOrderHeaderEnlarged ADD SmallAccountNumber AS SUBSTRING(AccountNumber, 4, 4) |
After the calculated column is created we will replace the SUBSTRING expression with the new computed column after the WHERE clause.
|
1 2 3 4 |
SELECT AccountNumber, PurchaseOrderNumber FROM Sales.SalesOrderHeaderEnlarged WHERE SmallAccountNumber = '4020' |
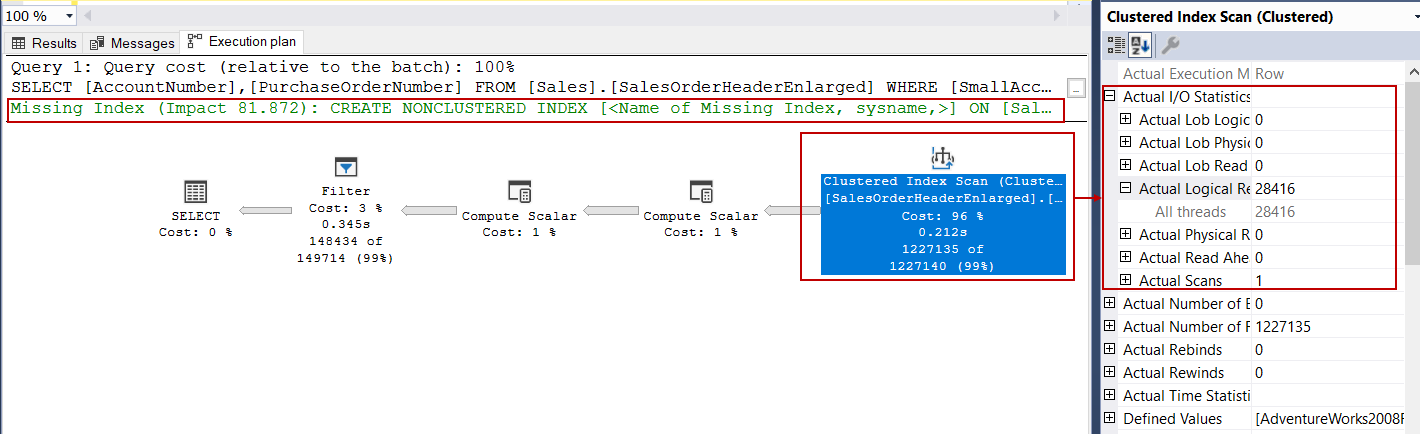
I/O statistics of the Clustered Index Operator do not change but query optimizer surprises us and offers a missing index that can improve the performance query. When we open the details of the index recommendation, it has a very pretentious proposal. Did you notice, the missing index says that this index will increase the performance of the query by 81%. It is worth trying.
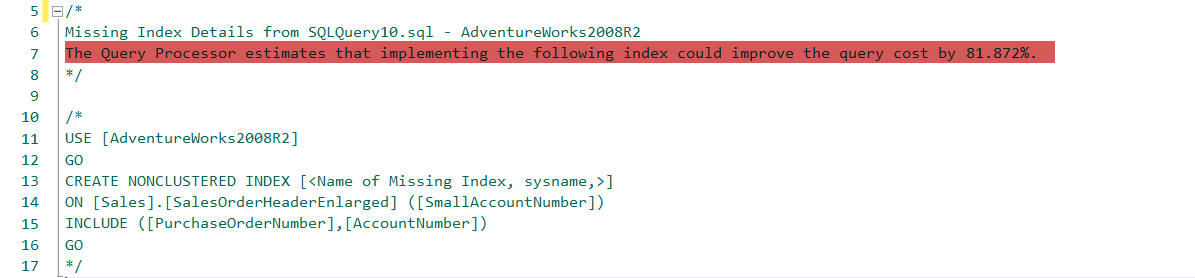
We will give a name to index and create it.
|
1 2 3 |
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeaderEnlarged_SmallAccountNumber] ON [Sales].[SalesOrderHeaderEnlarged] ([SmallAccountNumber]) INCLUDE ([PurchaseOrderNumber],[AccountNumber]) |
Now we will execute the same query after the index creation and analyze the execution plan.
|
1 2 3 4 |
SELECT AccountNumber, PurchaseOrderNumber FROM Sales.SalesOrderHeaderEnlarged WHERE SmallAccountNumber = '4020' |
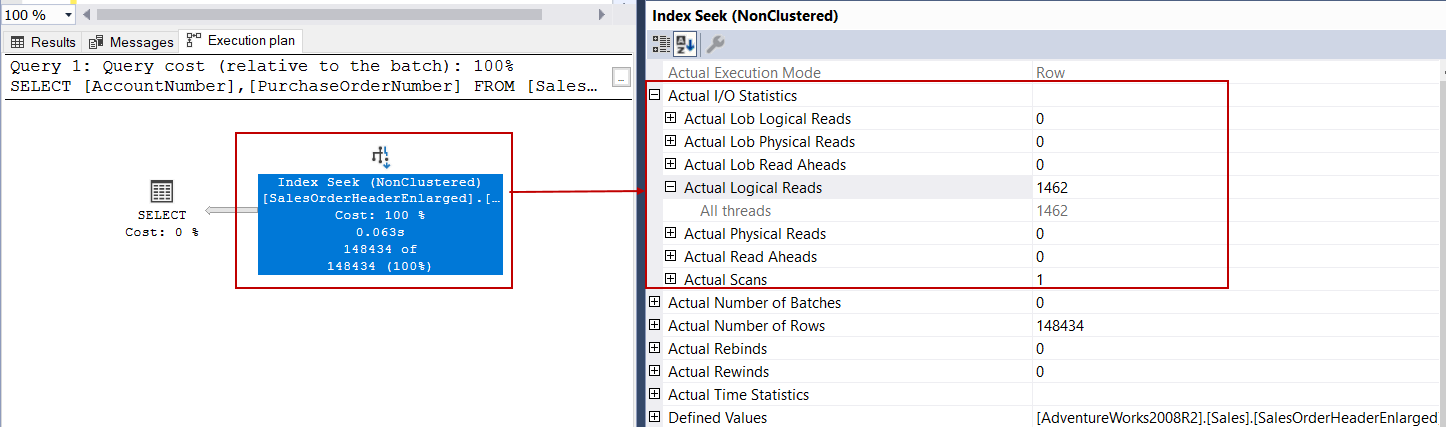
On the above execution plan, the index scan operator has given its place to an index seek operator and it performed only 1462 logical reads. So 1462*8KB = 11,696 KB and it approximately 11 MB. Now we will make a little magic and execute the original query which includes SUBSTRING function and analyze the execution plan.
