
Let’s continue the hybrid saga! After two articles talking about the Azure Blob Storage and what we can do using it, it’s time to check an alternative solution, that does the same of what was presented in the last article (a Hybrid Database used as archival solution for who didn’t read). This time we are not using the Azure Blob Storage, but we are still using Azure!
The feature is…Stretch Database
Yes, this is a new feature! So new that is only available in the CTP version of SQL Server 2016. However this is available for download, for free of course, and you can start testing its implementation.
What does this feature do?
Basically the same as we presented in the other article, but with more advantages and an easy way to implement…
In the previous part of this series, we identified a challenge: keep historical data in the database, transparently to the users and applications, without compromise te performance and increase costs.
The solution found was:
Implement table partitioning, pointing the partition with the old data to a file in Azure Blob Storage service.
Advantages:
Transparent, improves the performance in the access to current data and eliminates the physical disk used to store the old data.
Well, that solution works, but there are other points make us thing:
- We need to implement a partitioning logic.
- And we need to maintain this during the database/table lifecycle.
- By default (there are workarounds), the backup will remain the same, and maybe slower as we are accessing the network to read the historical data now.
Those problems are solved if you start using the Stretch Database! Why? I will explain…
The “Stretch Database” is a feature/service based on “Azure SQL Database”, so, no Azure Blob Storage here… When you enable this capability in the database a SQL Database will be created under you Azure subscription.
The first step to start using this, in fact, is enable the feature (of course!), as shown in the next image, right-click in the database, select “Tasks” and “Enable Database for Stretch”:
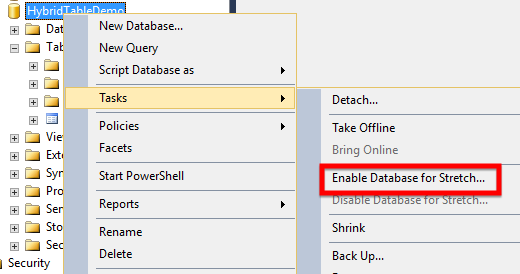
A Wizard will be opened, where you will need to authenticate to you Azure subscription and define the settings of this feature.
There are two possible models:
- Archive Table: Where the entire table will be moved to the cloud.
- Archive Rows: Where only the selected rows will be moved.
The second option, is closer of what we talked in the previous article, anyway, you can do the same of “Archive Table” option using Azure Blob Storage… And it is easier than implement the table partitioning.
Still talking about the “Archive Rows” option, this is still not available in the current CTP, as it is still under development, but the main idea is select the eligible rows to be moved to Azure, based in some define conditions (like a where clause).
All the rows will be moved silently using a retry option, to assure that there’s no data loss. This is true for both options… Oh, this feature is also transparent for the applications and users using the database, which is awesome!
By using this, you may have something like the showed in the following image, for the “Archive Rows” mode:
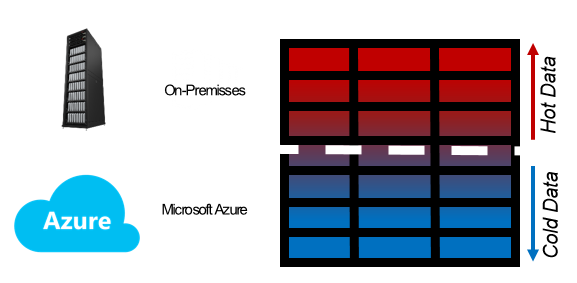
You that read the previous article should be thinking “Ok, but what is the advantage of this feature against the other one?”.
We can start from the basic:
- It is easier to implement, and won’t be changing the physical structure of the database (no extra files and filegroups are needed).
- We won’t need to implement a partitioning logic (no partition scheme, function, etc..).
- There’s a wizard integrated to SQL Server Management Studio that helps us to reach our objective (wizards are always interesting).
- And the best! As we are based in a Azure SQL Database, the database size on-premises will be reduced, reducing backups size and time to complete!
- Because of the same reason, the database maintenance will be improved (comparing time x efficiency).
- All those differences in the database maintenance are automatic, we won’t need to change nothing…
What would I need to have in order to use the Stretch Database feature?
First of all, the very basic: An Azure account, of course 🙂
Having this, we need to enable the “Stretch” in the local instance, using the following code:
|
1 2 3 4 5 6 7 8 |
EXEC sp_configure 'remote data archive' GO_ EXEC sp_configure 'remote data archive', '1' GO_ RECONFIGURE GO |
After that we are good to run the already referred wizard!
I found the official documentation an interesting topic showing some cases were this feature fits… So if you identify yourself with one of those phrases, Stretch Database is for you!
Typical use cases for Stretch Database:
- I need to keep data for a long time.
- I want to find a way to save money on storage.
- The size of my tables is getting out of control.
- I can’t backup or restore such large tables within the SLA.
