
Working as an Azure Data Engineer, you are responsible for designing and implementing Azure data platform solutions in which you need to choose the best method to ingest structured, semi-structured and unstructured data that are generated from various data sources, in order to be processed in batches or in real-time by the applications and stored or visualized as per the project requirements.
In this article, we will go through the Microsoft Azure Data Factory service that can be used to ingest, copy and transform data generated from various data sources.
Overview
Azure Data Factory is a cloud-managed service that is used to orchestrate the data copying between different relational and non-relational data sources, hosted in the cloud or locally in your datacenters and transforming it to meet the business requirements. It is a big data service that is responsible for the cloud-based Extract, Transform and Load (ETL), Extract, Load and Transform (ELT) and data ingestion processes using scheduled data-driven workflows.
Using Azure Data Factory, you can easily create a workflow in which you connect to a specific on-premises or in the cloud data source, using the 90+ built-in connectors available in Azure Data Factory, transform it using ADF mapping data flow activities, without the need to be skilled in Spark clustering or programming, with the ability to write your own custom transformation code if the required transformation is not available, and finally load the transformed data in a cloud centralized storage to be processed by another analysis or cognitive service or store it directly to relational data sources such as Azure SQL Database or Azure Data Warehouse or non-relational data store such as Azure Cosmos DB to be transformed and processed later.
In Azure Data Factory, you can use Azure Monitor, PowerShell and health tab on the Azure portal to monitor the developed and scheduled workflows status and track any performance or failure issues faced while copying or transforming data.
In addition, Azure Data Factory provides you with the ability to use the Azure DevOps and GitHub repositories in the Continuous Integration and Delivery (CI/CD) of your ETL and ELT workflows while developing it and before it is being published to the production. In other words, it allows you to move it incrementally between the different environments, using the Azure Resource Manager Templates as the configuration storage.
Imagine the effort that you need to spend in developing a custom data movement solution that can perform the data copy and transformation tasks in addition to the complexity and difficulty that you will face while trying to integrate it with other systems and data sources!
Azure Data Factory Components
Azure Data Factory consists of a number of components, that together, allow you to build the data copy, ingestion and transformation workflows. These components include:
- Pipeline: The logical container for the activities that are managed and scheduled to run sequentially or in parallel as a single unit. The pipeline run is an instance of the pipeline execution after passing values to the pipeline parameters
- Activity: A single execution step in the pipeline that is used to ingest, copy or transform the data. A pipeline activity comes in three main types, including data movement, data transformation and control activity
- Mapping Data Flow: A visually designed data transformation logic, requires no coding skills that are executed on a completely managed Spark cluster, and spins up and down based on the workload requirements
- Dataset: A reference to the data in the data source or sink that will be used in the pipeline as an activity input or output
- Linked Service: A descriptive connection string that is used to connect to the data and compute resources that are used in the pipeline activities, in which you will be asked to provide the name of the data source and the credentials that are used to connect to that data source. The information that is required to connect to the data source depends mainly on the type of that data source
- Trigger: The processing unit specifies when the pipeline will be executed. Azure Data Factory supports three main types of triggers: A Schedule trigger that invokes the pipeline on a specific time and frequency, a tumbling window trigger that works on a periodic interval and an Event-based trigger that invokes the pipeline as a response to an event
- Control flow: Pipeline activities orchestration controller that specifies the execution flow of the pipeline, in sequence or parallel, with the ability to define execution branches and loops
Create a New Azure Data Factory
Before creating a new Data Factory that will be used to orchestrate the data copying and transformation, make sure that you have an Azure subscription, and that you are signing in with a user account that is a member of the contributor, owner, or administrator role on the Azure subscription.
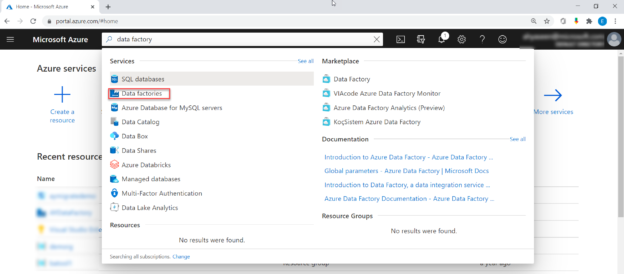
In order to create a new Data Factory, open the Microsoft Azure Portal in your web browser, sign in using an authorized user account, then search for Data Factory in the portal search panel and click on the Data Factories option, as shown below:

In the Data Factories window, click on the + Add option to create a new data factory, as below:

From the Basics tab of the Create Data Factory window, provide the Subscription under which the Azure Data Factory will be created, an existing or a new Resource Group where the ADF will be created, the nearest Azure region for you to host the ADF on it, a unique and indicative name of the Data Factory, and whether to create a V1 or V2 data factory, where it is highly recommended to create a V2 Data Factory to take advantages of the new features and enhancements, as shown below:

In the Git Configuration tab of the Create Data Factory window, you will be asked to configure a repository for your Data Factory CI/CD process, that helps you to incrementally move the changes between the Development and Production environment, where it will ask you whether to configure the Git during the ADF creation or later after creating the Data Factory.
If you plan to configure the Git now, you will be asked to specify whether to use a GitHub or an Azure DevOps repository, the repository name, the branch name and the repository root folder, as shown below:

From the Networking tab of the Create Data Factory window, you need to decide if you will use a Managed VNET for the ADF and the type of the endpoint that will be used for the Data Factory connection, as below:

After configuring the Data Factory network options, click on the Review + Create option to review the selected options before creating the Data Factory, as shown below:

Verify your choices then click on the Create option to start creating the Data Factory, as below:

You can monitor the progress of the Data Factory creation from the Notifications button of the Azure Portal, and a new window will be displayed once the Data Factory created successfully, as shown below:

From the displayed window, click on the Go to Resources button to open the created Data Factory, as shown below:

Now you will see that a new Data Factory is created, with the ability to check the Data Factory essential information, the Azure Data Factory documentation and the pipelines and activities summary under the Overview window.
You can also check different activities performed on the Data Factory under the Activity Log, control the ADF permissions under the Access Control, check and fix the different problems under the Diagnose and Solve Problems, configure the ADF networking, lock the ADF to prevent changes or deletion of the ADF resource and other monitoring, automation and troubleshooting options, as below:

Conclusion
In this article, we provided all the required information to become familiar with the Azure Data Factory and showed how to create a new Data Factory. In the next article, we will see how to use the ADF to move data between different data sources. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021