|
1 2 3 4 |
SELECT AccountNumber, PurchaseOrderNumber FROM Sales.SalesOrderHeaderEnlarged WHERE SUBSTRING(AccountNumber, 4, 4) = '4020' |
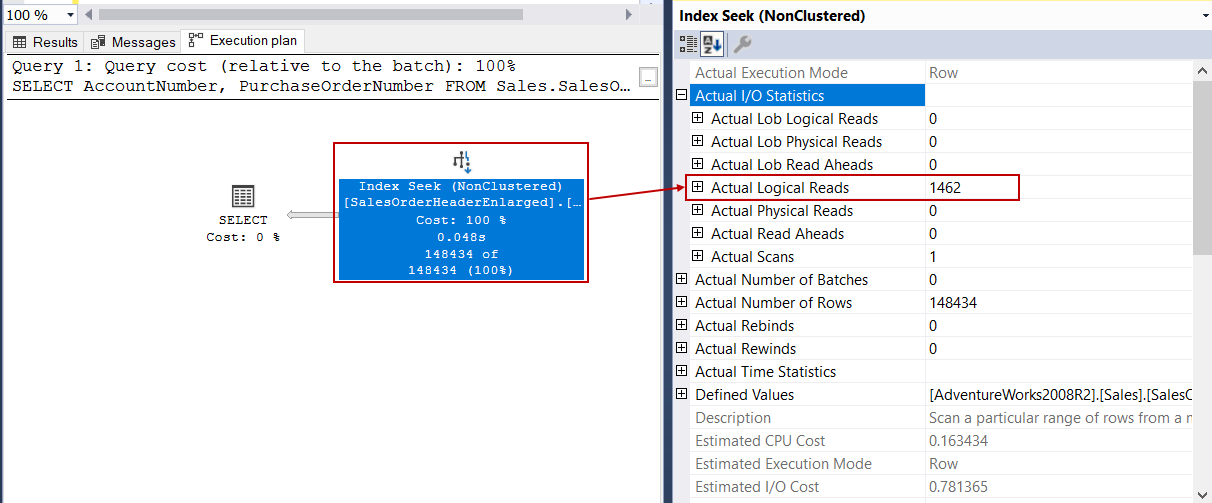
As a result, we understood that adding a computed column and creating an index for this computed column will improve the performance of the queries which are including the SUBSTRING after the WHERE clause. The most important point here is that we can accomplish this performance improvement without any code changing.
Create indexes on computed columns
Creating an index on these columns has some limitations. The first one is determinism. Deterministic functions always return the same when they execute any time with the same parameters. For eg: the GETDATE() is a nondeterministic function, because it always returns different values. Now we will prove this concept.
|
1 2 |
ALTER TABLE Sales.SalesOrderHeaderEnlarged ADD CDateNow AS GETDATE() |
Through the following query, we try to create a non-clustered index for this column.
|
1 2 |
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeaderEnlarged_CDateNow ] ON [Sales].[SalesOrderHeaderEnlarged] (CDateNow ) |

As we can see, the index creation returned an error because of determinism.
The second limitation to create an index on the computed columns is the precision. It means that the computed column’s expression should be precise so the expression must not contain any FLOAT or REAL data types.
We can use the following query to understand which computed column is suitable to create an index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
SELECT object_id, name, definition, CASE is_persisted WHEN 0 THEN 'No' ELSE 'Yes' END AS is_persisted, CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsDeterministic') WHEN 0 THEN 'No' ELSE 'Yes' END AS IsDeterministic, CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsIndexable') WHEN 0 THEN 'No' ELSE 'Yes' END AS IsIndexable, CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsPrecise') WHEN 0 THEN 'No' ELSE 'Yes' END AS IsPrecise FROM sys.computed_columns computed_col WHERE object_id = (SELECT obj.object_id FROM sys.objects obj WHERE obj.name = 'SalesOrderHeaderEnlarged'); |

Conclusion
In this article, we explained the SUBSTRING function usage basics and also learned how to improve the performance of this function if it uses after the WHERE clause. We can create an index on computed columns to improve the performance of queries with scalar functions after the WHERE clause. However, creating an index on the computed columns have some limitations (determinism and precision) and if we want to create an index for the computed columns, these requirements must be met by the computed column.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023