But be aware that there are some limitations… The following data types are not supported:
- filestream
- timestamp
- sql_variant
- XML
- geometry
- geography
- hierarchyid
- CLR user-defined types (UDTs)
If you have one of the following features, your table won’t be elegible as well:
- Column Set
- Computed Columns
- Check constraints
- Foreign key constraints that reference the table
- Default constraints
- XML indexes
- Full text indexes
- Spatial indexes
- Clustered columnstore indexes
- Indexed views that reference the table
To finalize, I’d like to introduce a “new” tool, that is still under CTP as well, but it works well uf you are planning ahead a migration to SQL Server 2016… When I say “new tool”, is just because it was released in a different way, because in fact the tool is quite old 🙂 I’m talking about SQL Server 2016 Upgrade Advisor!
This new version brought a new interface and “scenarios”, including the Stretch Database. This way, you can analyze your database and find tables that would benefit from the Stretch Database feature. The analysis can be customized, to better fit with your needs.
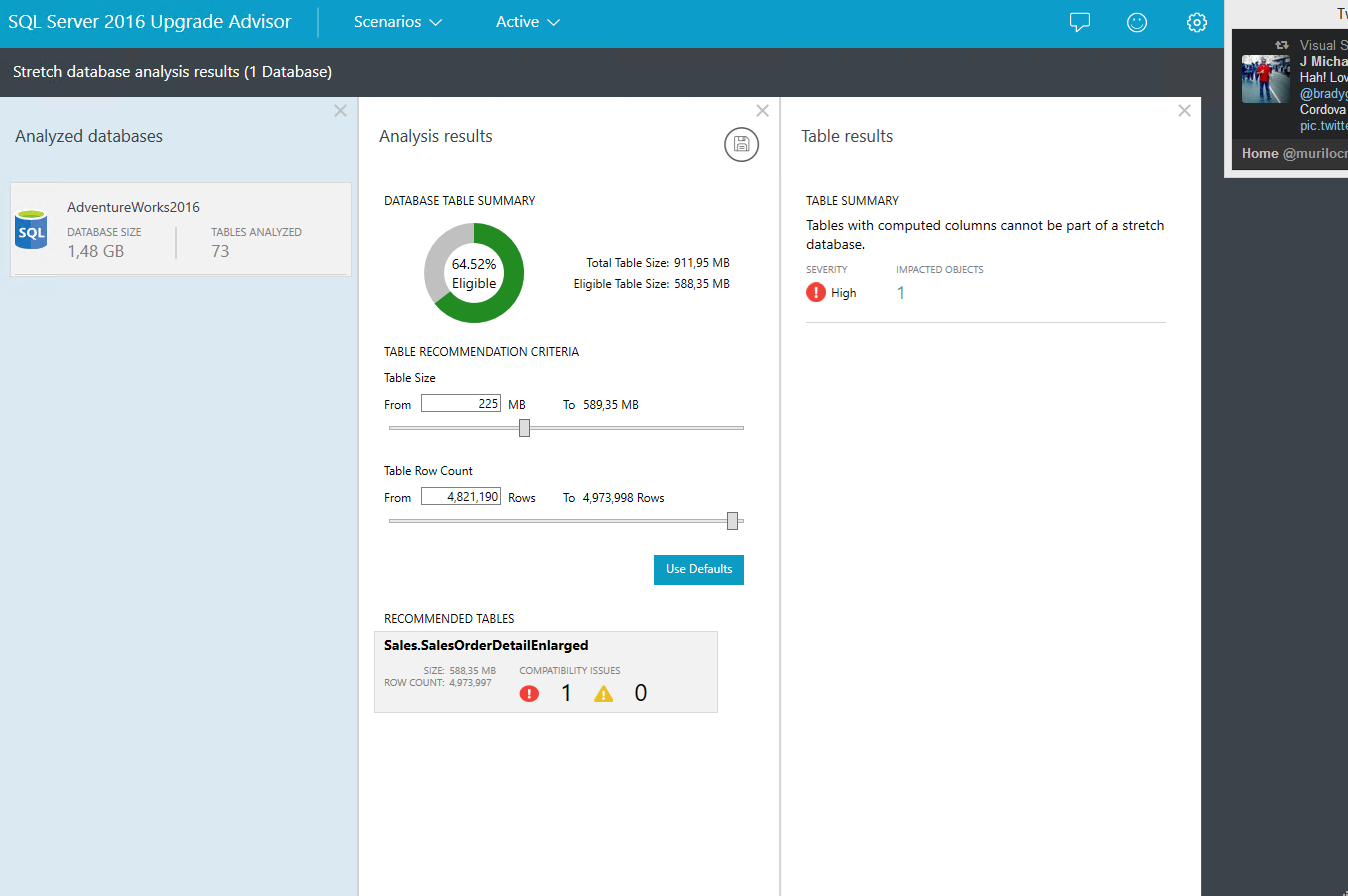
This way we finish one more piece of the Hybrid series, and more is still to come! I hope you enjoyed!

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015